
DeepMind最新研发了一种叫视频转音频(V2A)的技术。这种技术可以根据视频画面和文字描述,自动生成丰富的音轨。V2A可以与视频生成技术结合,为没有声音的视频添加同步的音效,比如背景音乐、真实的音效或者和视频内容匹配的对话。
这意味着你只需描述一下你想要的音效、背景音乐或对话,V2A就能为你生成匹配的视频声音,让无声视频瞬间变得栩栩如生。
无论是为无声视频添加背景音乐,为老电影制作音轨,还是为社交媒体视频添加特殊音效,V2A都能轻松胜任。此外,电影制作人和创意工作者也可以利用V2A快速试验不同的音效组合,找到最适合他们作品的声音。
视频播放器
Prompt for audio: Cinematic, thriller, horror film, music, tension, ambience, footsteps on concrete
提示音频:电影、惊悚、恐怖电影、音乐、紧张、氛围、混凝土上的脚步声
主要功能
-
音频生成:V2A可以根据视频画面和用户提供的文字描述,自动生成与视频内容同步的音轨。这包括背景音乐、环境音效甚至与视频内容匹配的对话。
-
同步音频:能够确保生成的音频与视频内容完美同步,使得视频和音频之间没有任何延迟或错位。这对于增强观众的观看体验至关重要。
-
多样化音轨:用户可以为任何视频生成无限数量的音轨,从而尝试不同的音效组合,找到最适合视频内容的声音。V2A提供了极大的创意空间,让用户自由探索和实验。
-
创意提示
V2A支持“正向提示”和“负向提示”功能。正向提示可以引导模型生成所需的特定声音,而负向提示则可以避免生成不希望出现的声音。通过这些提示,用户可以精确控制生成的音频效果。
-
高质量音频
为了生成高质量的音频,V2A在训练过程中引入了详细的声音描述和对话转录。这些附加信息帮助模型学习在不同视觉场景中生成特定的音频事件,确保生成的音轨真实且富有表现力。
-
自动化处理
V2A系统不需要手动对齐生成的声音与视频,这减少了调整声音、视觉和时间元素的繁琐工作。用户可以专注于创意和内容,而不必担心技术细节。
一些案例
Prompt for audio: Cute baby dinosaur chirps, jungle ambience, egg cracking
提示音频:可爱的小恐龙叽叽喳喳,丛林氛围,蛋壳破裂视频播放器00:0000:00
Prompt for audio: jellyfish pulsating under water, marine life, ocean
提示音频:水下脉动的水母,海洋生物,海洋视频播放器00:0000:00
Prompt for audio: A drummer on a stage at a concert surrounded by flashing lights and a cheering crowd
提示音频:音乐会上一个鼓手站在舞台上,周围是闪烁的灯光和欢呼的人群视频播放器00:0000:00
Prompt for audio: cars skidding, car engine throttling, angelic electronic music
