通义千问发布Qwen1.5-110B 首款超1000亿参数模型, Qwen1.5-110B是Qwen1.5系列中的新成员,也是该系列首个拥有超过1000亿参数的模型。
该模型在基础模型评估中表现出色,与Meta-Llama3-70B相媲美,并在聊天模型评估(包括MT-Bench和AlpacaEval 2.0)中表现出色。 模型支持多语言,包括英语、中文、法语、西班牙语等,上下文长度可达32K令牌。
模型特性
- 架构:与其他 Qwen1.5 模型相似,采用 Transformer 解码器架构。
- 独特技术:引入了分组查询注意力(GQA),提高模型服务效率。
- 支持语言:模型仍是多语言的,支持包括英语、中文、法语、西班牙语、德语、俄语、韩语、日语、越南语、阿拉伯语等多种语言。
- 上下文长度:支持32K 令牌的上下文长度。
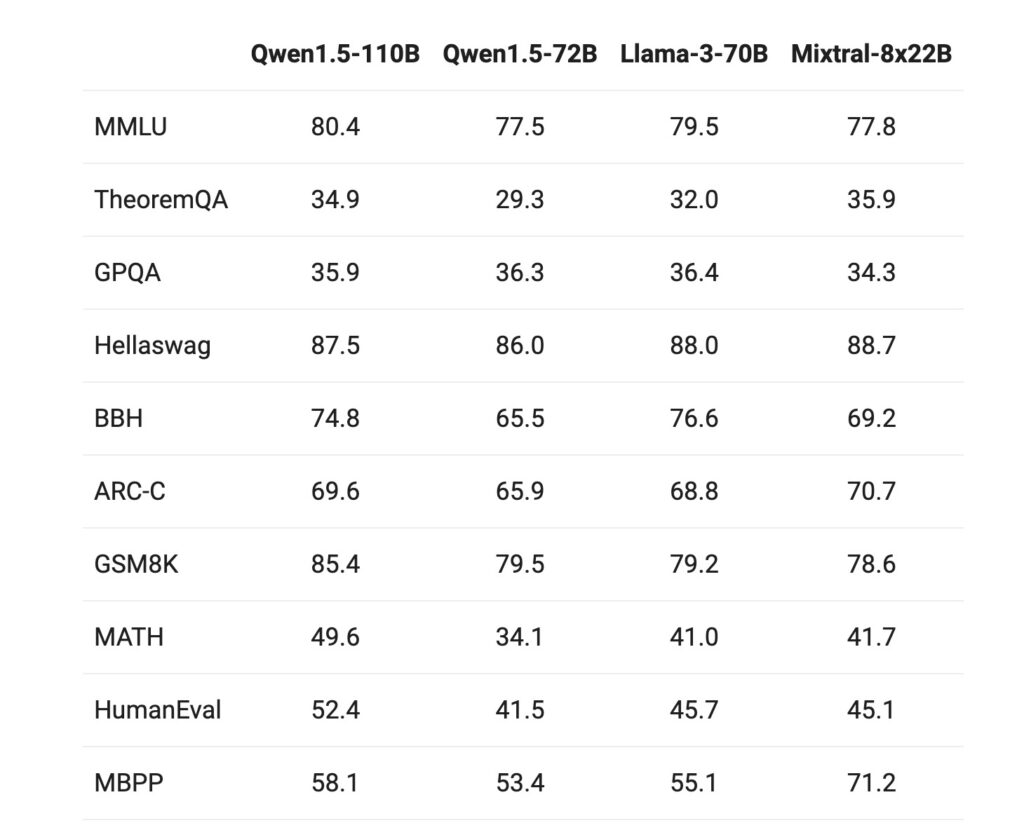
模型质量 Qwen1.5-110B 在基础语言模型的一系列评估中表现突出,与 Meta-Llama3-70B 和其他 SOTA 语言模型(如 Mixtral-8x22B)相比,展现了至少具有竞争力的基础能力。此外,模型的尺寸增加是相对于72B模型性能提升的主要原因。
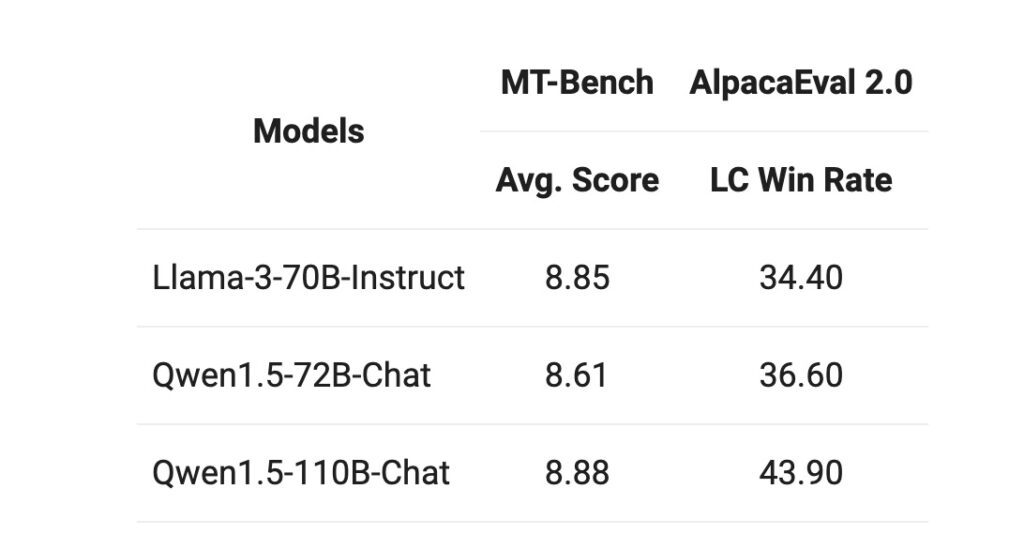
聊天模型评估 在 MT-Bench 和 AlpacaEval 2.0 的聊天模型基准测试中,110B 模型相较于先前发布的 72B 模型有显著改进,持续的评估提升表明,更强大、更大的基础语言模型可以在不过多改变训练后配方的情况下,带来更好的聊天模型。
Qwen1.5是Qwen2的测试版,是一个基于Transformer架构的仅解码器语言模型,预训练在大量数据上。与之前的Qwen模型相比,改进包括:
- 9种模型大小:0.5B、1.8B、4B、7B、14B、32B、72B和110B密集型模型,以及一个14B的MoE模型,激活了2.7B参数;
- 聊天模型的显著性能提升;
- 基础模型和聊天模型都支持多语言;
- 所有大小的模型均稳定支持32K的上下文长度;
- 无需信任远程代码。
详细介绍:https://qwenlm.github.io/zh/blog/qwen1.5-110b/
模型下载:https://huggingface.co/Qwen/Qwen1.5-110B
在线体验:https://huggingface.co/spaces/Qwen/Qwen1.5-110B-Chat-demo
Looka,logo生成器,输入提示词即可生成对应的图标和logo,快速满足你的图标需求。