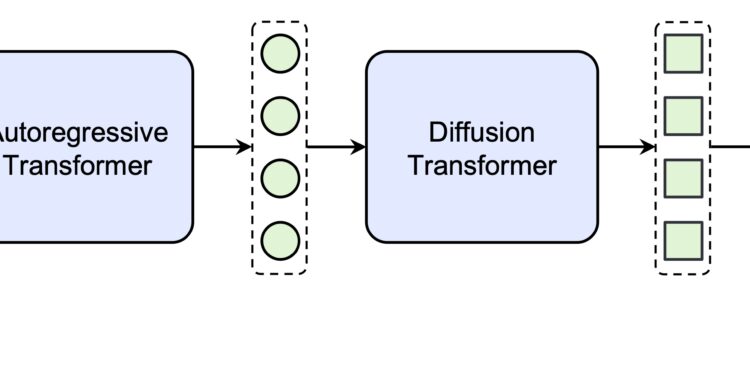
Seed-TTS 是由字节跳动开发的一种高级文本到语音(TTS)模型系列,能够生成高质量、几乎无法与人类语音区分的语音。该模型可以基于简短的语音片段生成高度自然且富有表现力的语音。
Seed-TTS 在多个实验中表现优异,其生成的语音在自然度和说话者相似度上接近人类语音,展示了强大的生成能力和应用潜力。
主要功能
1. 高质量语音生成
Seed-TTS 是一种能够生成高质量、几乎无法与人类语音区分的语音模型。通过大规模自回归文本到语音(TTS)模型的架构设计,Seed-TTS 在语音自然度和说话者相似度方面达到了新的高度。
特点:
- 自然度:生成的语音在自然度方面几乎无法与真实人类语音区分。
- 表达力:语音表现力强,能够准确传达不同的情感和语调。
2. 语音属性控制
Seed-TTS 提供了对各种语音属性的高级控制能力,包括但不限于情感、语调、说话风格等。通过精调,用户可以灵活地控制生成语音的不同属性,以满足各种应用场景的需求。
视频播放器
控制属性:
- 情感:可以控制生成语音的情感,如愤怒、快乐、悲伤、惊讶等。
- 语调:调节语音的语调和节奏,使其更符合特定场景的需求。
- 说话风格:调整说话风格,如正式、非正式、戏剧化等。
视频播放器
3. 多样性和表现力
Seed-TTS 能够生成高度多样化和富有表现力的语音,这使得它在多个应用场景中表现出色,如有声读物、虚拟助手、视频配音等。
多样性表现:
- 语音多样性:生成的语音能够涵盖广泛的情感和风格变化。
- 表达力:语音在表达力方面表现优异,能够传达复杂的情感和语境。
视频播放器
4. 零样本上下文学习
Seed-TTS 支持零样本上下文学习(ICL),这意味着即使在没有大量训练数据的情况下,也能够基于简短的语音片段生成高质量的语音。这一功能特别适用于需要快速生成特定说话者语音的应用场景。
零样本学习特点:
- 快速生成:基于简短的语音片段,快速生成与原始说话者相似的语音。
- 高精度:生成的语音在相似度和自然度方面接近人类语音。
视频播放器
5. 强化学习增强
通过引入强化学习(RL)方法,Seed-TTS 在模型鲁棒性、说话者相似度和可控性方面得到了显著提升。RL 方法使得模型能够在不同的环境中保持稳定性,并提高生成语音的质量。
强化学习应用:
- 模型鲁棒性:增强模型在不同场景下的稳定性。
- 说话者相似度:提高生成语音的说话者相似度。
- 可控性:通过RL方法实现对生成语音更精细的控制。
视频播放器
6. 语音编辑功能
Seed-TTS 支持语音内容编辑和说话速度编辑,使得用户可以根据需要对生成的语音进行灵活调整。
编辑功能:
- 内容编辑:可以对生成的语音内容进行部分修改和替换。
- 速度编辑:可以调整生成语音的说话速度,以适应不同的应用场景需求。
视频播放器
6.跨语言内容创建
- 功能:支持不同语言间的语音转换,帮助跨语言沟通和交流。
- 实例:语言学习应用,通过Seed-TTS生成目标语言的发音,帮助学习者练习口语。
- 中文转英文Source Video
视频播放器
00:0000:00Generated Video
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
一个由人工智能驱动的漫画生成工具,它允许用户发挥创造力并创建由人工智能生成的漫画。它提供多种风格和角色,将您的故事转化为逼真的漫画。