Refuel AI 最近推出了两个新版本的大语言模型 RefuelLLM-2 和 RefuelLLM-2-small。
RefuelLLM-2 和 RefuelLLM-2-small 是专门为数据标注、清洗和丰富任务而设计的语言模型。
- 用途: RefuelLLM-2 主要用于自动化数据标注、数据清洗和数据丰富,这些任务是处理和分析大规模数据集时的基础工作,尤其是在需要将非结构化数据转换为结构化格式的场景中。
- 主要功能:
- 高性能数据标注: 该模型能自动识别和标记数据中的关键信息,如分类数据、解析特定属性等。
- 数据清洗: 自动识别和修正数据中的错误或不一致,如拼写错误、格式问题等。
- 数据丰富: 根据已有数据,自动补充缺失的信息或提供额外的上下文,增加数据的价值和可用性。
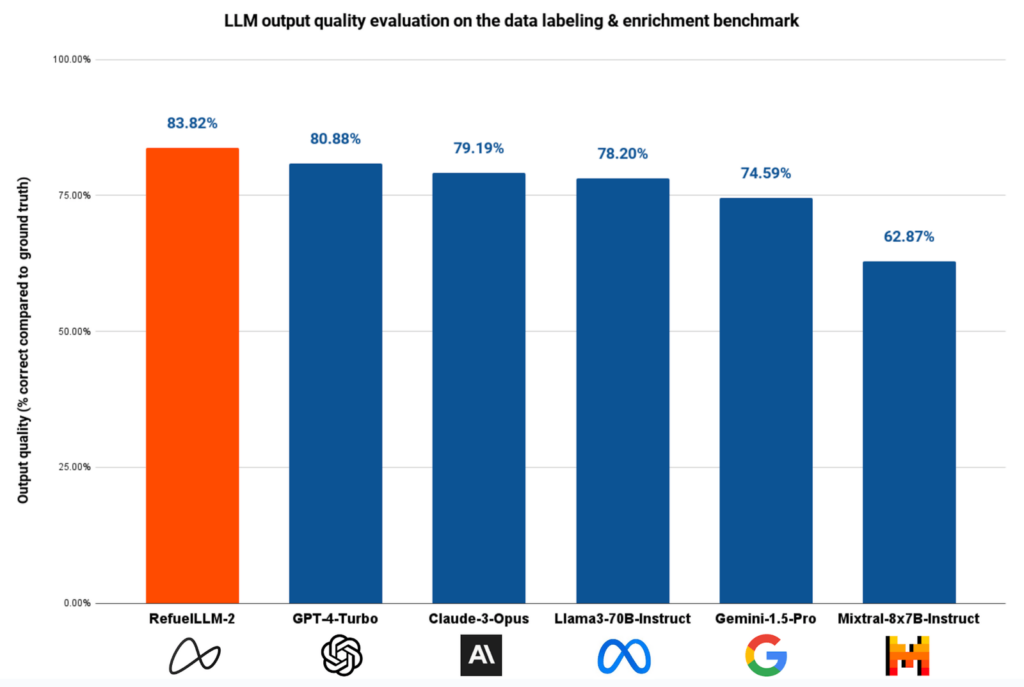
- 高准确率: 在约 30 项数据标注任务的基准测试中,RefuelLLM-2(83.82%)的表现优于所有最先进的LLMs ,包括 GPT-4-Turbo(80.88%)、Claude-3-Opus(79.19%)和 Gemini-1.5-Pro(74.59%)。
两款模型比较:
- 训练数据广泛: 两款模型都在涵盖多种任务的2750多个数据集上进行训练,这些数据集包括分类、阅读理解、结构化属性提取和实体解析等。
- 技术架构: RefuelLLM-2 基于 Mixtral-8x7B 模型,而 RefuelLLM-2-small 基于 Llama3-8B 模型,两者都能处理大规模的输入数据,尤其是 RefuelLLM-2 支持高达32K的最大输入上下文长度。
