
Video-MME(Multi-Modal Evaluation benchmark)是首个专门为评估多模态大语言模型(MLLMs)在视频分析中的表现而设计的综合评估基准。该基准由来自多个大学和研究机构的研究人员共同开发,旨在通过多样化和高质量的数据集,全面考察MLLMs在处理视频数据时的能力。
与现有基准相比,Video-MME有四个关键特性
- 视频类型的多样性:
- 涵盖领域:视频数据集涵盖6个主要视觉领域,包括知识、电影与电视、体育竞技、艺术表演、生活记录和多语言。
- 子领域细分:每个领域进一步细分为30个子类别,如天文学、科技、纪录片、新闻报道、电竞、魔术表演和时尚等,确保广泛的场景适用性。
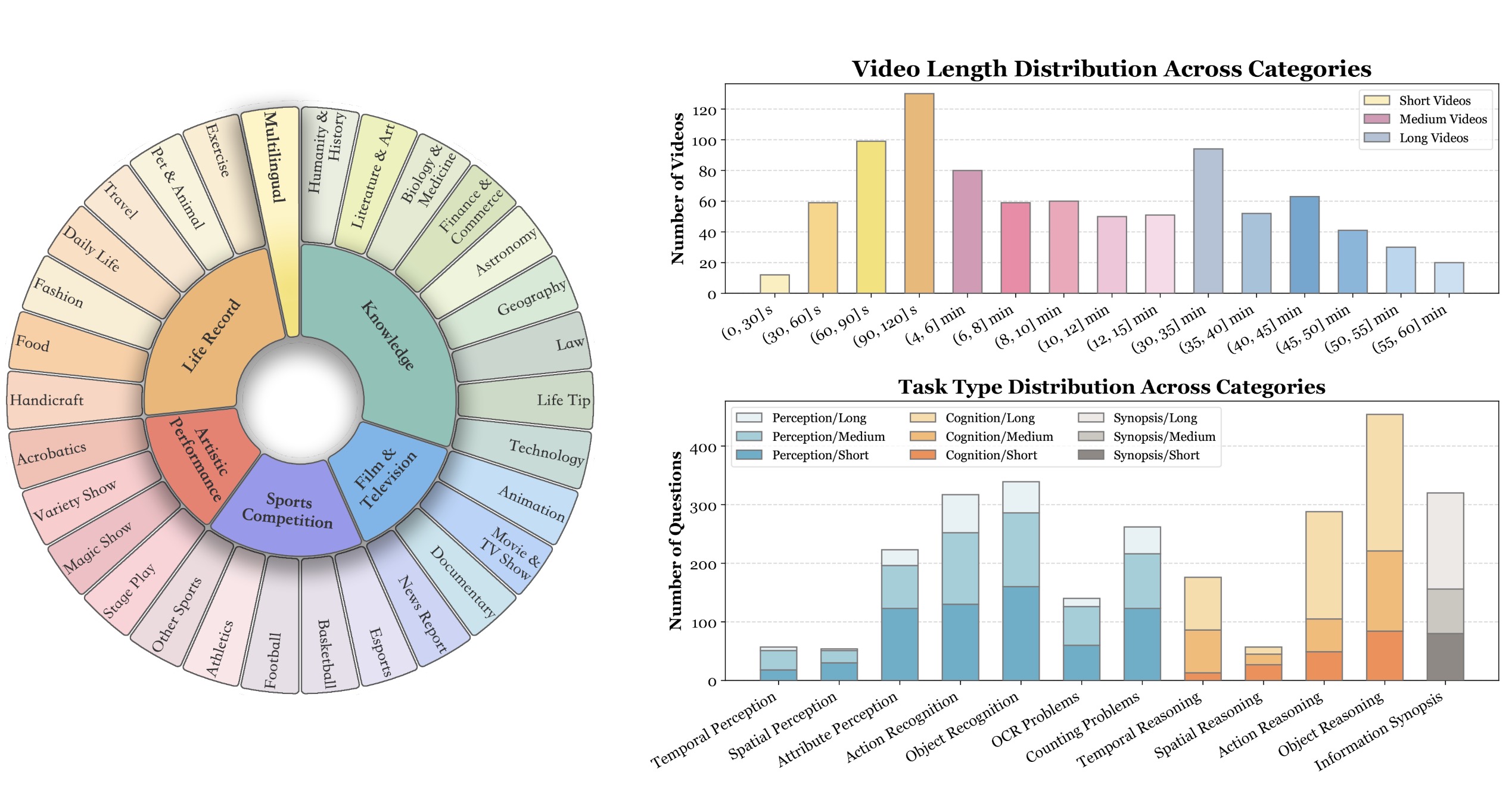
