
PixelPlayer:MIT的研究团队开发的项目,能自动从视频中识别和分离出不同的声音源,并与画面位置匹配。
例如,它可以识别出视频中哪个人物正在说话或哪个乐器正在被演奏。
而且还能够分别提取和分离这些声音源的声音。
PixelPlayer能自我学习分析,无需人工标注数据。
这种能力为音视频编辑、多媒体内容制作、增强现实应用等领域提供了强大的工具,使得例如独立调整视频中不同声音源音量、去除或增强特定声音源等操作成为可能。
PixelPlayer的核心功能包括:
- 声音源分离:PixelPlayer通过分析视频,能够将声音信号分离成多个组件,每个组件对应于视频中的一个特定区域。这使得系统能够识别和分离视频中的不同声音来源,如不同乐器的声音。例如将一个视频中的人声、乐器声等分离成独立的音轨。
- 声音定位:除了分离声音,PixelPlayer还能定位声音的来源,即确定视频中哪个区域产生了特定的声音。这意味着系统可以识别出声音是来自视频中的哪个具体物体。例如,它可以识别出视频中哪个人物正在说话或哪个乐器正在被演奏。
- 多声音源处理:即使视频中有多个声音源同时发出声音,PixelPlayer也能够分别识别和处理它们。
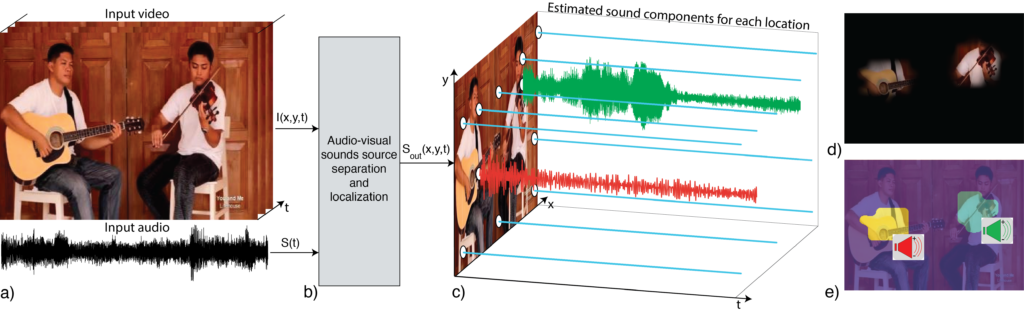
工作原理:
- 大规模视频训练:PixelPlayer系统的训练使用了包含人们演奏不同乐器组合(包括独奏和二重奏)的大量视频。训练过程中没有提供关于视频中存在哪些乐器、它们的位置或它们的声音的信息。
- 数据驱动学习:重要的是,PixelPlayer能够进行这些复杂的分析和处理,而无需人工标注数据。传统的机器学习方法往往依赖于大量的标注数据来教会模型识别和处理信息。相比之下,PixelPlayer通过观看大量的未标记视频,自己学习理解声音和图像之间的关系,实现声音源的分离和定位,这是一种自我学习的能力。
- 视音频同步利用:PixelPlayer依赖于视觉和音频模态之间的自然同步,即声音的产生往往与视觉元素(如人的动作或乐器的演奏)相关联。通过分析这种同步关系,PixelPlayer学习到不同物体或行为所产生的声音特征。
- 声音与像素的关联:系统通过声音和图像的联合分析,为视频中的每个像素分配一个声音成分,实现声音的精确定位和分离。这种方法允许PixelPlayer识别出视频中的哪些区域正在产生声音,并将声音分解成代表每个区域声音的组件。
- 声音分离技术:使用先进的声音处理技术,如源分离算法,将混合的音频信号分离成多个独立的声音通道,每个通道对应于视频中的一个声音源。
应用场景:
- 音视频源分离:PixelPlayer可以自动从视频中分离出各种声音源,如乐器声音。这对于音乐制作和编辑非常有用,允许音频工程师和制作人从复杂的音频录制中分离出单独的乐器声轨,进行更精细的音频处理和混音。
- 声音定位:通过定位视频中产生声音的具体位置,PixelPlayer为增强现实(AR)和虚拟现实(VR)应用提供了新的可能性。在AR/VR环境中,根据用户的视角和互动,逼真地模拟声音来源可以极大增强用户体验。
- AI内容配音:在电影制作、视频游戏开发和在线教育等领域,PixelPlayer能够帮助内容创作者更加容易地为视觉内容配音,例如自动为动画中的不同角色或物体添加特定的声音效果。
- 自动字幕和描述生成:对于听力障碍者,PixelPlayer可以通过识别和分离视频中的声音来源,帮助自动生成更准确的字幕和音频描述,提高视频内容的可访问性。
- 音频可视化:PixelPlayer提供了一种创新的方式来可视化声音和音乐。通过将声音与视觉内容直接关联,可以创造新颖的音乐可视化体验,例如音乐视频中基于乐器位置的动态声音可视化。
- 音乐教学和学习:在音乐教育中,PixelPlayer可以用来展示不同乐器在合奏中的声音分布和特点,帮助学生更好地理解乐曲的结构和乐器之间的互动。
- 研究和开发:作为一个研究项目,The Sound of Pixels推动了跨模态学习(即同时处理和理解多种感官信息)的研究边界,为未来人工智能系统的开发提供了新的视角和工具。通过这个项目,MIT的研究团队不仅推动了音视频处理技术的边界,也为多模态人工智能研究和应用提供了新的视角和工具。
一个提供由人工智能驱动的各种工具和服务的网站。Zazzani AI 可以帮助您完成诸如撰写文章、创建照片、调试代码、产生想法和获得问题答案等任务。