- RefuelLLM-2 在约30个数据标注任务中表现优于所有其他先进的大型语言模型,包括 GPT-4-Turbo 和 Claude-3-Opus。RefuelLLM-2的正确率为83.82%,而RefuelLLM-2-small(即Llama-3-Refueled)的正确率为79.67%,也超过了同类模型。
- RefuelLLM-2-small 是RefuelLLM-2 小型版本,设计目的是为了提供一个成本更低、运行更快,但依然保持较高性能的选择。虽然是小型版本,但依然能够处理复杂的数据标注任务,适合在资源受限的环境中使用。
模型基础
- RefuelLLM-2:
- 基础模型: Mixtral-8x7B
- 特点: 这是一个大型的语言模型,设计用于处理高达32K的最大输入上下文长度。这使得模型特别适合处理长文本输入,如长篇文章或报告,从而能够在这类任务中表现出色。
- RefuelLLM-2-small: RefuelLLM-2-小号: RefuelLLM-2-small
- 基础模型: Llama3-8B
- 特点: 作为一个较小的模型,其设计目的是在保持较高性能的同时,运行更快、成本更低。此版本支持高达8K的输入上下文长度,适用于中等长度的文本处理。
训练细节
-
训练数据集:
- 两款模型都在覆盖多种任务的2750个以上的数据集上进行训练,包括人工注释的数据集(如 Flan, Task Source, Aya collection)和合成数据集(如 OpenOrca, OpenHermes, WizardLM)。
