
Meta FAIR公开发布了多项新的研究成果、模型和数据集,旨在通过开放、合作和卓越的原则,推动AI领域的创新和应用。这些发布的内容包括图像到文本和文本到音乐生成模型、多令牌预测模型以及AI生成语音检测技术等。
更新内容包括4个新公开可用的AI模型和2个额外的研究成果。
1、Meta Chameleon:能同时理解和生成文本与图像的混合模态模型
- 能够结合文本和图像输入,并输出任意组合的文本和图像。
- 公布了Chameleon 7B和34B模型的关键组件,供研究使用。
Chameleon 是由Meta的FAIR团队开发的一系列早期融合的基于令牌的混合模态模型。它可以同时处理图像和文本,并且可以理解和生成这两种类型的数据。换句话说,它可以阅读文字和图片,也可以创作新的文字和图片。Chameleon 可以在处理过程中无缝地在不同的数据类型之间切换。这意味着它可以在生成一段文字后,接着生成一张相关的图片,或者在描述一张图片的同时生成相关的文字。
它通过把图像和文字分解成小块(令牌),然后在一个统一的系统(transformer架构)中处理这些小块,实现了在图像和文字之间的无缝转换和理解。这使得它在许多需要同时处理图像和文字的应用中表现非常出色。
视频播放器
论文:https://arxiv.org/pdf/2405.09818
2、多令牌预测模型:
- 提出了新的训练方法,可以同时预测多个未来词汇,提升模型能力和训练效率。
- 发布了预训练模型供研究使用。
这是一种新的训练大型语言模型的方法,即通过预测多个未来标记来提高模型的效率和性能。这里的“标记”指的是词或者词组成分,而传统的模型通常只预测下一个标记。研究发现,让模型同时预测接下来的多个标记,可以帮助模型更好地学习和理解语言,从而在各种任务,特别是编程和自然语言处理任务上表现更好。
主要的改进点包括:
- 更高的样本效率:模型通过预测多个标记,而不仅仅是下一个标记,可以更有效地学习数据,提高了训练的效率。
- 推理速度快:在实际使用中,这种方法可以使模型的推理速度提高三倍,这对于需要快速响应的应用尤为重要。
- 更好的性能:在编程和自然语言的基准测试中,这种方法训练的模型能解决更多的问题,表现出更强的性能。
简而言之,这项研究通过改变训练语言模型的方式,显著提升了模型处理大规模数据的能力和效率。

论文:https://arxiv.org/pdf/2404.19737
模型下载:https://huggingface.co/facebook/multi-token-prediction
3、JASCO 音乐生成模型
- 一种新的文本到音乐生成模型,能够接受多种输入条件(如特定和弦或节拍)来改进生成音乐的控制。
- 研究论文和示例页面已发布,推后将发布推理代码和预训练模型。
JASCO是一个可以将文本转换为音乐的生成模型。它由希伯来大学和Meta AI的研究人员共同开发,旨在通过结合符号(如和弦、旋律)和音频(如鼓音轨、混音)条件来生成高质量的音乐。
功能介绍
- 文本描述生成音乐:JASCO可以根据用户输入的文本描述生成对应风格的音乐。例如,输入“80年代驾驶流行歌曲,电子鼓和合成器垫在背景中”,它会生成符合这种描述的音乐。
- 局部和全局控制:该模型允许对音乐进行细粒度的控制,比如指定和弦、旋律或者鼓音轨。同时,它也可以根据全局的文本描述生成音乐,使得音乐的生成既有整体风格的把握,又有具体元素的精准控制。
- 多种条件组合:ASCO可以处理多种条件组合,比如同时控制和弦和鼓音轨,以生成更复杂、更符合用户需求的音乐。
例如:你可以告诉JASCO你想要什么样的音乐,比如“一首有电子鼓和合成器垫背景的80年代流行歌曲”。然后,JASCO会根据你的描述生成一段符合这种风格的音乐。
