
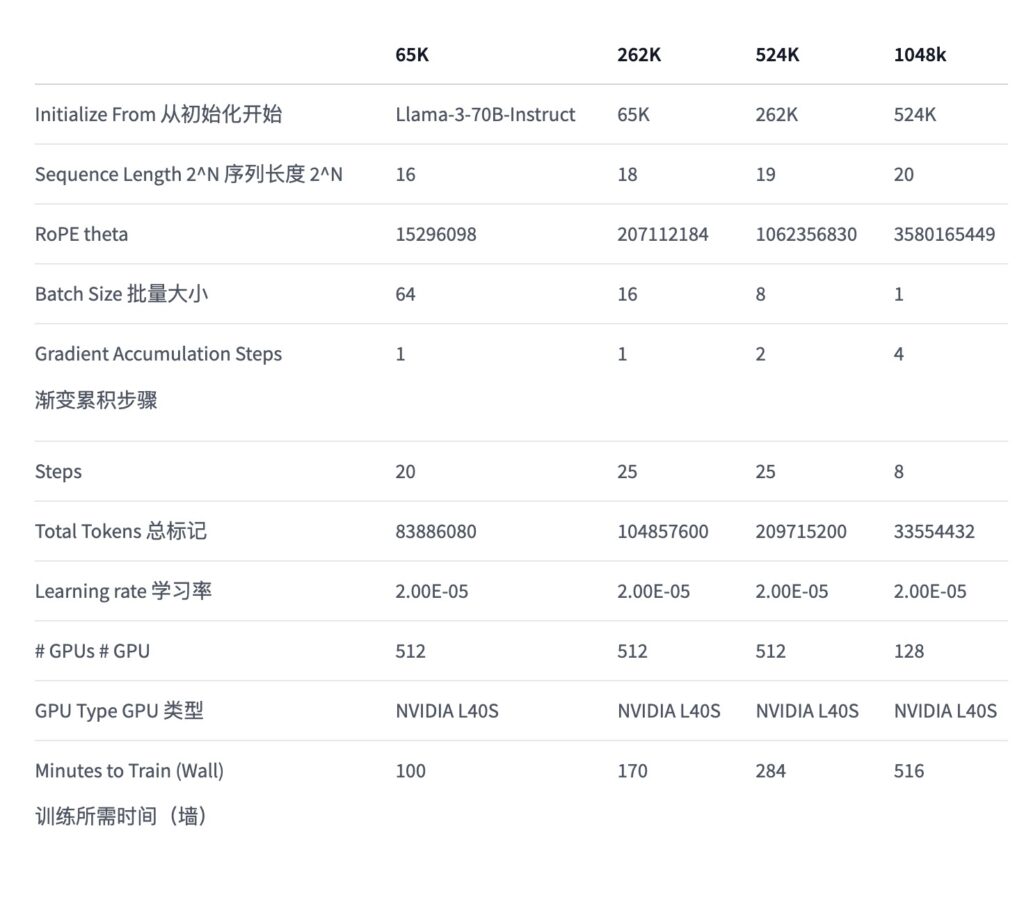
为了逐步适应这种大幅度增加的上下文长度,Gradient AI采用了渐进式训练方法。这意味着模型从较短的序列长度开始训练,逐渐增加到目标长度。这种方法有助于模型逐步学习处理更长文本的策略,而不是一开始就直接面对极大的挑战。
方法概述
-
渐进式训练(Progressive Training):
- 步骤:模型从处理较短的文本序列开始,逐步增加处理的序列长度。这种渐进式增长使模型能够适应在每个步骤中的学习挑战,从而逐步提高处理更长序列的能力。
- 优势:这种方法有助于避免在初期阶段由于序列长度过大而导致的训练困难,保证了训练的稳定性和效率。
-
