
VideoLLaMA 2 是一个旨在提升视频大语言模型(Video-LLM)时空建模和音频理解能力的项目。该模型集成了一个专门设计的时空卷积(Spatial-Temporal Convolution,STC)连接器,有效捕捉视频数据中的复杂时空动态。此外,通过联合训练,模型还集成了音频分支,增强了多模态理解能力。
- 理解视频里的动作和变化:它能识别视频中人物的动作和事件,比如知道某人在做什么。
- 处理视频中的声音:它不仅看视频,还能听视频里的声音,比如说话声或音乐,并结合声音和画面理解内容。
- 回答关于视频的问题:你可以问它视频里的事情,它会给出详细的回答,比如“这个人在干什么?”。
- 生成视频字幕:它能为视频生成字幕,方便观众理解视频内容。
视频播放器
00:00
00:00
VideoLLaMA 2 的主要功能详细介绍
1. 多模态视频理解
VideoLLaMA 2 通过整合视觉和音频信号,显著提升了对视频内容的理解能力。其主要功能包括:
- 多选视频问答(MC-VQA):在多选题视频问答任务中,VideoLLaMA 2 能够准确地从视频内容中提取信息并选择正确答案。
- 开放式视频问答(OE-VQA):在开放式问答任务中,模型能够根据视频内容生成详细的自然语言回答。
- 视频字幕生成(VC):能够为视频生成自然、详细的字幕,准确描述视频中的重要事件和细节。
2. 空间-时间建模
VideoLLaMA 2 引入了空间-时间卷积连接器(STC),能够更好地捕捉视频中的复杂动态,主要功能包括:
- 空间-时间卷积:通过3D卷积操作,有效聚合视频帧的空间和时间特征,保持视频的空间和时间顺序。
- 局部细节保留:采用RegStage模块在空间压缩过程中保留局部视觉模式,提高视频理解的准确性。
3. 音频理解与整合
VideoLLaMA 2 通过联合训练的音频分支,提升了模型的音频理解和整合能力,具体功能包括:
- 音频特征提取:使用BEATs音频编码器,将音频信号转换为详细的音频特征。
- 音频-语言对齐:通过线性层将音频特征与大型语言模型对齐,实现音视频内容的无缝结合。
- 音频问答(AQA):在音频问答任务中,模型能够根据音频输入生成准确的回答。
- 通过将音频信号转换为对数梅尔频谱图,并结合先进的音频编码器(如BEATs),VideoLLaMA 2能够提取详细的音频特征,并与视觉特征进行对齐,从而实现更全面的多模态理解。
4. 联合训练与优化
VideoLLaMA 2 采用多任务联合训练方法,优化模型在多模态任务中的表现,具体包括:
- 多任务微调:结合视频-语言和音频-语言数据进行微调,提高模型在多模态任务中的通用性和准确性。
- 联合训练策略:通过联合音频和视频模态的数据,提升模型对复杂场景的理解和应对能力。
技术方法
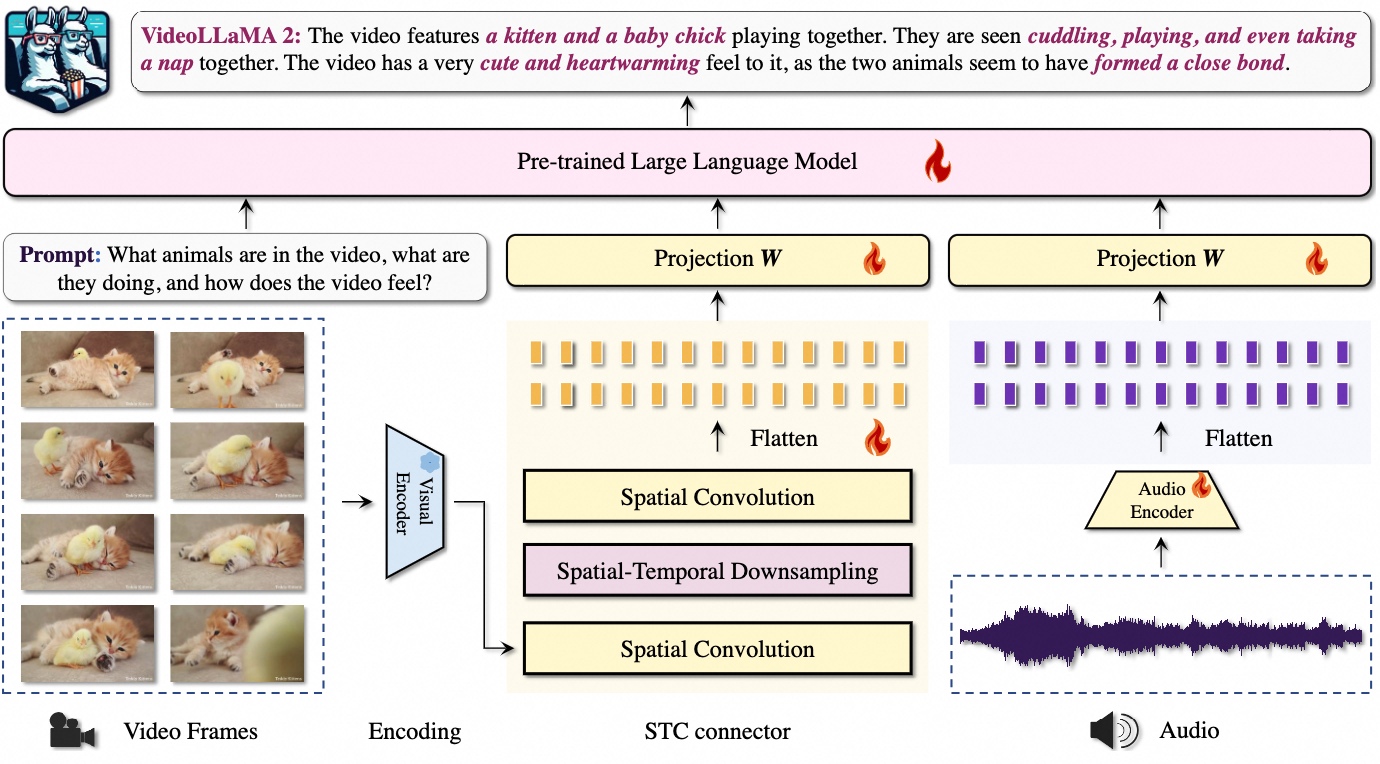 1. 架构设计
1. 架构设计
VideoLLaMA 2 采用了双分支框架,包括视觉-语言分支和音频-语言分支。
- 视觉-语言分支:
- 视觉编码器:采用 CLIP(ViT-L/14)作为视觉编码器,将视频帧编码为特征。
- 空间-时间卷积连接器(STC):通过3D卷积操作,聚合视频帧的空间和时间特征,并使用RegStage块在下采样前后保持局部视觉模式。
- 语言模型:使用大型语言模型(如 Mistral-Instruct 或 Mixtral-Instruct)生成基于文本提示的响应。
- 音频-语言分支:
- 音频预处理:将音频信号转换为对数梅尔频谱图。
- 音频编码器:使用 BEATs 音频编码器提取音频特征。
- 线性层对齐:通过线性层将音频特征与大型语言模型对齐,实现音视频内容的结合。
2. 空间-时间卷积连接器(STC)设计
- 3D 卷积:使用3D卷积操作进行空间-时间聚合,有效捕捉视频中的动态变化,它能同时处理视频的空间和时间信息,帮助模型理解视频中的动作。