- 时间维度的持续性:
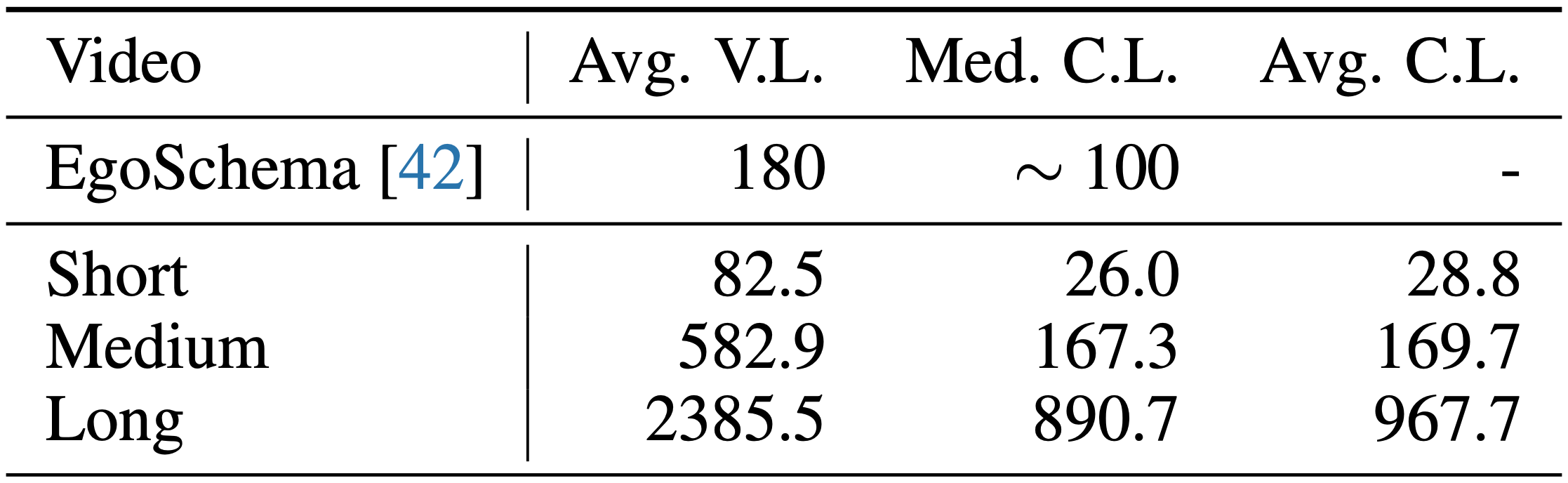
- 视频长度:视频长度从短视频(11秒)到长视频(1小时)不等,评估模型在不同时间上下文中的适应性和处理能力。
- 多层次评估:通过短、中、长视频(分别为<2分钟、4-15分钟、30-60分钟)来全面考察MLLMs在不同时间尺度上的表现。
- 数据模态的广泛性:
- 多模态输入:除了视频帧,还整合了字幕和音频等多模态输入,以全面揭示MLLMs的理解和处理能力。
- 多模态评估:通过同时评估视觉、听觉和文本信息,全面考察模型的多模态理解能力。
- 高质量注释:
- 手动标注:由专家多次观看视频并进行严格的手动标注,确保数据集的高质量和准确性。
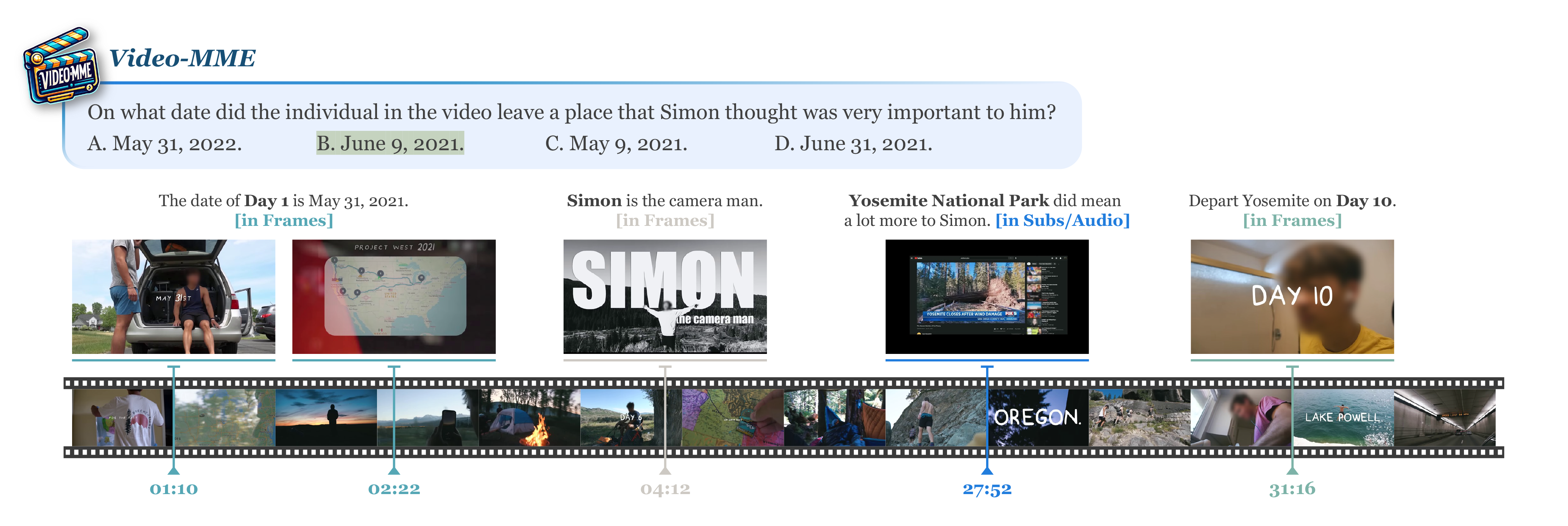
