
Google发布Gemma 系列的新成员,这是一系列针对开发者和研究者设计的轻量级、最先进的开放模型,建立在创造 Gemini 模型相同的研究和技术基础之上。
新推出的模型包括 CodeGemma 和 RecurrentGemma,旨在为机器学习(ML)开发者提供更多负责任创新的可能性。
- CodeGemma:专注于代码完成和代码生成任务,以及遵循指令的交互。CodeGemma 提供了 7B 预训练的变体,专门用于代码完成和代码生成任务,7B 指令调优变体用于代码聊天和遵循指令,以及一个 2B 预训练的快速代码完成变体,适用于本地计算机。它的主要优点包括智能的代码完成和生成、提高准确性、多语言能力和简化的工作流程。
- RecurrentGemma:一个为研究实验优化的高效架构,利用循环神经网络和局部注意力来提高内存效率。尽管与 Gemma 2B 模型有类似的基准分数性能,RecurrentGemma 的独特架构带来了几个优点,包括降低内存使用、提高吞吐量和推动研究创新。
CodeGemma
CodeGemma,包括7B预训练(PT)和指令调优(IT)变体,以及专为延迟敏感环境设计的2B状态最先进的代码完成模型。
模型架构: CodeGemma模型基于Google DeepMind的Gemma模型家族,继承了其架构和预训练方法。CodeGemma模型通过在超过5000亿个主要由代码组成的token上进行进一步训练,加深了对代码和自然语言处理的理解和生成能力。这些模型使用与Gemma相同的架构,但针对代码生成和理解进行了优化和调整。
- 预训练(PT)与指令调优(IT):**CodeGemma提供了预训练和指令调优变体,7B模型涵盖了广泛的代码和自然语言任务,2B模型则专注于代码填空和开放式生成,适用于延迟敏感的场景。
- 多文件打包:为了提高模型在实际代码项目中的适用性,CodeGemma采用了多文件打包方法,通过构建文件依赖图和采用单元测试基于词汇的打包策略,使模型能够更好地理解和生成涉及多个文件的代码项目。
- 填空中间(FIM)任务训练:CodeGemma模型采用了基于填空中间(FIM)任务的训练方法,该方法通过随机隐藏代码片段中的部分内容来训练模型预测缺失部分,从而提高模型的代码补全和推理能力。
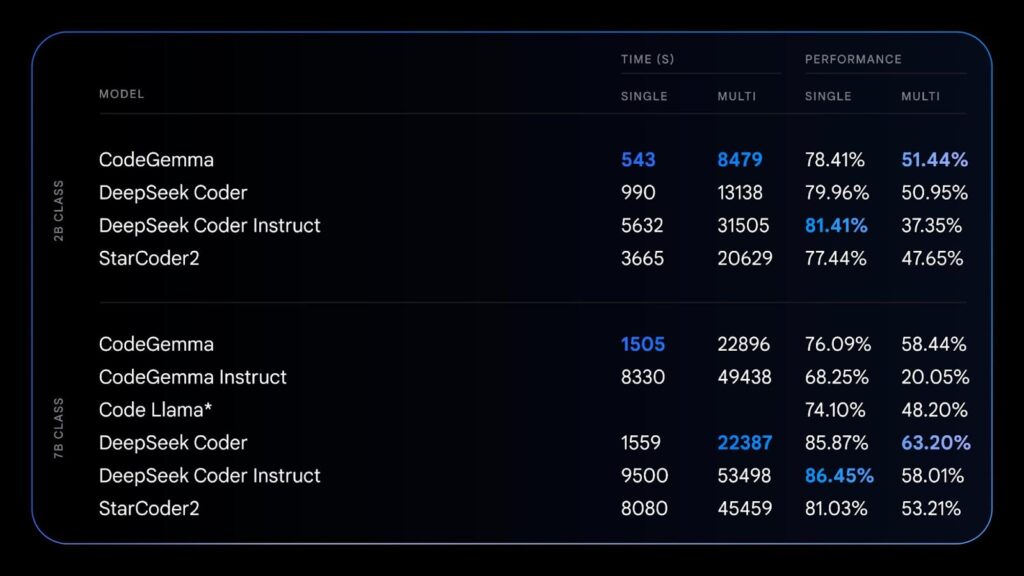
CodeGemma 与其他类似模型在单行和多行代码完成任务方面的性能比较
主要能力:
- 代码生成与补全:CodeGemma在代码生成和补全方面实现了最先进的性能,能够高效处理多种编程语言的代码填空、功能补全、文档字符串生成等任务。CodeGemma 能够完成代码行、函数甚至生成整个代码块,不论是本地工作还是利用云资源。支持 Python、JavaScript、Java 和其他流行语言。
- 数学和逻辑推理:通过在包括数学问题集在内的多样化数据集上进行训练,CodeGemma模型具备了出色的数学和逻辑推理能力,能够解决复杂的数学问题和进行基于逻辑的代码推理。
- 自然语言理解:即使主要针对代码任务,CodeGemma模型仍保留了强大的自然语言理解能力,能够处理复杂的自然语言查询和指令,有效地将自然语言描述转化为代码。
- 实用性与部署考虑:CodeGemma模型考虑了实际使用场景和部署需求,特别是2B模型在保证代码生成质量的同时,优化了推理速度,适合在集成开发环境(IDEs)等延迟敏感的环境中使用。
作用: CodeGemma 主要用于帮助开发者和企业通过自动化编码任务来提高编程效率。它的代码完成和生成能力可以显著减少编码过程中的手工工作量,加快开发速度,同时还能帮助减少错误和提高代码质量。
技术报告:https://storage.googleapis.com/deepmind-media/gemma/codegemma_report.pdf
快速入门:https://ai.google.dev/gemma/docs/codegemma/keras_quickstart
互联网招聘神器