使用 RingAttention 和 EasyContext Blockwise:
- 技术细节:为了高效管理长序列的计算负担,采用 RingAttention 库优化注意力机制的计算,使其能够扩展到非常长的序列。同时,EasyContext Blockwise 技术被用来分块处理长文本,进一步提高处理速度和降低内存需求。
- 应用效果:这些技术提高了模型在长序列上的训练和推理速度,使得在大规模GPU集群中的部署和执行变得更加高效。
-
NTK-aware 插值和缩放法则:
- 目的:利用神经切线核(NTK)理论优化模型参数的初始化和调整,以适应不同长度的文本处理。
- 实施:通过遵循缩放法则和进行NTK-aware的参数插值,调整模型的RoPE(Rotary Positional Embeddings)theta参数,使模型在不同长度的文本上表现最佳。
训练细节
-
数据处理:
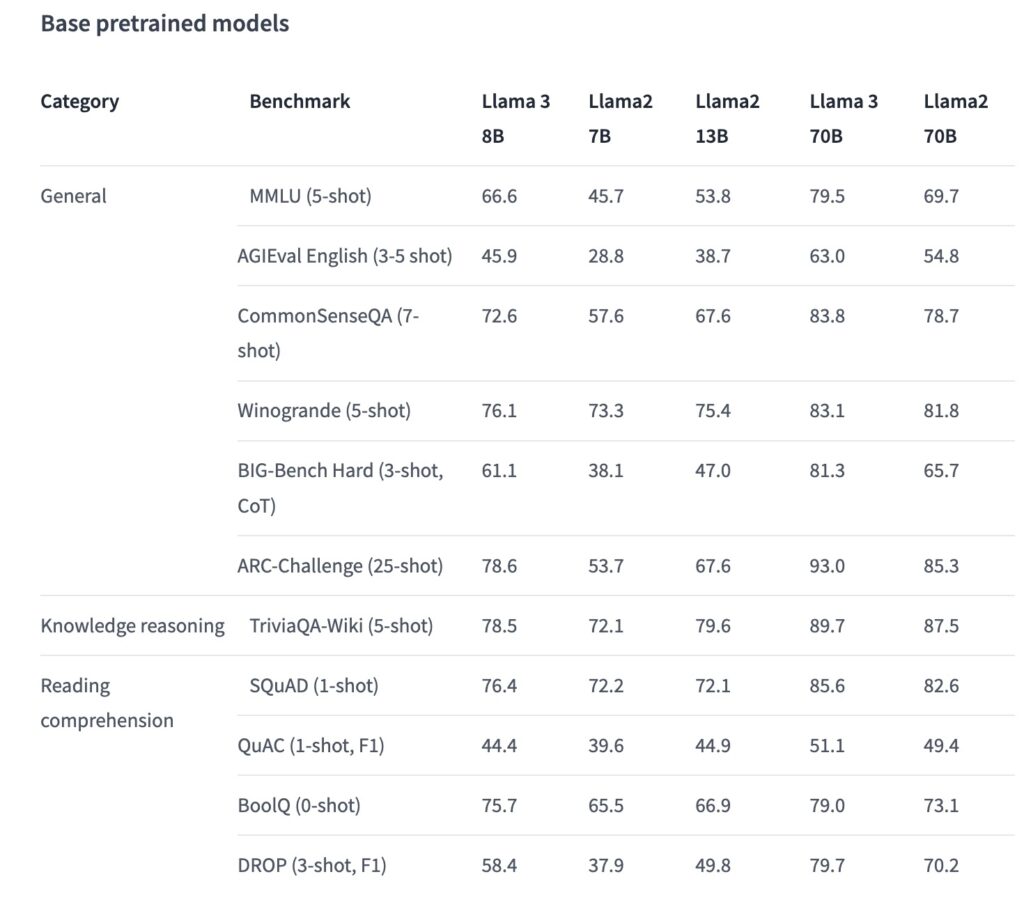
- 数据集:使用了大规模图像-文本配对数据集和纯文本数据集,这些数据集被用来交错训练模型,以平衡视觉和文本信息的处理能力。
- 数据增强:采用数据增强策略来丰富训练数据,提高模型对不同类型文本的适应性和鲁棒性。
-
硬件配置:
- 部署环境:模型在Crusoe Energy的高性能L40S集群上进行训练,这些集群配备了先进的GPU和高速网络连接,以支持大规模并行处理。
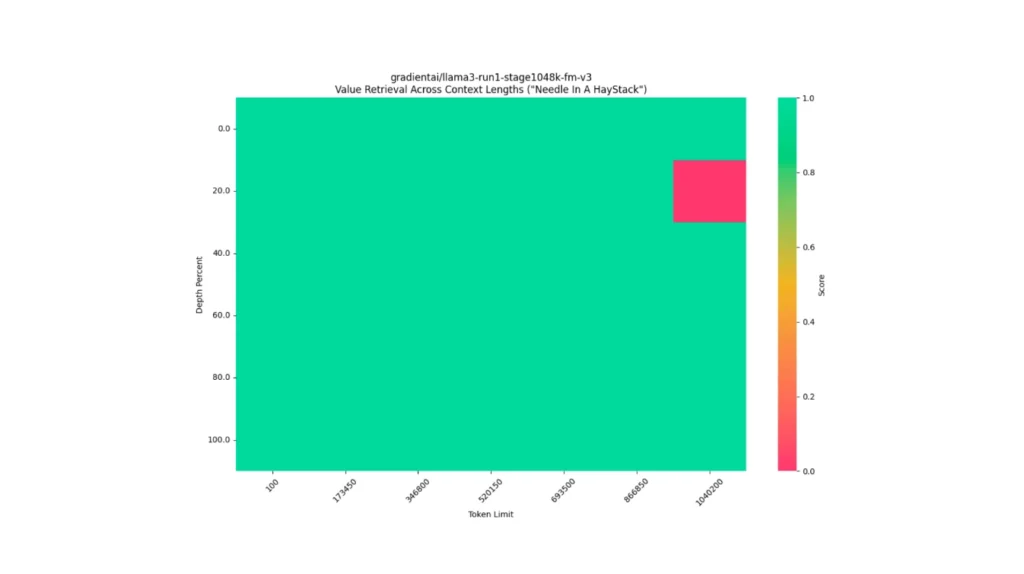