不仅如此,你还可以对音乐的细节进行控制,比如指定某段时间内的和弦变化或者添加特定的鼓点。这样,你不仅能得到一段符合整体描述的音乐,还能在音乐的具体细节上达到你的要求。
 项目地址:https://pages.cs.huji.ac.il/adiyoss-lab/JASCO/
项目地址:https://pages.cs.huji.ac.il/adiyoss-lab/JASCO/
4、AudioSeal:音频水印模型
- 一种专门用于检测AI生成语音的音频水印技术,提升了检测速度和效率。
- 发布了模型和训练代码。
AudioSeal是一种为AI生成的语音添加水印的技术。旨在确保生成的语音在经过编辑后仍能被检测到水印。它的主要特点是高鲁棒性和极快的检测速度,非常适合大规模和实时应用。
功能介绍
- 水印生成:AudioSeal生成器可以在音频信号中嵌入水印。这些水印不仅能标识音频来源,还能包含一个16位的秘密消息。
- 水印检测:AudioSeal检测器可以检测音频中的水印,并在每个样本(每1/16k秒)中输出水印存在的概率。即使音频经过多种编辑(如剪切、混音),它仍能可靠地检测到水印。
- 鲁棒性和速度:AudioSeal在信号质量变化不大的情况下,对多种类型的音频编辑具有高度的鲁棒性。其检测速度比现有的同类模型快两个数量级,适合大规模和实时应用。
例如:你使用AI生成了一段语音或音乐。你希望确保这段作品不会被未经授权的使用或篡改。AudioSeal可以帮助你在作品中嵌入一个看不见的“签名”(水印)。即使有人对你的作品进行编辑,AudioSeal的检测器仍能迅速识别出这个“签名”,并确认作品的来源和完整性。这不仅保护了你的版权,还能跟踪作品的传播和使用情况。
 项目地址:https://github.com/facebookresearch/audioseal
项目地址:https://github.com/facebookresearch/audioseal
5、PRISM数据集:
- 包含来自75个国家的1500名参与者的社会人口统计数据和偏好反馈,旨在提高LLM的反馈多样性和包容性。
- 研究报告展示了PRISM在对话多样性、偏好多样性和福利结果方面的应用。
PRISM Alignment Project 是一个研究项目,旨在通过人类反馈来改进大型语言模型(LLMs)的对齐方式。该项目通过收集来自不同国家和文化背景的参与者对LLMs的反馈,来了解这些模型在主观和多文化背景下的表现。
主要功能
- 广泛的地理和人口参与:PRISM 收集了来自75个国家的1500名参与者的反馈,这些参与者在8,011次对话中与21个LLMs互动。这些反馈帮助研究人员了解不同背景的人对LLMs的不同期望和偏好。
- 细化的个性化反馈:每个参与者的反馈都链接到详细的个人档案,这样研究人员可以探索个性化和样本特征的影响。这有助于研究个体化和文化背景如何影响对LLMs的反馈。
- 多样化和有争议的话题:PRISM 专注于收集关于价值观和有争议话题的对话,这些话题通常在不同人群和文化间存在较大分歧。通过这种方式,研究人员可以更好地理解和改进LLMs在处理复杂和敏感话题时的表现。
- 实证案例研究:项目通过三种案例研究展示了PRISM的实用性:对话多样性、偏好多样性和福利结果。这些研究表明,参与反馈的人的背景和观点对LLMs的对齐标准有显著影响。
PRISM 项目就像一个全球性的意见收集平台,收集来自世界各地的人们对AI聊天机器人的看法和反馈。通过让不同背景的人与这些AI模型对话,PRISM 可以了解到哪些模型表现得更好,以及哪些方面需要改进。
