NVIDIA和MIT的研究人员推出了一种新的视觉语言模型(VLM)预训练框架,名为VILA。这个框架旨在通过有效的嵌入对齐和动态神经网络架构,改进语言模型的视觉和文本的学习能力。
VILA通过在大规模数据集如Coyo-700m上进行预训练,采用基于LLaVA模型的不同预训练策略进行测试。
研究人员还引入了视觉指令调整方法,利用视觉语言数据集进行基于提示的指令调整来细化模型。
VILA在视觉问答基准测试中展示了显著的性能提升,例如在OKVQA和TextVQA测试中分别达到了70.7%和78.2%的准确率,同时保留了高达90%的先前学习知识,显著减少了灾难性遗忘的发生。
主要发现
-
情境学习与泛化能力:VILA通过预训练不仅提升了情境学习能力,即模型对新情境的适应性和学习能力,而且还优化了其泛化能力,使模型能在不同的视觉语言任务上展现出色的性能。
-
指令微调的效果:指令微调阶段,通过将文本指令重新混合到图像-文本数据中,VILA能够修复在处理纯文本任务上的性能退化,同时提升视觉语言任务的准确率。
-
视觉问答任务上的表现:VILA模型在视觉问答(VQA)和文本视觉问答(TextVQA)等任务上表现出色,这表明其预训练和微调策略有效地提升了模型的跨模态理解能力。
-
减少灾难性遗忘:VILA成功地减少了在学习新任务时对旧知识的遗忘,这是通过动态调整网络结构和在训练中采用特定策略实现的。
VILA模型主要功能
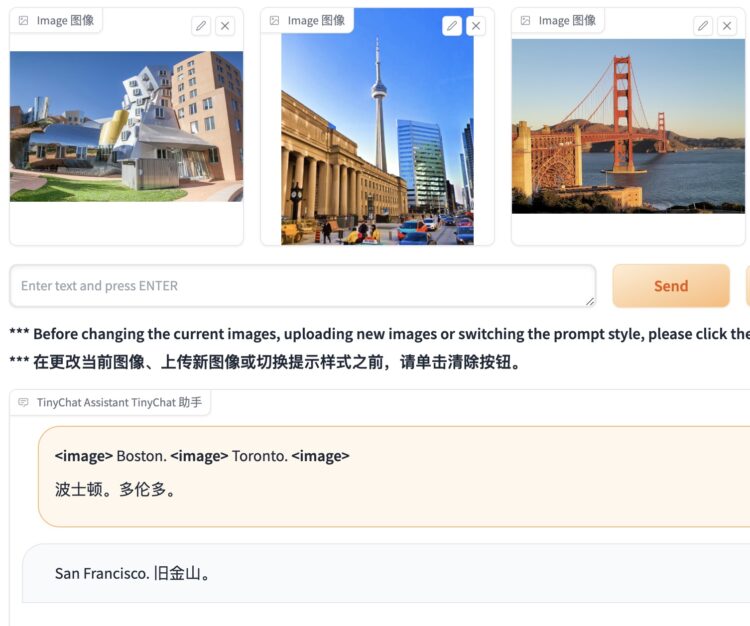
- 多图像推理:VILA模型可以处理并理解多个图像之间的关系,执行复杂的图像间推理任务。这使得模型能够识别和解释多个视觉输入中的模式和联系,如确定图像集中出现的共同对象或主题。

- 增强的情境学习能力:VILA通过预训练改进了情境学习能力,这是模型能够根据给定上下文进行学习和适应的能力。这使得VILA在处理如图像描述、问答等需要理解具体情境的任务时表现出色。


- 更好的世界知识:预训练还帮助VILA模型获得了更广泛的世界知识,使其能够更有效地处理和理解涉及复杂世界信息的查询,如识别著名地标和理解文化特定的元素。
