
ScreenAI 是Google Research开发的一款视觉语言模型,专门针对用户界面(UI)和信息图的理解和交互。它结合了视觉和语言处理技术,旨在改善和加强计算机对于UI和信息图内容的理解能力。解决用户界面和信息图的复杂性和多样化的展示格式的挑战,提升了这些领域的机器理解能力。
该模型在UI和信息图相关任务上取得了最新的成果,并引入了三个新的数据集:Screen Annotation、ScreenQA Short和Complex ScreenQA,以全面评估模型的布局理解能力和问答(QA)能力。
解决什么问题?
- 复杂性和多样性的挑战:用户界面和信息图由于其设计复杂性和展示格式的多样性,给模型理解和交互带来了挑战。
- 信息理解和操作的需求:在人机交互中,需要模型不仅理解视觉元素,如图表、图标和布局,还要根据这些信息执行操作,如回答问题、导航和总结。
有什么功能?
- 布局理解:通过新引入的Screen Annotation数据集评估模型的布局理解能力,即识别和解释屏幕上的各种UI元素和信息图的布局和结构。
- 问答能力:通过ScreenQA Short和Complex ScreenQA数据集,评估模型在解答关于UI和信息图内容的具体问题上的表现。
- 自动标注和数据生成:模型能自动识别和标注用户界面的各种元素,如文本、图像、按钮等,并生成相应的语言描述,这些描述可以用来训练模型进行问答、导航和内容总结。
- 多模态交互:结合视觉和文本输入,处理将图像+文本转换为文本的任务,提升模型在多模态情境下的性能。
- 自我监督学习与微调:模型在自我监督学习阶段自动生成标签,通过大量屏幕截图的分析学习,然后在微调阶段进一步优化,使用人工标注的数据提高准确性和适应性。

任务示例:(a) 屏蔽屏幕注释;(b) 问答;(c) 导航;(d) 总结。后三个任务是使用我们的屏幕注释模型和 PaLM-2-S 生成的。
技术方法
ScreenAI基于PaLI架构,结合了可灵活配置的拼图策略( pix2struct)。它采用多模态编码器块和自回归解码器,可以处理视觉任务,这些任务可以被重新构思为图文到文本的问题。ScreenAI首先利用自动化技术从不同设备上编译大量屏幕截图,然后通过布局注释器和图标分类器对UI元素进行识别和标记。在预训练阶段,模型通过自我监督学习自动生成数据标签,然后进行微调,微调阶段使用的大部分数据由人工评估标注。
1. 模型架构:
- 基础架构:ScreenAI 采用了PaLI(Pathways Language and Image)架构,这是一种结合了 vision transformer(ViT)和多模态编码器的模型。ViT负责创建图像嵌入,而多模态编码器则处理图像和文本嵌入的组合。
- 灵活的拼图策略:引入了pix2struct中的灵活拼图策略,不是使用固定网格,而是选择保持输入图像原始宽高比的网格尺寸,这使得模型能够更好地适应各种宽高比的图像。
2. 数据生成与标注:
- 屏幕截图收集:从多种设备(如桌面、移动设备和平板)上收集大量屏幕截图。
- 布局注释:使用基于DETR模型的布局注释器自动识别和标注屏幕上的UI元素,如图片、图标、按钮和文本,并解析它们的空间关系。
- 图标分类与描述:利用图标分类器识别和分类多达77种不同的图标类型,对于分类器无法覆盖的图标和信息图,使用PaLI图像描述模型生成描述性文本。