- 训练数据包括分类、阅读理解、结构化属性提取和实体解析等任务。
-
训练方法:
- 第一阶段: 主要进行模型的指令调整训练,用以使模型在数据标注和丰富任务上达到专家级别。这一阶段的训练使用了4096个标记的最大行长度,训练21,000步,批次大小为32,使用余弦学习率调度器,初始学习率设置为1e-5,衰减到原始值的10%。
- 第二阶段: 进一步在训练集中加入更长上下文的输入,继续训练模型5,000步,批次大小为16,并使用2步的梯度累积。这一阶段的学习率更敏感,使用余弦学习率调度器,初始学习率为2e-6,衰减到原始值的10%。
-
性能提升:
- 这种两阶段训练方法使得模型不仅在基本的数据处理任务中表现出色,还能有效处理长上下文的输入,这对于现实世界中的复杂数据处理任务尤为重要。
质量评估
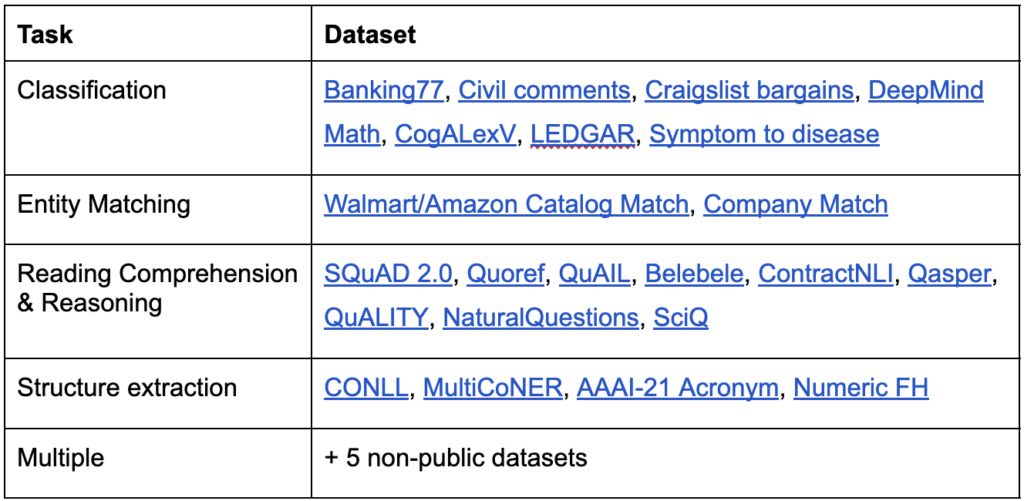
- 评测任务: 模型在约30个数据标注任务上进行评测,这些任务涵盖了多种类型的数据处理需求。
- 基准测试: 在新增的10个数据集上进行基准测试,包括长上下文数据集如 QuALITY 和 NaturalQuestions,以及非公开数据集,这些非公开数据集用于评估模型在真实世界数据上的表现。
- 输出质量: 根据模型生成的输出与给定的真实标签的一致性进行评估。RefuelLLM-2 的输出质量达到了 83.82%,超过了包括 GPT-4-Turbo (80.88%)、Claude-3-Opus (79.19%) 和 Gemini-1.5-Pro (74.59%) 在内的所有当前最先进的大型语言模型。