- 文本和视觉的深度融合:VILA在模型的不同层次上融合了文本和视觉信息,实现了更深层次的跨模态信息整合。这包括在预训练阶段使用交错的视觉-语言数据,以及在指令微调阶段整合文本指令和视觉数据。
视频播放器00:0000:00 - 适用于多种视觉语言任务:VILA模型的设计和训练方法使其适用于广泛的视觉语言任务,如视觉问答(VQA)、图像描述生成、图像基础的搜索任务等。模型的多功能性也支持了在少样本和零样本设置下的高性能。
视频播放器00:0000:00
模型架构
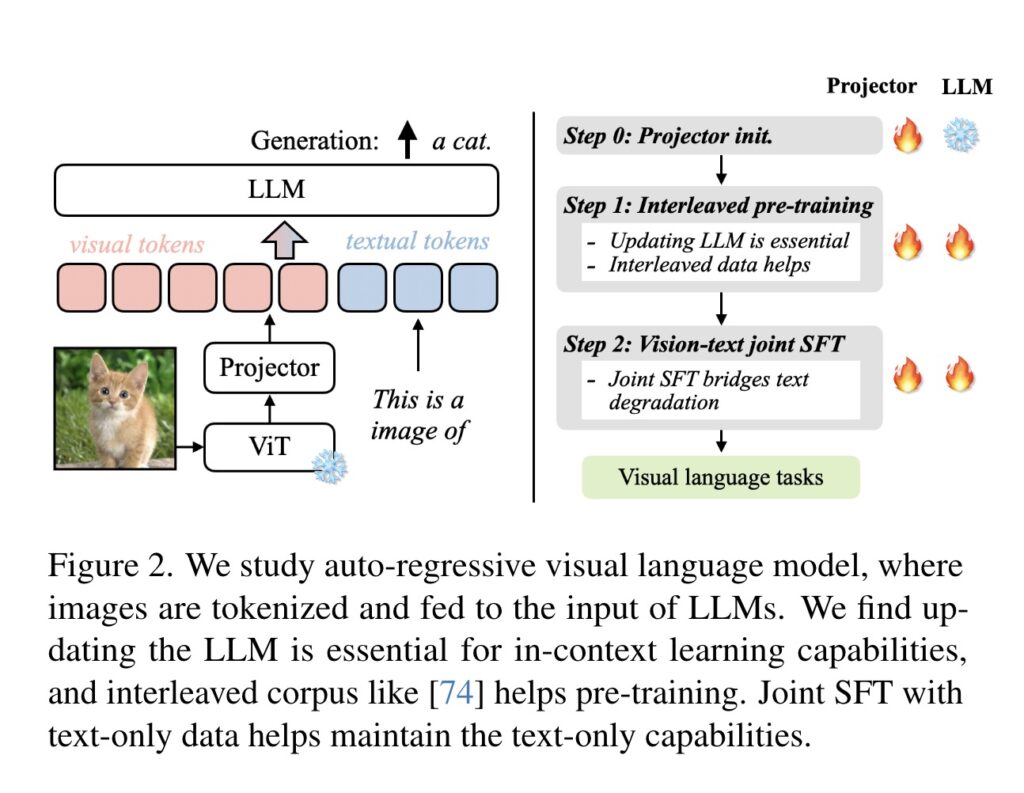
核心特征
-
多模态预训练:VILA模型利用视觉和文本数据的联合预训练来提升模型在理解和生成基于图像的语言描述的能力。这种预训练不仅包括图像和对应文本标签的匹配,还包括复杂的场景解释和问答任务。
-
动态注意力机制:在模型的架构中,动态注意力机制允许模型根据任务需求调整对视觉和文本输入的关注程度。这种灵活的注意力调整对于处理复杂的视觉语言交互尤其关键。
-
交错式训练方法:为了维持模型在处理纯文本任务的能力,同时增强对视觉数据的处理效率,VILA采用了交错式训练方法,轮流对视觉语言数据和纯文本数据进行训练。
-
指令微调:在预训练后,VILA通过针对具体视觉语言任务的指令微调进一步优化性能,如视觉问答和图像描述生成等任务。
组成部分
-
视觉处理单元:VILA模型包括一个专门用于处理图像输入的视觉处理单元,通常基于最新的视觉转换器(如ViT)模型,这些模型被训练用以提取图像中的关键特征和语义信息。
-
语言处理单元:语言处理部分基于先进的语言模型,如GPT或BERT,这些模型专门优化用于理解和生成自然语言。
-
融合层:融合层是VILA模型的核心,它负责整合来自视觉处理单元和语言处理单元的信息,生成统一的、多模态的表示,这对于执行跨模态任务至关重要。
-
优化策略:包括技术如弹性权重共享和梯度截断,这些策略帮助模型在训练过程中保持稳定,并优化跨模态信息的流动。
训练方法
VILA(Visual Language Model)的性能提升主要依赖于一系列创新的预训练方法和架构设计。这些方法和设计特别针对提升视觉语言模型处理跨模态任务的能力,从而在复杂的视觉语言处理任务上达到更好的表现。以下是VILA使用的主要方法和技术细节:
1. 多模态预训练
VILA利用了多模态数据的预训练策略,这是为了增强模型在处理视觉和文本输入时的一致性和效率。具体方法包括:
- 图像-文本配对:通过大量的图像和对应描述的配对数据进行预训练,让模型学习如何理解和关联视觉内容与文本信息。
- 交错视觉-文本数据:在预训练阶段交替使用纯文本数据和视觉-文本数据,这样可以维护并强化模型在处理纯文本内容上的能力,同时增强其对视觉信息的处理能力。
2. 动态网络架构
VILA的网络架构设计允许模型根据任务的需求动态调整,这对于提高模型的灵活性和任务适应性非常关键:
- 动态注意力机制:通过调整注意力机制的聚焦点,模型可以更有效地处理与任务最相关的信息,无论是图像中的细节还是文本中的关键词。
- 嵌入对齐:优化了文本和视觉嵌入的对齐方式,确保两种模态的信息在内部表示上高度一致,这对于后续的信息融合至关重要。
3. 指令微调
通过在微调阶段使用指令微调的方法,VILA能够更精准地适应和执行具体的视觉语言任务:
- 任务特定的指令:在微调过程中,向模型输入具体的任务指令(如“解释这幅图片”或“回答关于这幅图片的问题”),这有助于模型更好地理解和专注于任务需求。
- 视觉-文本联合微调:联合微调图像和文本处理模块,确保两者在执行具体任务时能有效协作。
4. 减少灾难性遗忘
在训练和微调过程中,VILA采取措施减少所谓的灾难性遗忘(即在学习新任务时忘记旧知识的现象):
- 增量学习:采用增量学习方法逐步引入新的任务和数据,避免在快速吸收新知识的同时丢失旧的学习成果。
- 正则化技术:使用正则化技术保持模型在新旧任务之间的平衡,防止过度适应新数据而导致对以前任务的性能下降。
评估结果
VILA在多个视觉语言基准测试中展现了卓越的性能,尤其是在视觉问答和文本视觉问答任务上。这一结果表明,VILA模型的设计和训练策略有效地提升了其在解析和生成基于图像内容的复杂问题答案的能力。
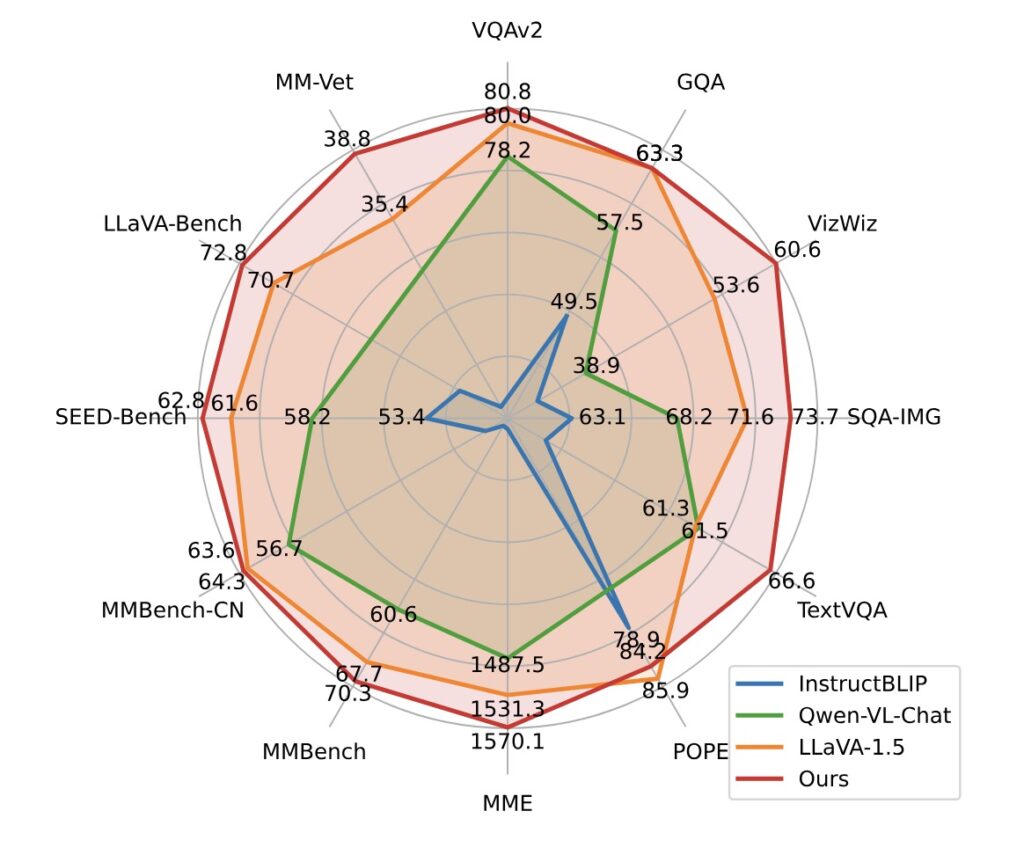
- 数据集和训练阶段:使用包括图像-文本配对和交错图像-文本数据集的大规模数据集进行预训练。实验评估了模型在视觉问答(VQA)和文本视觉问答(TextVQA)等视觉语言任务上的表现。
