Gemini 1.5 Pro 是由 Google Gemini 团队开发的一款多模态混合专家模型,它标志着人工智能领域的一次重大进步。该模型能够回忆和推理数百万个令牌(tokens)的上下文中的细粒度信息,包括多个长文档、数小时的视频和音频内容。它在跨模态的长上下文检索任务中实现了接近完美的召回率,在长文档问答、长视频问答和长上下文自动语音识别(ASR)等方面提高了现有的最佳性能,达到或超越了 Gemini 1.0 Ultra 在广泛基准测试中的领先性能。
结构概述
- 基础架构: Gemini 1.5 Pro 基于 Transformer 架构,这是一种广泛用于处理序列数据的深度学习模型。它通过自注意力机制(Self-Attention Mechanism)来捕获输入数据之间的复杂关系。
- 混合专家(MoE)模型: 该模型采用了混合专家(MoE)技术,通过将输入数据路由到专门处理特定任务的子网络(即“专家”)来提高计算效率和模型性能。这允许模型在不显著增加计算成本的情况下,大幅增加参数数量。
- 混合专家模型的核心是它的路由机制,该机制决定了对于给定的输入,哪些专家被激活并参与到最终的预测中。这种设计使得模型能够在巨大的参数空间内高效地运行,因为在任何给定时间,只有一小部分专家被激活处理特定的任务。
技术细节
- 稀疏激活: 通过学习路由功能,MoE模型只激活(即使用)对于给定输入最相关的一部分参数,从而在大规模模型中保持高效计算。
- 参数规模: Gemini 1.5 Pro 的总参数数量极大,达到了多亿至数十亿的规模,但由于其稀疏激活特性,每次前向传播过程中只有一小部分参数被激活,这使得模型即便在参数规模巨大的情况下仍保持高效运行。
- 多模态输入处理: 该模型能够处理来自不同模态(文本、图像、视频和音频)的输入数据,并能够在这些不同类型的数据之间建立联系,进行综合理解和推理。
核心能力:
-
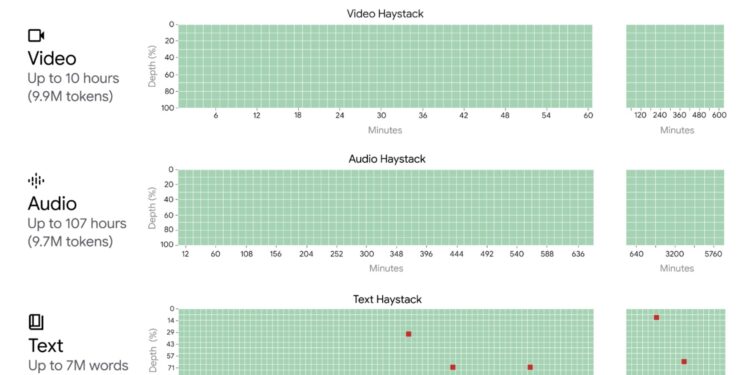
- 长上下文处理能力: Gemini 1.5 Pro 能够处理高达至少1000万个令牌的极长上下文,这是现有大型语言模型所不具备的。这使得模型可以处理整个文档集合、多小时的视频和近五天长的音频。
- 跨模态理解: 该模型不仅能处理文本,还能理解和处理视频与音频信息,实现跨模态的信息融合和推理。
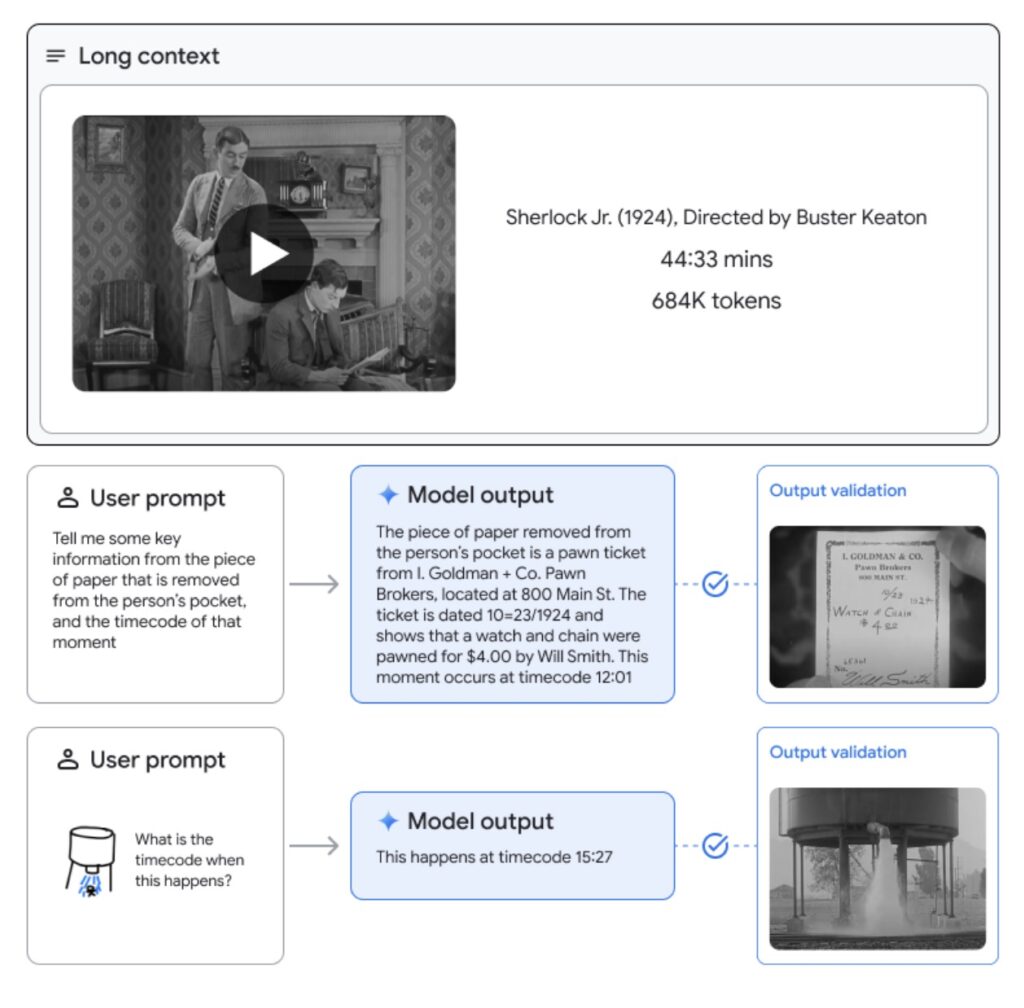
- 近乎完美的信息检索: 在各种模态上,Gemini 1.5 Pro 都能实现超过99%的信息检索召回率,即使是在包含1000万令牌的海量信息中也能准确找到所需数据。
- 学习新语言的能力: 给定语法手册,Gemini 1.5 Pro 能够学习翻译拥有不到200名说话者的罕见语言,表现出与通过同样材料学习的人类相似的翻译能力。
- 优化的模型架构: Gemini 1.5 Pro 采用稀疏混合专家(MoE)的 Transformer 基础模型,实现了在大幅降低训练计算资源需求的同时,保持或超越前代模型的性能。
- 自适应学习和推理: 模型能够基于输入数据的特性动态调整其内部路由和激活的“专家”网络,从而针对不同的任务和数据类型自适应地优化其性能。Gemini 1.5 Pro 在保持高性能的同时,显著降低了资源消耗
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
会读ReadFlow是一款专注于读前筛选的阅读工具,一键转发可以快速获取文章摘要。