- 问答对:每个视频配有3个高质量的多项选择问题,总计2,700对问答对,涵盖感知、推理和信息总结等任务类型。
数据集构建
- 视频收集:定义6个关键领域和30个细分视频类别,从YouTube收集900个视频,确保视频长度的多样性,包括短(<2分钟)、中(4-15分钟)和长视频(30-60分钟)。
- 问答注释:每个视频注释3个高质量的多项选择问题,总计2,700对问答对。
- 质量审核:进行严格的手动审核,确保问题表达正确且明确,并能有效评估模型。

对市面上的视觉模型评估结果
Video-MME评估了多种先进的MLLMs,包括GPT-4系列、Gemini 1.5 Pro,以及开源图像模型(如InternVL-Chat-V1.5)和视频模型(如LLaVA-NeXT-Video)。
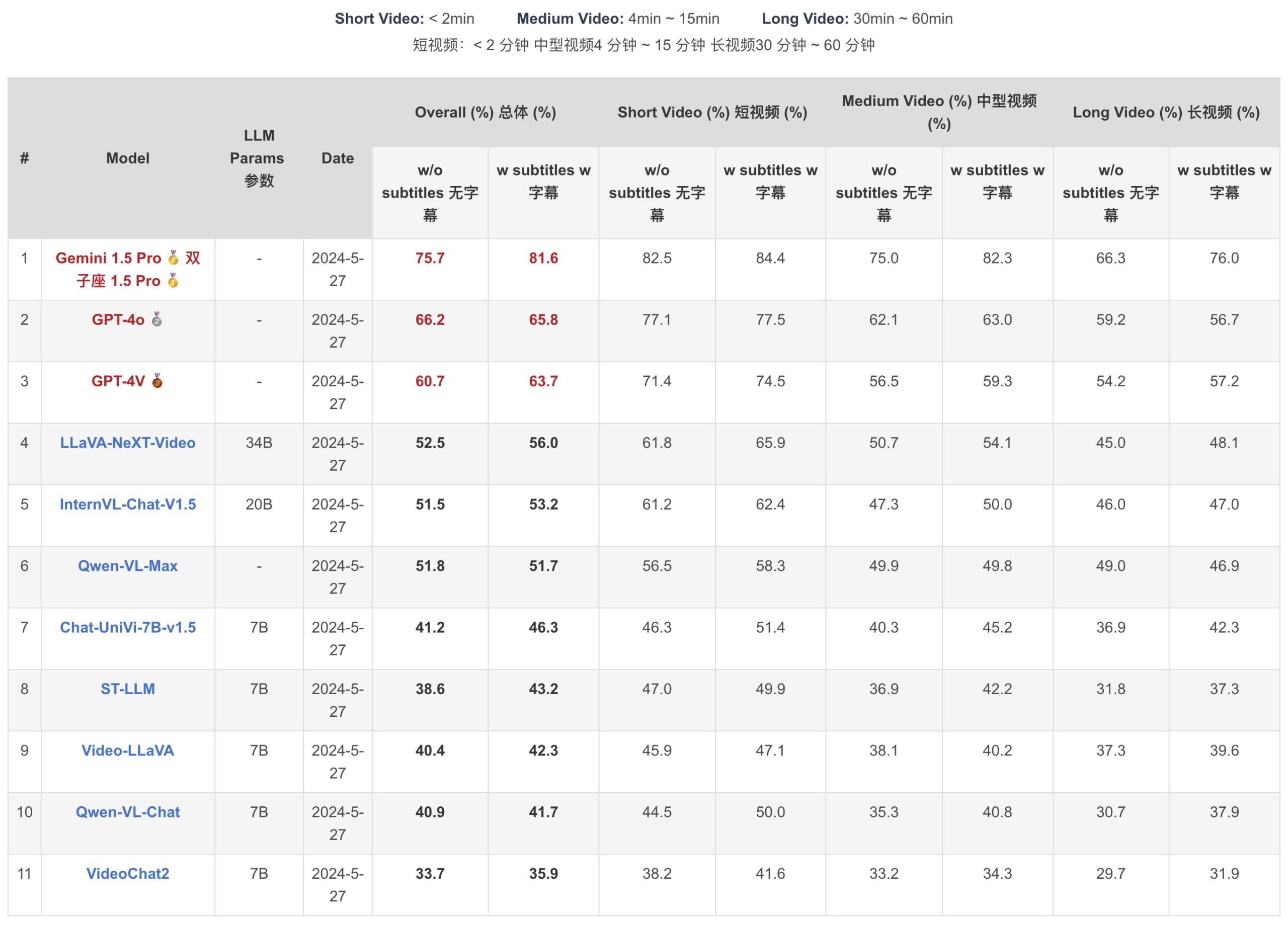 模型表现
模型表现
- 总体准确率:
- Gemini 1.5 Pro:75.7%
- GPT-4o:66.2%
- GPT-4V:60.7%
- LLaVA-NeXT-Video:52.5%
- InternVL-Chat-V1.5:51.5%
- 视频时长对比:
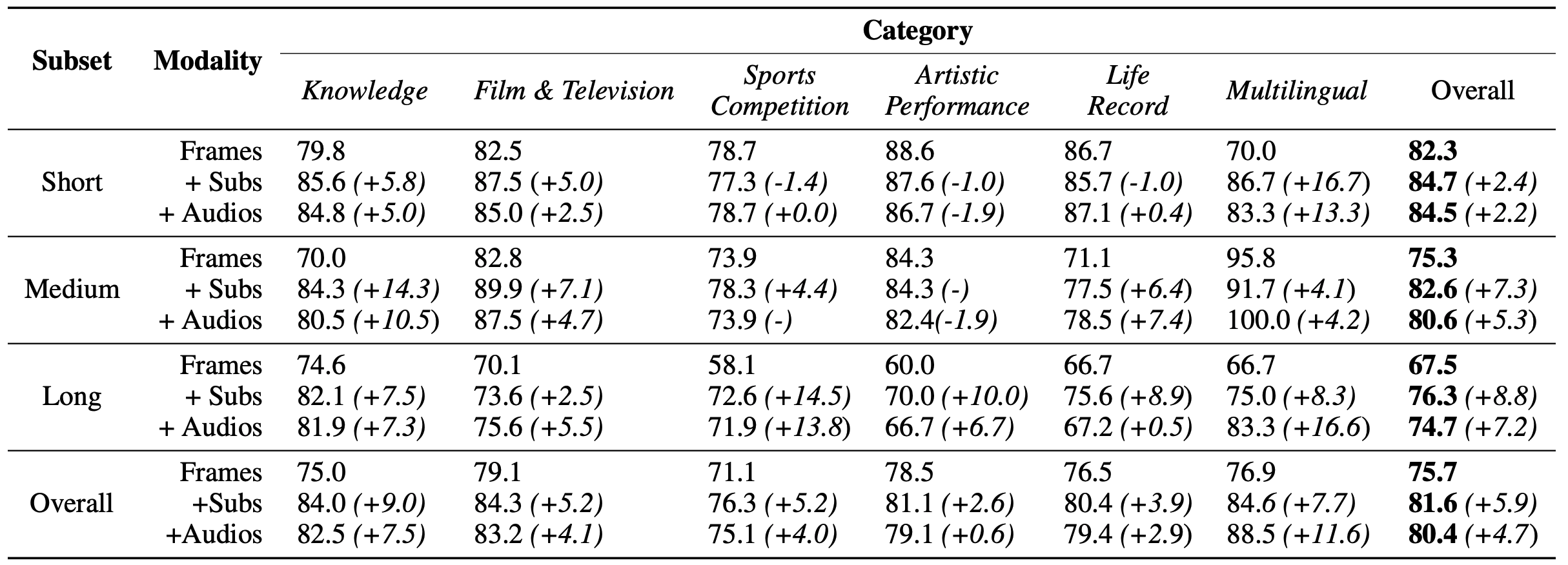
- 短视频(< 2分钟):Gemini 1.5 Pro 表现最好,达84.4%(带字幕)。
- 中等视频(4-15分钟):Gemini 1.5 Pro 表现最好,达82.3%(带字幕)。
- 长视频(30-60分钟):Gemini 1.5 Pro 表现最好,达76.0%(带字幕)。