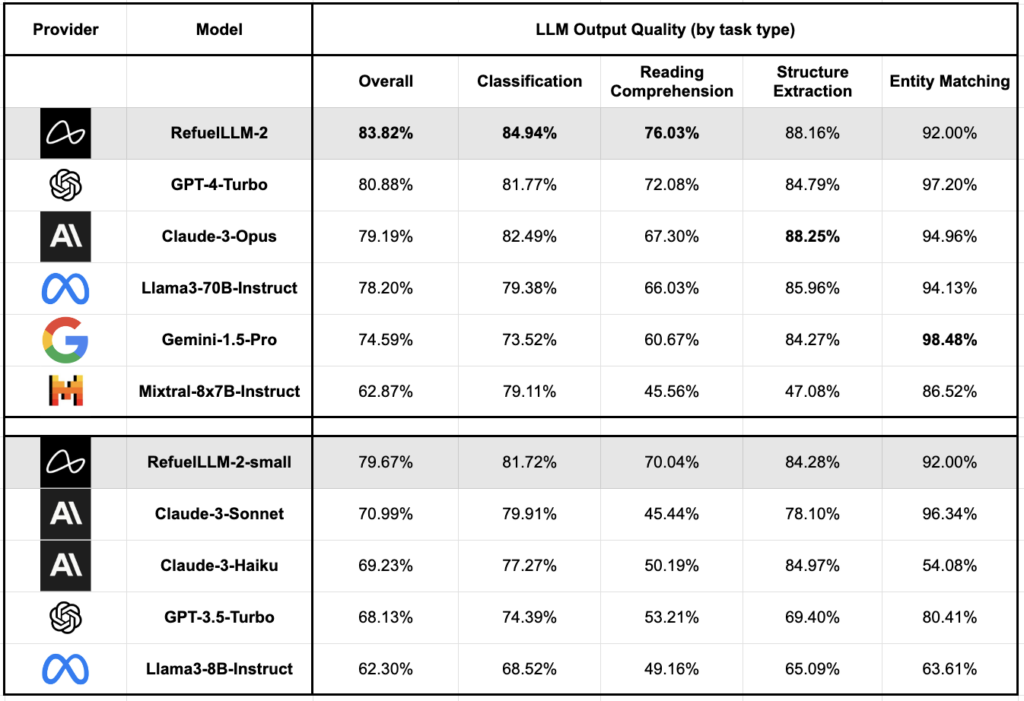
- 对比小型模型: RefuelLLM-2-small 的输出质量为 79.67%,超过了其他类似大小/推理成本的模型,如 Claude-3-Sonnet (70.99%)、Haiku (69.23%) 和 GPT-3.5-Turbo (68.13%)。
上下文长度和非公开数据集的性能
- 长上下文数据集: 评估显示,RefuelLLM-2 在处理长上下文输入时的表现优于所有其他模型,尽管长上下文输入对所有模型的性能都有影响。
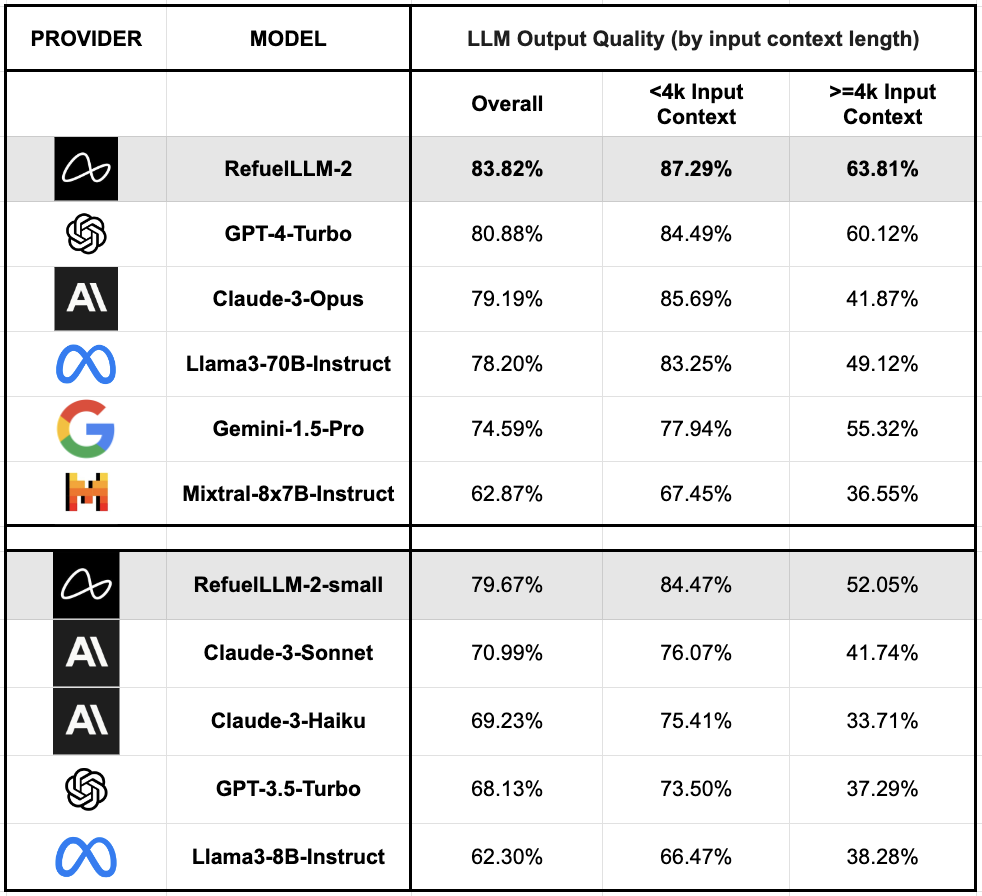
- 非公开数据集: 使用非公开数据集进行评估有助于理解模型在真实世界场景中的可靠性和质量。结果显示,RefuelLLM-2 和 RefuelLLM-2-small 在这些数据集上的表现同样出色,表明模型具有良好的泛化能力。
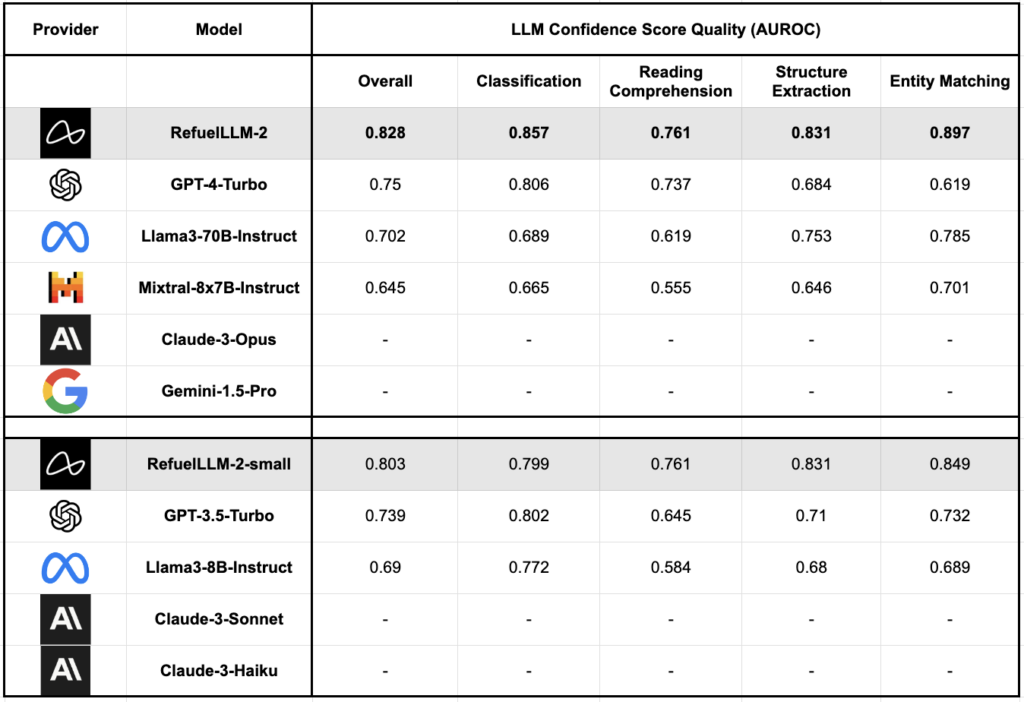
置信度分数的质量
- 置信度分数质量: 利用平均令牌生成概率作为评估 LLM 输出置信度的启发式方法。在使用 AUROC(区分正类(“LLM输出正确”)和负类(“LLM输出错误”)的能力的综合得分)进行评估时,RefuelLLM-2 和 RefuelLLM-2-small 显示出比其他模型更好的置信度分数校准。
Translate Now是一款免费的翻译应用程序,可让您在 100 多种语言之间翻译文字、语音和图像。它使用 Google 翻译技术,提供快速、准确的翻译。