提示音频:汽车打滑,汽车发动机节流,天使般的电子音乐视频播放器00:0000:00
Prompt for audio: a slow mellow harmonica plays as the sun goes down on the prairie
提示音频:当太阳在大草原上落下时,一支悠缓柔和的口琴演奏视频播放器00:0000:00
Prompt for audio: Wolf howling at the moon
提示音频:狼对着月亮嚎叫视频播放器00:0000:00
工作原理
-
输入视频和文字描述:首先,你需要提供一个视频和一些简单的文字描述。这些描述可以是你希望音频内容的类型,比如:“紧张的背景音乐”或“鸟叫声”。
-
视频编码:系统会将视频转换成一种可以被AI处理的格式,就像是将视频变成AI能理解的语言。
-
生成音频:接下来,AI模型会从一片随机的噪声开始,通过多次优化,逐渐生成与你的视频和文字描述相匹配的音频。想象一下,这就像是AI在画一幅画,随着时间的推移,画面变得越来越清晰。
-
合成音频和视频:当音频生成完毕后,系统会将其转化为可播放的声音,并与视频结合,形成一个完整的音视频文件。
-
调整和控制:如果你对生成的音频有特殊需求,可以提供额外的提示来进行调整,比如希望音效更强烈或背景音乐更柔和。这使得生成的音频更加符合你的预期。
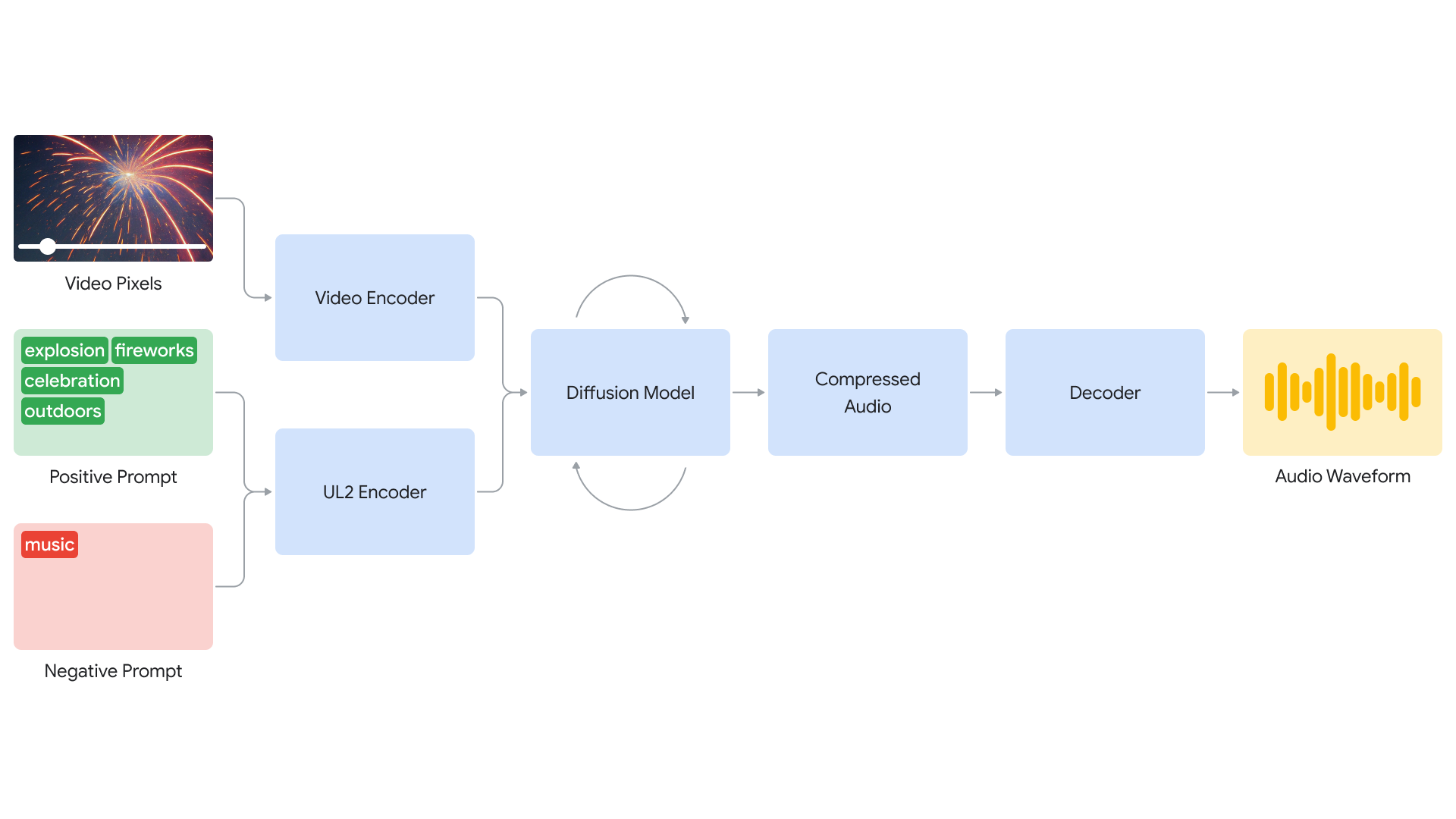 V2A(Video-to-Audio)技术的工作原理涉及多个复杂的步骤,结合了视频处理、文本提示和音频生成。以下是V2A技术的详细工作流程:
V2A(Video-to-Audio)技术的工作原理涉及多个复杂的步骤,结合了视频处理、文本提示和音频生成。以下是V2A技术的详细工作流程:
1. 视频输入编码
首先,V2A系统接收视频输入,并将其编码为压缩表示。这一步骤将视频数据转换为可以被AI模型处理的形式。
2. 文本提示
用户可以提供自然语言文本提示,这些提示用来指导生成的音频内容。例如,用户可以描述需要生成的音效、背景音乐或对话的类型和情感基调。
3. 扩散模型生成音频
V2A采用扩散模型来生成音频。扩散模型是一种逐步优化生成的过程:
- 随机噪声开始:模型从随机噪声开始,通过多个迭代步骤逐步优化噪声,生成目标音频。
- 视频和文本指导:在每个迭代步骤中,扩散模型根据视频的视觉输入和用户提供的文本提示来调整和优化音频。
- 音频精炼:模型逐步减少噪声成分,增加与视频和文本提示匹配的音频特征,最终生成与视频内容同步的音轨。
4. 解码和合成
生成的音频经过解码,转化为可播放的音频波形。这些音频波形然后与原始视频数据结合,形成完整的视听内容。
5. 训练过程
为了提高音频生成的质量,V2A在训练过程中引入了更多的信息:
- AI生成的注释:包括详细的声音描述和对话转录,这些注释帮助模型学习在不同视觉场景中生成特定的音频事件。
- 视频和音频关联:通过将视频、音频和详细注释结合进行训练,模型能够更好地理解和关联不同的视觉和音频信息。
6. 创意控制
V2A提供了创意控制选项:
- 正向提示:用户可以定义正向提示,引导模型生成所需的声音。