- 文本内容提取:应用光学字符识别(OCR)技术提取屏幕上的文本内容,并将这些文本与其他注释结合,形成详细的屏幕描述。
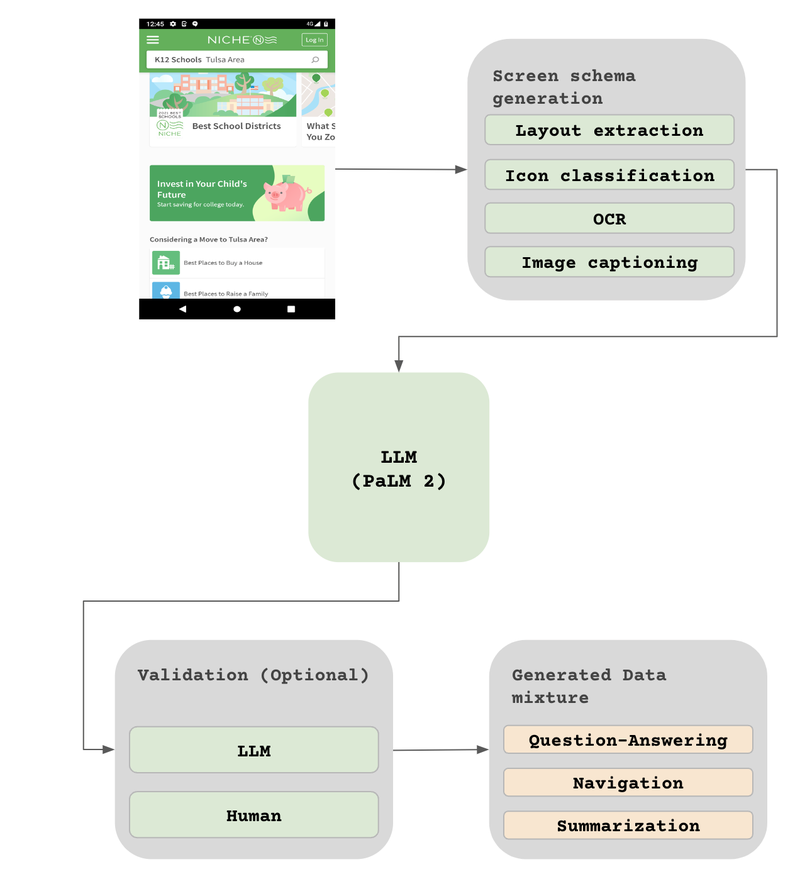
3、基于LLM数据生成
在 ScreenAI 的研究中,大语言模型(LLM)基于的数据生成是一项关键技术,旨在自动化和扩展训练数据的创建过程。这种方法利用大型语言模型的强大处理能力,生成高质量的、结构化的训练数据,特别是针对UI和信息图的问答、导航和摘要任务。以下是该技术的主要内容和特点:
-
数据生成过程:
- 屏幕注释:首先,系统通过自动化工具对收集到的屏幕截图进行详细的注释。这包括识别和标记UI元素如按钮、图标、文本等,并分析它们的空间关系。
- 文本描述生成:利用LLMs,基于屏幕注释信息生成文本描述。这些描述涵盖了界面上的元素类型、位置以及它们的功能和上下文信息。
-
利用LLM生成问答数据:
- 问答对生成:系统通过将注释好的屏幕描述输入LLMs,生成相关的问答对。这些问答对旨在测试和训练模型对屏幕内容的理解和回应能力。
- 迭代优化:生成过程可能包括多次迭代,通过调整生成提示(prompts)和参数来优化问答对的质量和相关性。
-
自动化与规模化:
- 高效率:使用LLMs进行数据生成可以极大地提高数据准备的效率,减少对人工标注的依赖。
- 大规模应用:这种方法支持在大规模上自动生成数据,适用于需要大量训练数据的机器学习项目。
-
质量控制:
- 人工验证:尽管数据生成是自动化的,但生成的数据质量通常通过人工验证来确保,以满足一定的质量标准。
-
应用场景:
- 问答系统训练:生成的问答数据用于训练模型,以更好地理解和回答关于UI界面的具体问题。
- 导航和操作指令:生成的数据还可以帮助模型学习如何根据用户的自然语言指令进行屏幕导航和操作。
- 内容摘要:利用LLM生成的数据还可以训练模型对屏幕内容进行有效摘要。
通过将LLMs 的自然语言功能与结构化模式相结合,模拟了各种用户交互和场景,从而生成合成的现实任务。具体而言,我们生成了三类任务:
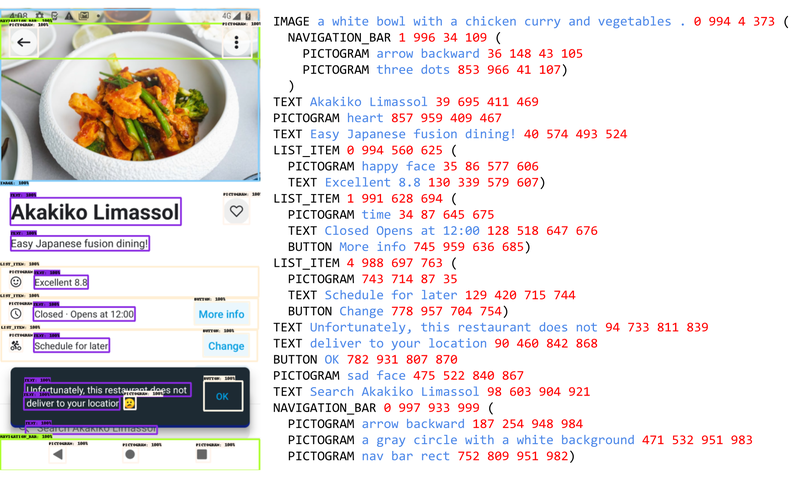
- Question answering: The model is asked to answer questions regarding the content of the screenshots, e.g., “When does the restaurant open?”
问题解答:要求模型回答与截图内容有关的问题,例如 “餐厅什么时候开门? - Screen navigation: The model is asked to convert a natural language utterance into an executable action on a screen, e.g., “Click the search button.”
屏幕导航:要求模型将自然语言语句转换为屏幕上的可执行操作,例如 “点击搜索按钮”。 - Screen summarization: The model is asked to summarize the screen content in one or two sentences.
