Jina AI 宣布其 Reader 工具现在能够从任意 URL 读取 PDF 文件,并快速解析成文本,供下游的语言模型(LLM)使用。
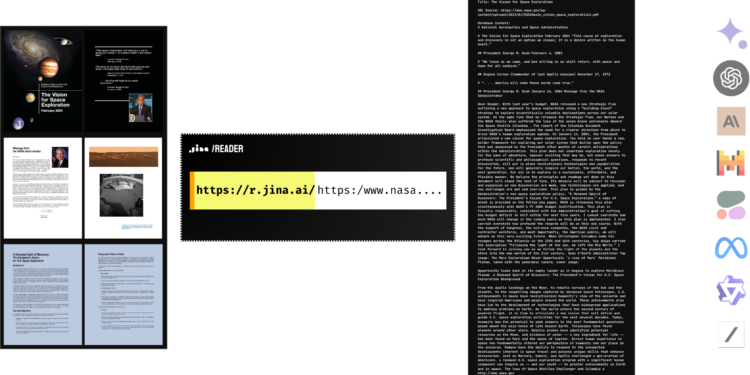
只需将PDF的URL添加到http://r.jina.ai前缀,如 这个例子,(https://r.jina.ai/https://www.nasa.gov/wp-content/uploads/2023/01/55583main_vision_space_exploration2.pdf)即可获得已解析好的文本,供下游的语言模型(LLM)使用。Reader原生支持PDF读取,兼容大多数PDF文件,包括含有大量图片的文件,而且解析速度非常快!
之前,该工具的 PDF 支持仅限于 arXiv 并依赖于其 HTML 版本。解析 PDF 的过程复杂,需要渲染 URL 确认其是否为 PDF,并且将其转换为清晰的文本通常需要 OCR 技术。现在,Jina Reader 提供了这一免费的新功能,提升了 LLM 的文本处理能力。
- Jina AI Reader 现在支持从任何 URL 读取任意 PDF。
- 只需添加 PDF 的 URL 即可获得解析好的文本,供下游的 LLM 使用。
- Reader 本地支持 PDF 阅读,包括带有大量图片的 PDF,并且速度极快。
- 之前的 PDF 支持仅限于 arXiv,并依赖 arXiv 提供的 HTML 版本。
- 正确解析 PDF 并不容易,需要渲染 URL 以确定其是否为 PDF。
- PDF 设计用于打印,不适合直接子处理,转换为干净的文本通常需要 OCR。
- 这个新功能现在在 Jina Reader 中免费提供。
视频播放器
00:00
00:00
- URL判断PDF的难度:
- 仅通过URL是否以“.pdf”结尾来判断其是否为PDF是不可靠的。
- 有些URL虽然看起来像PDF但不是,有些则反之,例如arXiv的链接(示例链接),该链接并不以“.pdf”结尾,但返回的是PDF。
- 因此,需要先渲染URL并相应地处理它。由于浏览器无法原生渲染PDF内容,因此需要使用像pdf.js这样的工具来渲染页面。
- PDF的复杂性:
- 许多人忘记了PDF是为打印设计的,而不是为子处理设计的。
- PDF中的图像、文本和表格各自在自己的层中,没有任何关联,仅仅出现在特定位置以呈现最终布局。
- 可以将其类比为HTML中的一堆
<div>元素,每个元素都由上、左、右和下的绝对位置定义。 - 将它们转换为干净的、适合LLM阅读的文本通常需要使用OCR来识别图像,类似于将扫描的纸质书籍转换为电子文本。
 Jina AI Reader 读取任意 PDF 的详细步骤
Jina AI Reader 读取任意 PDF 的详细步骤
- 准备 PDF URL:
- 找到你想要读取的 PDF 文件的 URL。例如:https://example.com/sample.pdf
- 添加 URL 到 Jina Reader:
- 将 PDF 的 URL 添加到 Jina Reader 中。只需将 URL 粘贴到指定的输入框中。
- 或者http://r.jina.ai后+https://example.com/sample.pdf
- 解析 PDF:
- Jina Reader 会自动解析你提供的 URL,并将其中的内容提取出来。这包括处理图像、文本和表格等内容。
- 由于无法仅通过 URL 判断其是否为 PDF,Jina Reader 使用
pdf.js来渲染页面,从而准确解析内容。
- 查看解析结果:
- 一旦解析完成,你可以查看提取出来的文本内容。这些文本已经过处理,适合下游的语言模型(LLM)使用。
- 处理嵌入 PDF 的特殊情况:
- 如果网页中嵌入了多个 PDF 或 PDF 嵌入在 HTML 中,Jina Reader 也能正确处理并解析这些内容。
- 应对复杂的 PDF 格式:
- 对于包含大量图片或复杂布局的 PDF,Jina Reader 使用 OCR 技术来识别图像中的文本,确保内容的完整性和准确性。
- 使用解析好的文本:
- 解析好的文本可以用于你的语言模型、数据分析或其他下游应用。这些文本是经过优化的,便于进一步处理和使用。
Jina AI Reader:https://jina.ai/reader/
度加创作工具-度加剪辑官网入口网址,文案成片、文章成片、素材匹配、一键包装