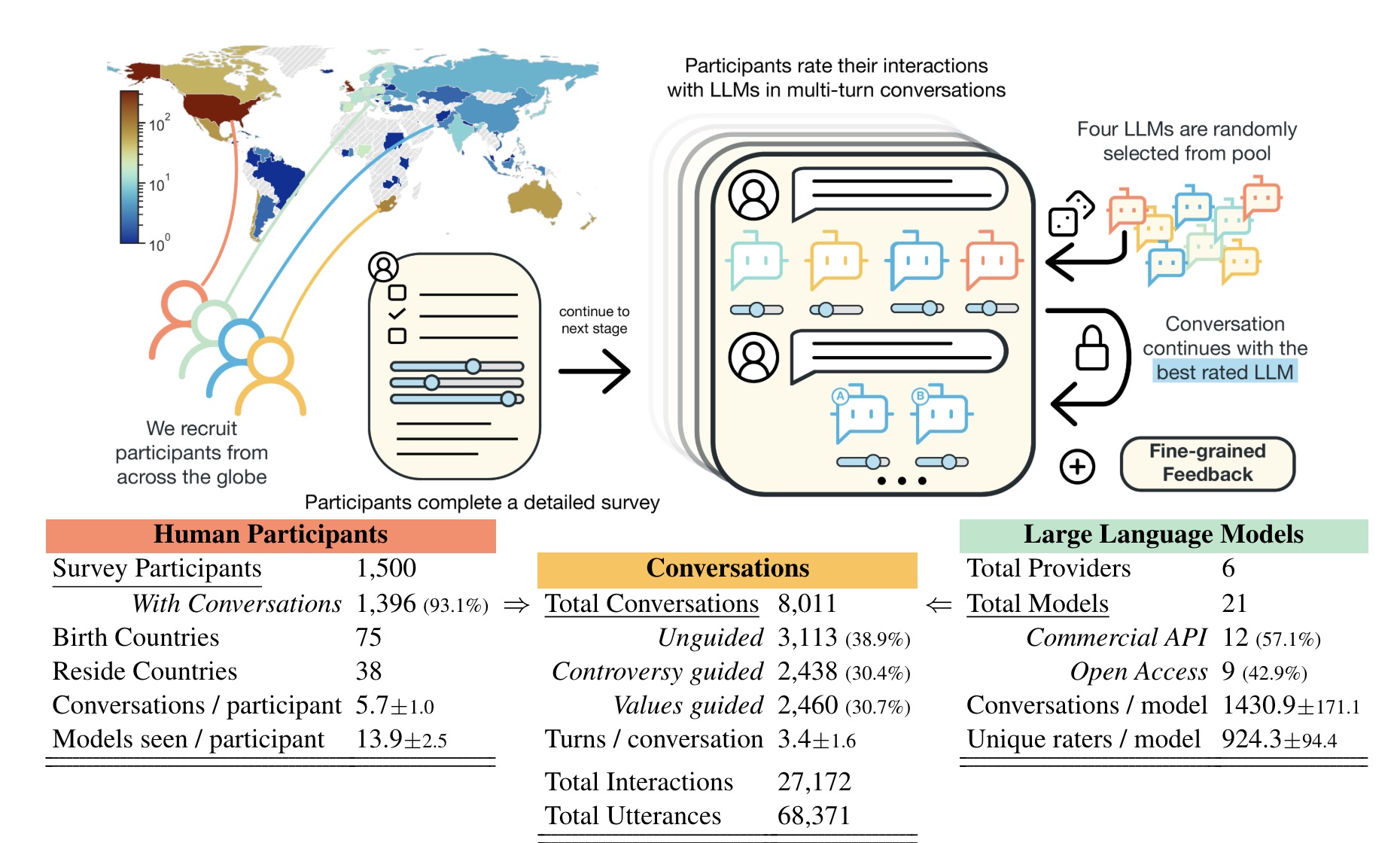
数据集组成
- Conversations(8.01k行):记录了用户与LLMs的对话,每次对话包含多个回合的交互,详细描述了对话内容和模型提供的响应。
- Metadata:包括对话的元数据,如对话ID、用户ID、对话类型等。
- Survey(1.5k行):包含用户对对话的反馈和评分,用于评估模型的表现。
- Utterances(68.4k行):具体的对话轮次,包括用户和模型的每次发言内容。
论文:https://arxiv.org/pdf/2404.16019
数据集:https://huggingface.co/datasets/HannahRoseKirk/prism-alignment
6、衡量和改善文本到图像生成系统中的地理差异
- 开发了“DIG In”自动指标来评估文本到图像模型的地理差异。
- 探索了提高文本到图像生成模型输出多样性的方法。
这项研究的核心目的是确保AI生成的图像能真实反映不同地区的文化和地理特征。为此,专门开发了一个名为“DIG In”的工具,可以自动评估图像生成的地理差异。进行了大规模调查,了解不同地区的人们如何看待这些图像。
- DIG In自动指标:
- 开发了一种名为“DIG In”的自动指标,用于评估文本到图像模型可能存在的地理差异。这些指标帮助识别不同地理区域在图像生成质量上的差异。
- 大规模注释研究:
- 为了理解不同地区的人们对地理表示的感知差异,进行了大规模的注释研究。收集了超过65,000条注释,每个示例收集了超过20条调查回应,涵盖了吸引力、相似性、一致性等方面,并为改进文本到图像模型的自动和人工评估提供了共享建议。
什么是DIG-In?
DIG-In是一个用于评估生成图像在地理区域之间质量、多样性和一致性差异的库。该库由Facebook Research开发,旨在通过使用GeoDE和DollarStreet作为参考数据集,测量文本到图像生成模型的差异。
主要功能
- 生成图像评估:通过一系列脚本生成与特定提示对应的图像,并对这些图像进行评估,以确定不同地理区域间的差异。
- 特征提取:使用InceptionV3和CLIPScore模型提取生成图像的特征,并将这些特征保存为Pickle文件。
- 计算指标:使用提取的特征计算一系列指标,包括精度、召回率、覆盖率和密度(PRDC),以及CLIPScore指标。这些指标用于评估图像生成模型在不同地理区域间的表现。
使用方法
- 生成图像:使用CSV文件中的提示生成图像,每个CSV文件对应一个文件夹,文件夹中的每张图像按照指定的命名方案保存。
- 提取特征:将生成的图像传入脚本中,提取图像特征并保存为Pickle文件。
- 计算指标:使用保存的特征文件计算指标,并生成包含精度、召回率、覆盖率和密度等指标的CSV文件。
想象你有一个AI模型,可以根据描述生成图像。你想知道这个模型在不同国家生成的图像是否有差异,DIG-In可以帮你完成这个任务。它会生成图像、提取图像特征,并计算出图像质量和一致性的指标,帮助你评估和改进模型。

论文:https://arxiv.org/pdf/2405.04457
GitHub:https://github.com/facebookresearch/DIG-In
Meta 官方介绍:https://ai.meta.com/blog/meta-fair-research-new-releases/
Decktopus是一种全新的在线演示工具,让您在最短的时间内打造完美的演示,让您能够专注于演讲的内容,而不必费时费力地操心设计。