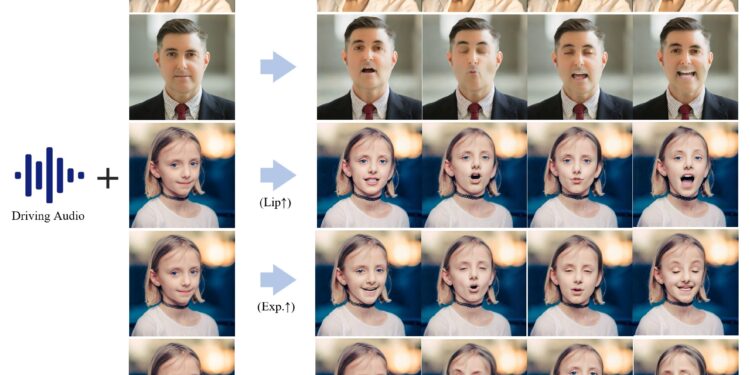
通过语音音频输入来驱动肖像图像生成动画视频,也就是一段语音+个人图像生成会说话唱歌的视频。
研究团队提出了一种创新的基于扩散模型的层次化音频驱动视觉合成方法。这个方法的目的是提高语音输入与生成的动画之间的对齐精度,包括嘴唇、表情和姿态的同步。
- 通过输入语音,生成对应的人物嘴唇同步、表情变化和姿态变化的动画。
- 提高语音与生成动画之间的对齐精度,使动画的嘴唇、表情和姿态与语音更匹配。
- 采用先进的技术和结构,增强了动画生成的实时性和视觉效果,使生成的动画更加逼真和自然。
视频播放器
00:00
00:00
主要功能
- 虚拟角色动画生成
- 通过语音音频输入生成逼真、动态的虚拟角色动画。
- 实现了虚拟角色的口型、表情和姿态的精确同步。.
视频播放器00:0000:00视频播放器00:0000:00视频播放器00:0000:00视频播放器00:0000:00
- 真实角色动画生成
- 应用于真实人物的语音驱动动画生成。
- 生成的动画能准确反映真实人物的表情和动作变化。
视频播放器00:0000:00视频播放器00:0000:00
- 多种运动控制
- 提供对角色表情、姿态和嘴唇运动的精确控制。
- 支持多种表情和姿态的自适应控制,增强动画的多样性和真实性。
.视频播放器00:0000:00视频播放器00:0000:00视频播放器00:0000:00
- 跨演员应用
- 支持不同身份的个性化动画生成。
- 通过音频输入,生成适应不同角色身份的动画效果。
视频播放器00:0000:00
- 歌唱动画生成
- 通过语音和歌曲音频输入,生成同步的歌唱动画。
- 动画能够准确反映歌唱时的口型和表情变化。.
视频播放器00:0000:00视频播放器00:0000:00视频播放器00:0000:00






Maverick 是一种基于AI 根据每位客户的购买历史、偏好和行为为其生成个性化视频并将其发送给客户的AI工具。