- RegStage 块:在压缩视频信息时,保持重要的细节,确保模型不漏掉任何重要内容。
3. 训练过程
VideoLLaMA 2 的训练过程分为三个阶段:视频-语言训练、音频-语言训练和音频-视频联合训练
- 视频-语言训练:
- 预训练:使用大量的视频和文本数据,让模型学会基本的视觉和语言理解。
- 多任务微调:使用更高质量的数据进行细致的训练,提高模型在具体任务中的表现。
- 音频-语言训练:
- 预训练:使用大量的音频和文本数据,让模型学会基本的音频和语言理解。
- 多任务微调:使用不同的音频数据进行细致的训练,提高模型的音频理解能力。
- 音频-视频联合训练:
- 联合训练:同时使用音频和视频数据进行训练,让模型学会如何结合音频和视频信息进行理解和回答。
4. 模型评估
VideoLLaMA 2 在多个基准测试中进行评估,包括视频理解和音频理解任务。
- 视频理解评估:
- MC-VQA:评估多选视频问答任务中的表现,测试集包括EgoSchema、Perception-Test、MV-Bench等。
- OE-VQA:评估开放式视频问答任务,测试集包括MSVD-QA、ActivityNet-QA等。
- 视频字幕生成:在多源视频字幕(MSVC)基准上评估生成字幕的正确性和详细度。
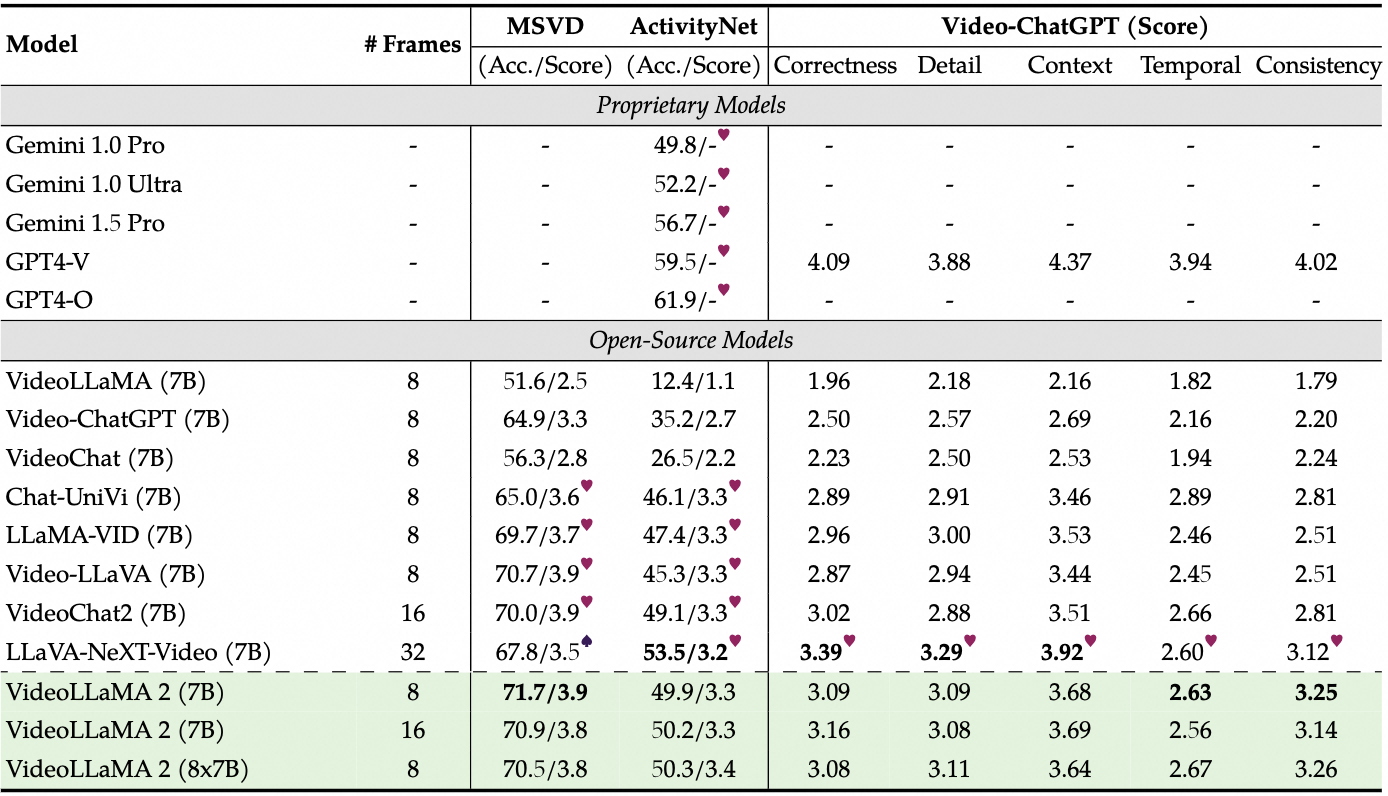

- 音频理解评估:
- AQA:在Clotho-AQA和TUT2017数据集上评估音频问答任务中的表现。
- OE-AVQA:评估开放式音频-视频问答任务,测试集包括AVSSD、AVSD、Music-AVQA等。
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
remove.bg 是一款强大的自动去除图片背景的在线工具,快速AI自动抠图!图片背景5秒消除,免费!