屏幕摘要:要求模型用一两句话概括屏幕内容。
 LLM-生成数据。屏幕 QA、导航和汇总示例。对于导航,截图中的操作边界框显示为红色。
LLM-生成数据。屏幕 QA、导航和汇总示例。对于导航,截图中的操作边界框显示为红色。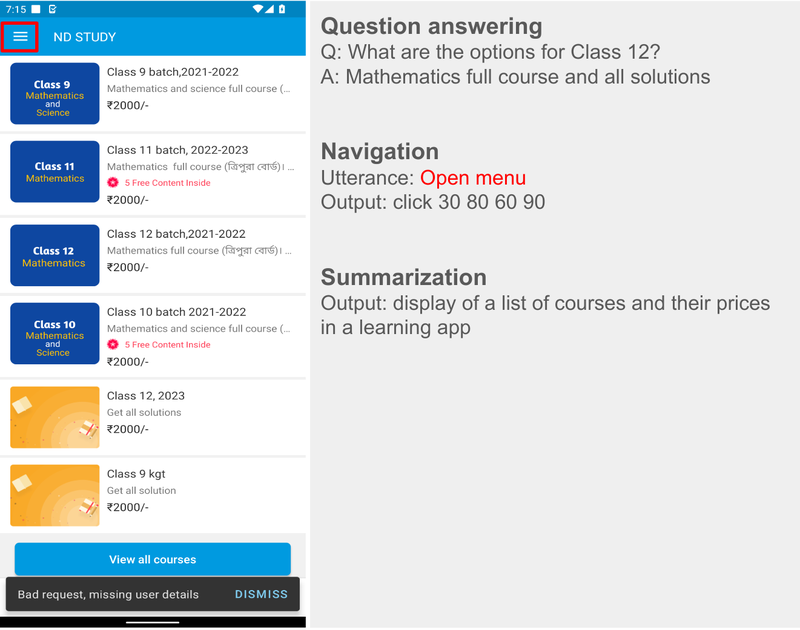
- Question answering: The model is asked to answer questions regarding the content of the screenshots, e.g., “When does the restaurant open?”
4. 训练与微调:
- 自我监督学习:在预训练阶段,模型通过自我监督学习自动生成数据标签,这一阶段主要使用ViT和语言模型进行训练。
- 人工标注数据的微调:在微调阶段,大部分使用的数据由人工标注,此阶段冻结ViT,专注于优化语言模型的性能。
实现的效果:
1. 性能提升:
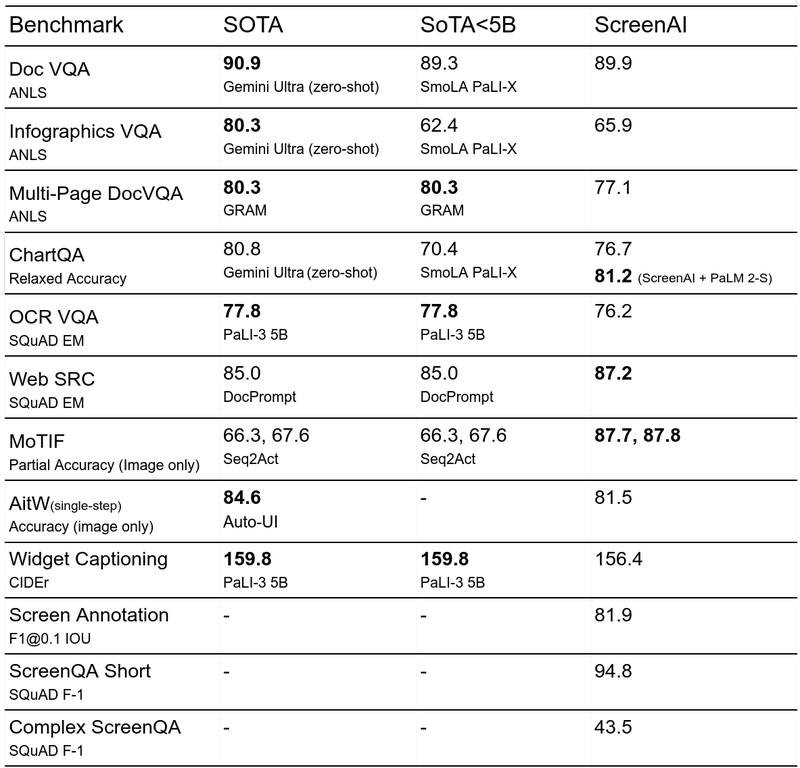
- 在多个公开的信息图问答基准测试中,ScreenAI 显示出超越大型模型(尺寸是其10倍或以上)的最新状态性能。此外,在文档VQA、WebSRC和其他相关任务中,ScreenAI 也展示了一流或接近最佳的性能。
- 在新引入的基准测试(Screen Annotation、ScreenQA Short和Complex ScreenQA)上,模型展示了出色的布局注释和问答能力。
2. 应用多样性:
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Kickresume是一款在线简历和求职信创建工具,已经被全球250万求职者使用。