Llama-3-70B-Instruct-Gradient-1048k:https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-1048k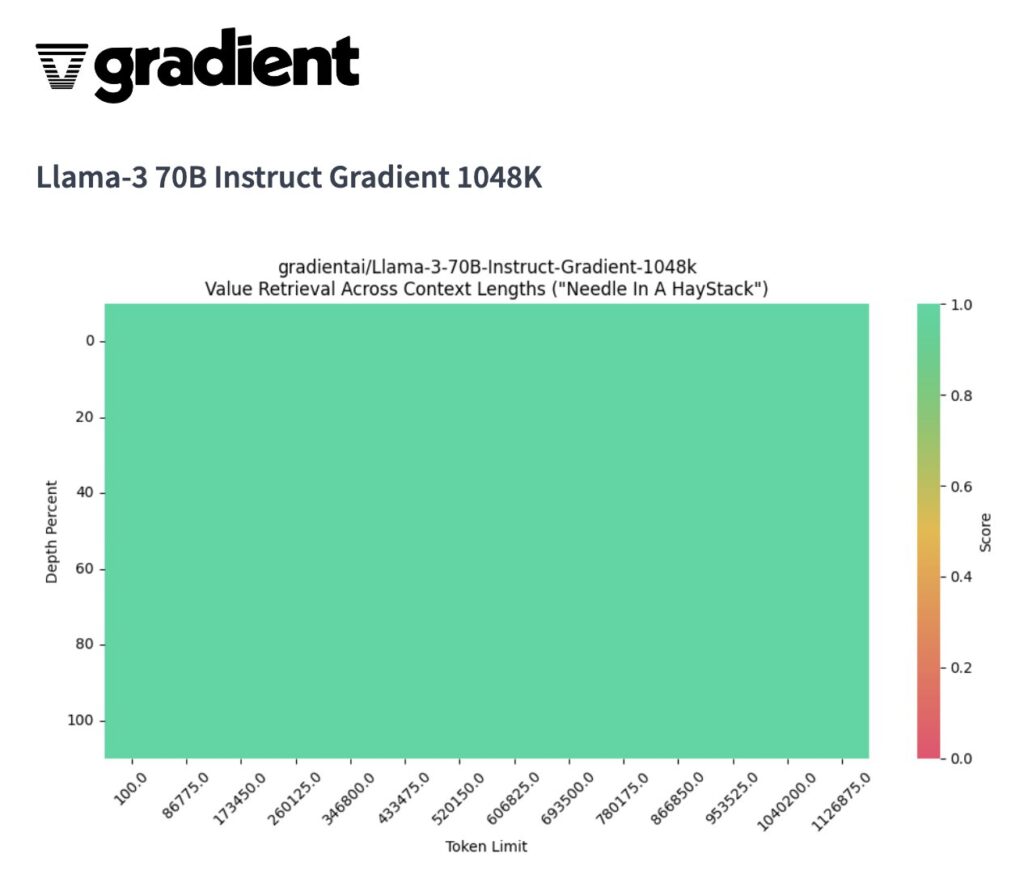
Llama-3-70B-Instruct-Gradient-524k:https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-524k
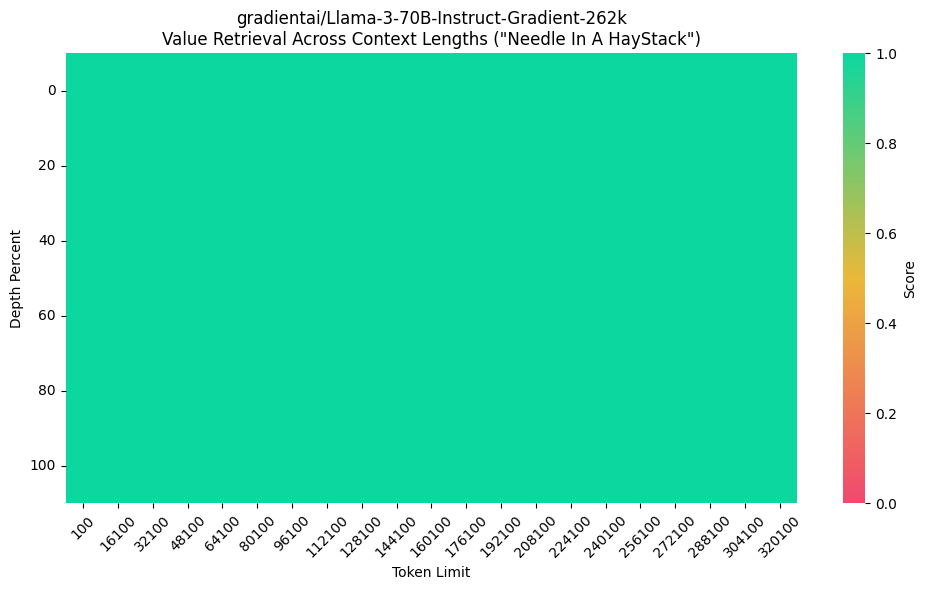
Llama-3-70B-Instruct-Gradient-262k:https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-262k