- 负向提示:用户可以定义负向提示,避免生成不希望出现的声音。这种灵活性允许用户快速试验不同的音频输出,选择最佳匹配。
V2A 可以为任何视频输入生成无限数量的配乐。可选择定义“积极提示”来引导生成的输出朝向期望的声音,或者定义“消极提示”来引导它远离不希望的声音。
这种灵活性使用户对 V2A 的音频输出有更多控制,可以快速尝试不同的音频输出并选择最佳匹配。
Prompt for audio: A spaceship hurtles through the vastness of space, stars streaking past it, high speed, Sci-fi
提示音频:一艘宇宙飞船在宇宙的浩瀚中飞驰,星星在它身旁划过,高速,科幻视频播放器00:0000:00
Prompt for audio: Ethereal cello atmosphere
提示音频:空灵的大提琴氛围视频播放器00:0000:00
Prompt for audio: A spaceship hurtles through the vastness of space, stars streaking past it, high speed, Sci-fi
提示音频:一艘宇宙飞船在宇宙的浩瀚中飞驰,星星在它身旁飞速掠过,高速,科幻视频播放器00:0000:00
7. 自动化处理
V2A系统无需手动对齐生成的声音与视频,自动处理声音、视觉和时间元素的同步,减少了用户的繁琐工作。
V2A技术发展
尽管V2A(Video-to-Audio)技术已经展示了其巨大的潜力,但DeepMind团队仍在不断改进和完善这一技术。以下是一些当前正在进行的研究方向和改进目标:
1. 音频输出质量改进
V2A技术的音频输出质量依赖于视频输入的质量。如果视频中存在瑕疵或失真,可能会导致生成的音频质量下降。DeepMind正在研究如何在各种视频质量下保持音频输出的一致性和高质量,避免因视频输入质量问题而影响音频效果。
2. 唇同步改进
对于包含对话的视频,唇同步是一个关键挑战。目前,V2A尝试通过输入的对话文本生成与角色唇部动作同步的语音,但有时会出现视频中的口型与生成的语音不完全匹配的情况。DeepMind正在致力于改进这一方面,确保生成的语音与角色的唇部动作完美同步,提升观众的观看体验。
3. 处理视频失真
研究团队正在解决如何在视频出现失真或视频内容超出模型训练数据分布时,仍能生成高质量音频的问题。通过改进模型的鲁棒性和适应性,团队希望V2A能够在更多样化的视频内容下表现出色。
4. 安全与透明性
为了确保V2A技术在实际应用中的安全性和透明性,DeepMind正在进行严格的安全评估和测试。他们采用SynthID工具对所有AI生成的内容进行水印标识,以防止技术滥用。只有在确保安全和可靠的前提下,才会考虑向更广泛的公众开放V2A技术。
官方介绍:https://deepmind.google/discover/blog/generating-audio-for-video/
片绘社区是融合了最新AI绘画功能和交流分享功能的综合性AI绘画网站,包括绘画模型的分享/下载专区。