- 指令微调:通过视觉语言指令数据集进行指令微调,改善了指导微调数据集的多样性和质量,显著提升了下游评估指标。
1. 视觉问答(VQA)任务
- 性能提升:在标准的视觉问答数据集上,VILA显示了优越的性能。具体地,它在OKVQA测试中达到了70.7%的准确率,这是一个涉及开放式问题的复杂数据集,要求模型理解并回答基于图像的各种问题。
- 与其他模型比较:与其他先进的视觉语言模型相比,VILA在处理更复杂、更抽象的查询时显示出更高的准确性和更好的理解深度。
视频播放器00:0000:00
Prompt: Elaborate on the visual and narrative elements of the video in detail.
提示:详细阐述视频的视觉和叙事元素。Caption: The video shows a person’s hands working on a white surface. They are folding a piece of fabric with a checkered pattern in shades of blue and white. The fabric is being folded into a smaller, more compact shape. The person’s fingernails are painted red, and they are wearing a black and red garment. There are also a ruler and a pencil on the surface, suggesting that measurements and precision are involved in the process.
字幕:视频展示了一个人的手在白色表面上工作。他们正在折叠一块带有蓝色和白色格子图案的布料。布料被折叠成更小、更紧凑的形状。这个人的指甲涂成了红色,穿着黑色和红色的衣物。表面上还有一把尺子和一支铅笔�
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Galileo AI,一款功能强大、易用性高、可靠性强的人工智能UI设计工具。