- 商业模型:
- Gemini 1.5 Pro:表现最佳,平均准确率为75.7%,特别是在短视频(<2分钟)上的准确率为82.3%。
- GPT-4V和GPT-4o分别以63.7%和65.8%的准确率位列其后。
- 开源模型:
- LLaVA-NeXT-Video:开源模型中表现最好,准确率为52.5%。
- 其他开源模型如Video-LLaVA和Chat-UniVi-V1.5的准确率分别为42.3%和46.3%。
- 图像模型:
- Qwen-VL-Max和InternVL-Chat-V1.5的表现接近视频特定模型LLaVA-NeXT-Video,分别达到51.7%和53.2%的准确率。
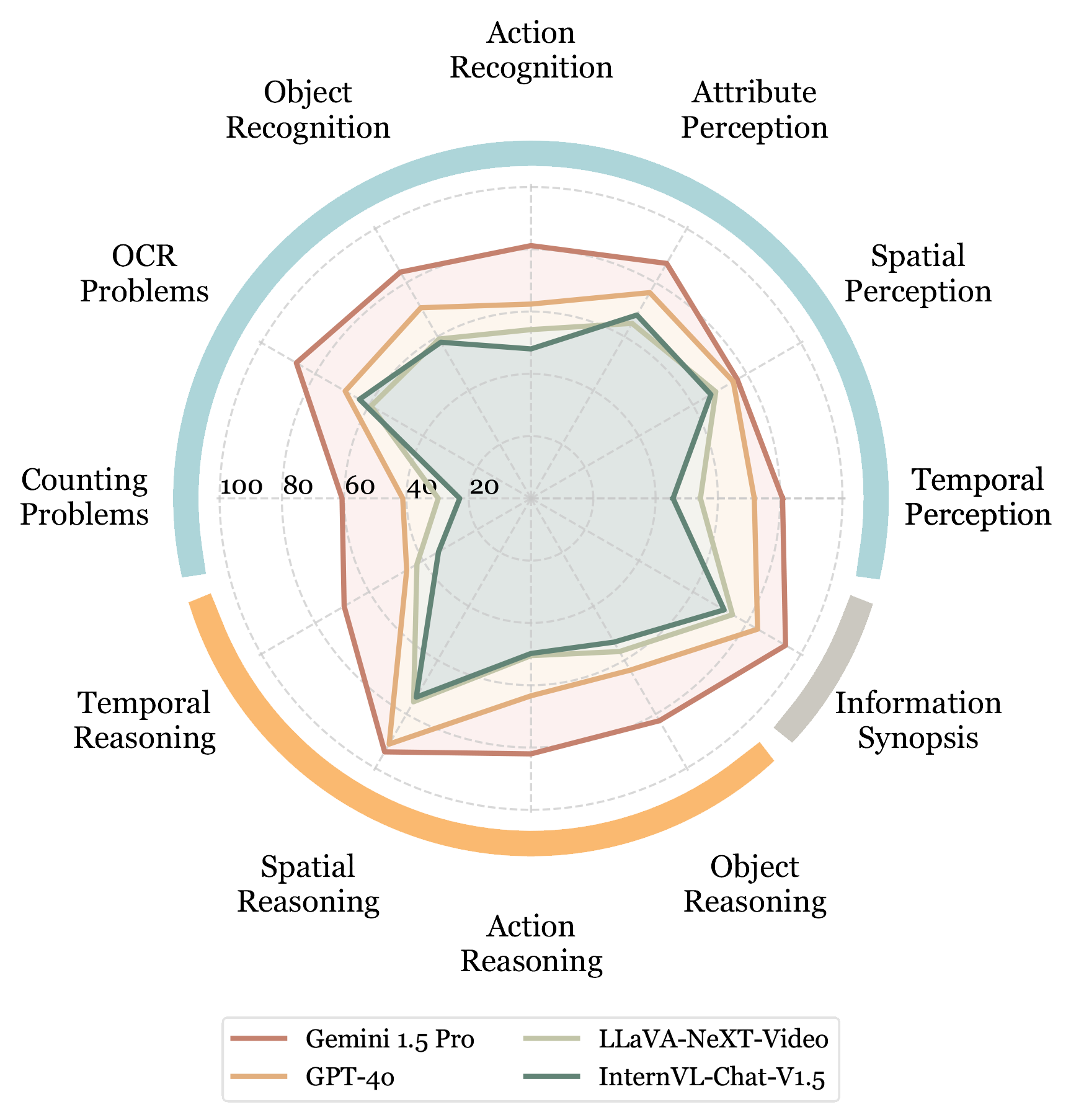
 模态信息对性能的影响
模态信息对性能的影响
- 字幕和音频显著增强了视频理解能力:
- 增加字幕后,Gemini 1.5 Pro的整体准确率提高了5.9%。
- 增加音频后,长视频的准确率提升了7.2%。
不同视频时长对性能的影响
- 随着视频长度的增加,所有模型的性能均有所下降:
- Gemini 1.5 Pro在短视频上的准确率为82.3%,而在长视频上的准确率下降到67.5%。
- LLaVA-NeXT-Video在短视频上的准确率为63.1%,而在长视频上的准确率下降到44.6%。
项目地址:https://video-mme.github.io/home_page.html
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
全球影片截图调色参考