
Warning: Attempt to read property "child" on null in /var/www/xiaohu.ai/wp-content/plugins/jnews-paywall/class/truncater/class-content-tag.php on line 176
Google DeepMind通过深度强化学习(Deep RL)开发了一个全身控制的框架,使双足机器人能够进行一对一的足球比赛。研究目标是创造能够在真实世界中执行复杂运动技能的机器人,如从摔倒中迅速恢复、行走、转向和踢球等。
通过两阶段的训练方法,机器人不仅学会了基本的运动技能,如起身、行走和踢球,还能根据比赛情境灵活调整战术行为。实验表明,这种方法使机器人在现实环境中的性能显著超过了传统的控制方法,显示出深度学习在复杂运动控制中的巨大潜力。这项研究的成功为未来机器人的实际应用和发展提供了新的方向。
具体方法
-
两阶段训练流程:
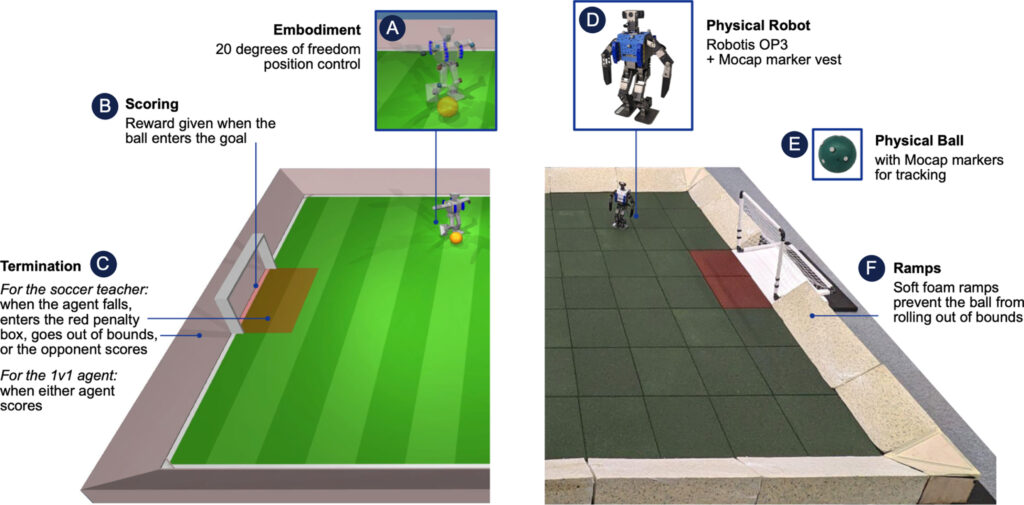
- 第一阶段:技能训练 – 在这一阶段,研究团队首先训练机器人掌握起身和射门等基本技能。这些基本技能是后续训练的基础,帮助机器人在遭遇摔倒等突发情况时能快速恢复,并能在比赛中实施射门。
- 第二阶段:技能融合与自我对抗训练 – 在技能基础上,通过自我对抗的方式进行多智能体训练,这一阶段的目标是让机器人学会将各种技能综合运用,适应一对一的足球比赛场景。在这一阶段,对手智能体是从先前训练中保存的策略快照中随机抽样得到,以模拟真实比赛中的不确定性和对手的多样性。
-
高频控制与动态随机化:
- 高频控制 – 通过高频率更新控制命令来增强机器人的响应速度和运动精度。
- 目标动态随机化 – 在训练过程中引入动态随机化,如随机调整环境参数和机器人感知的噪声,以提高模型的泛化能力和鲁棒性。
-
干扰引入:
- 在训练过程中引入物理干扰(如推搡机器人),使机器人能在接受干扰的情况下保持稳定,增强其在复杂实际环境中的应对能力。
-
策略迁移:
- 将在模拟环境中训练好的策略直接迁移到真实的机器人上,实现从模拟到现实的无缝转换(zero-shot transfer),这一步骤验证了训练策略的实用性和有效性。
主要成果
本研究的主要成果包括以下几点:
-
性能提升显著:与传统的脚本控制器相比,使用深度强化学习训练的机器人在多项关键性能指标上有了显著提升。具体表现为:
- 行走速度提高了181%。
- 转向速度提高了302%。
- 起身时间缩短了63%。
- 踢球速度增加了34%。
-
战术行为的自主学习:机器人不仅掌握了基本的运动技能,还学会了根据比赛的具体情境自主调整战术行为。例如,它能够通过身体防守来挡住对手的射门,或是使用身体保护足球。
-
高度动态的运动技能:机器人表现出了包括快速从地面起身、跑动、转向和踢球等一系列动态的运动技能,并能够在这些技能之间顺畅地过渡。
-
实际应用的可能性:通过高频控制、目标动态随机化和训练中的干扰,研究团队成功地将模拟训练的策略转移到真实的机器人上,展示了这一方法在实际应用中的有效性和潜力。
这些成果不仅证明了深度强化学习在控制复杂机器人行为方面的有效性,也为未来在更广泛的实际应用场景中部署类似技术提供了有力的实验支持。
研究意义
这项研究不仅展示了深度学习在机器人运动控制中的潜力,也为未来开发能在复杂实际环境中自主操作的机器人提供了宝贵的经验和数据。此外,这种训练方法的成功实施也为其他类型的机器人设计提供了可能,特别是在体育运动等需要高度动态和应变能力的场景中。
凌点视频素材网是一家专注于视频素材、A素材模板、影视实拍视频、LED动态背景、动态视觉效果等视频交流学习网站。