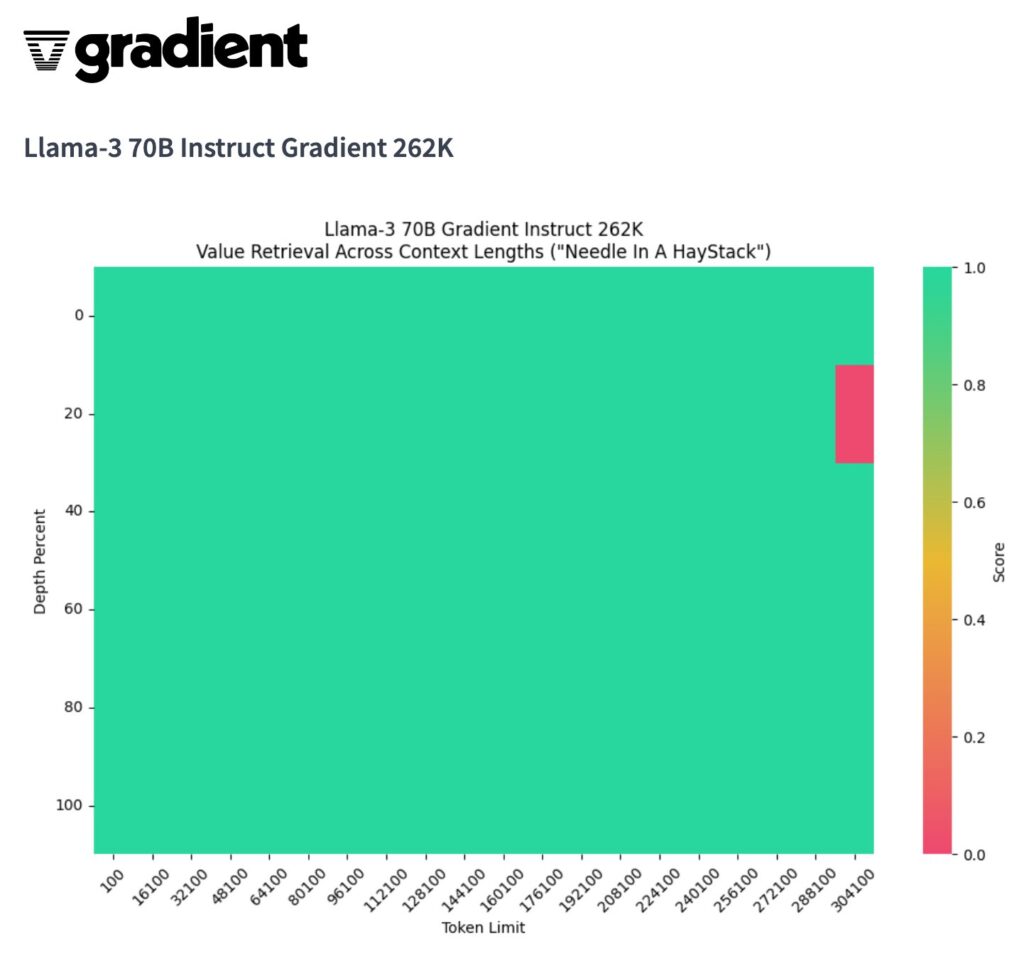
Llama-3-30B-Instruct-Gradient-1048k:https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k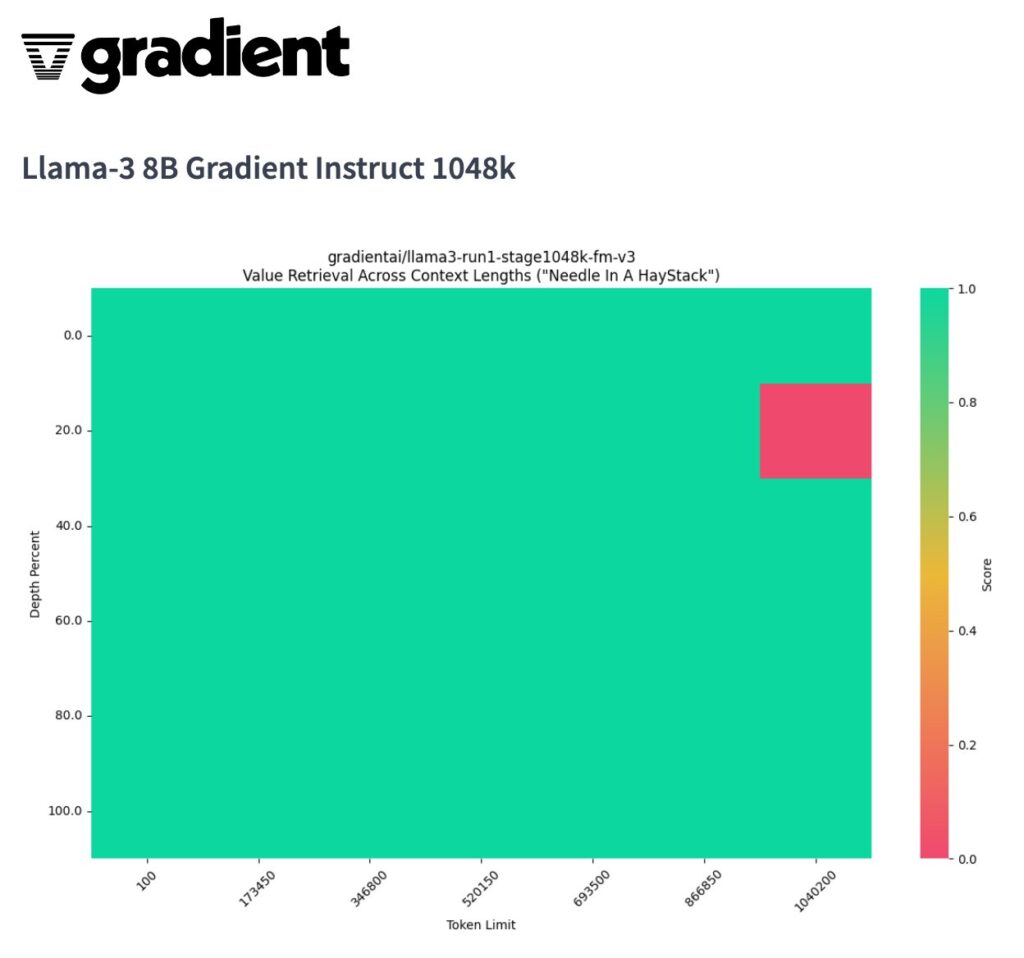
Llama-3-30B-Instruct-Gradient-262k:https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k
BgEraser具有三个主要功能:背景橡皮擦、水印去除器和对象橡皮擦。每个功能都有其自身的优点和用途。