
Anthropic发布了其最新的Claude 3.5 Sonnet模型,在研究生水平推理 (GPQA)、本科生水平知识 (MMLU) 和编码能力 (HumanEval) 方面树立了新的行业基准。
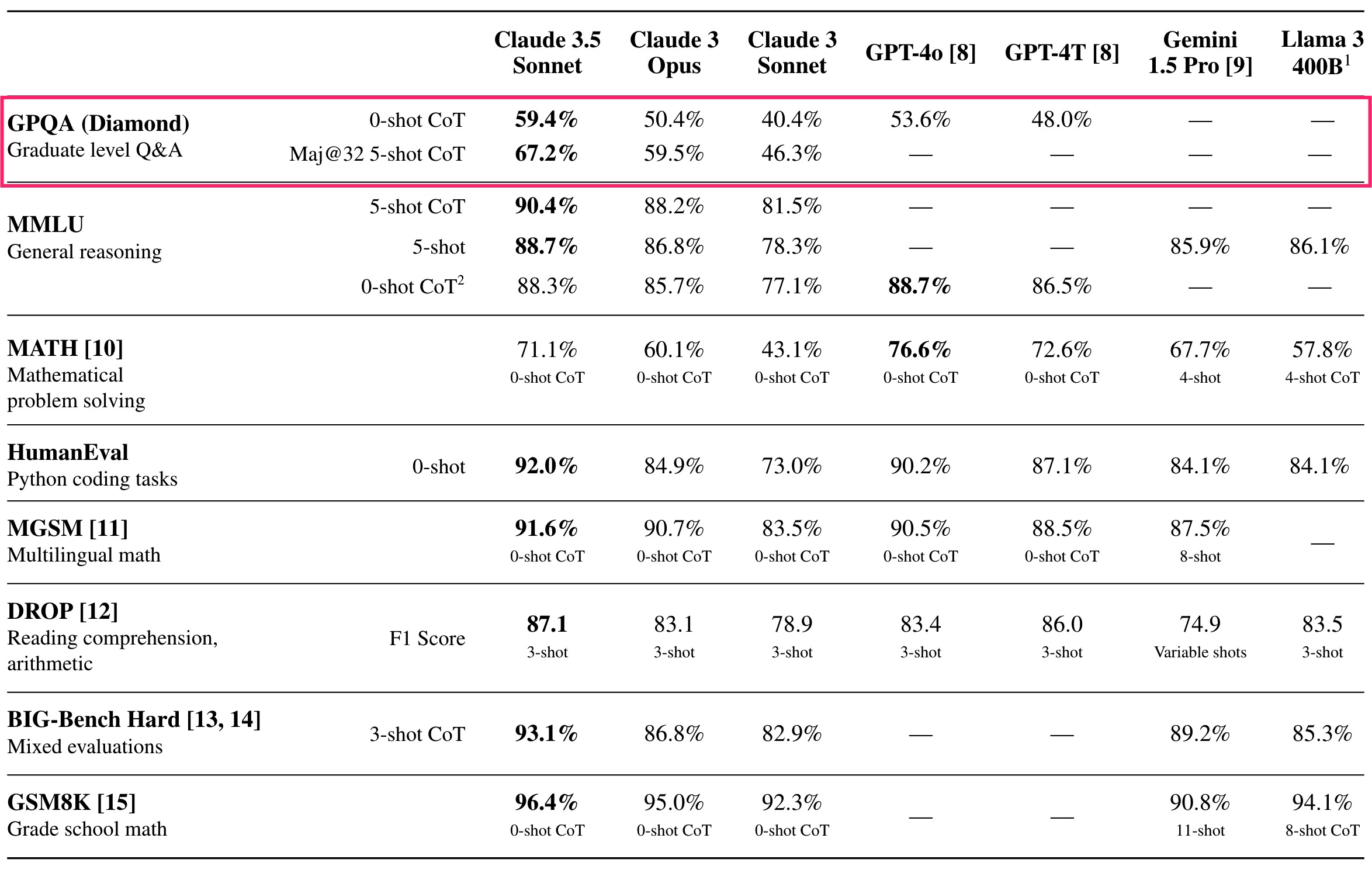
在最新的Claude 3.5 Sonnet 的技术评测报告中,Claude 3.5 Sonnet在GPQA测试中的得分为67.2%,超过了领域内专业博士的水平。这是第一次有大语言模型在GPQA测试中突破了65%的得分。
 GPQA(Graduate-Level Question Answering)是一个旨在评估语言模型在研究生水平科学知识上的问答能力的基准测试。它通常涉及复杂和深奥的问题,需要模型具有较高的推理和知识整合能力。以下是GPQA的一些关键点:
GPQA(Graduate-Level Question Answering)是一个旨在评估语言模型在研究生水平科学知识上的问答能力的基准测试。它通常涉及复杂和深奥的问题,需要模型具有较高的推理和知识整合能力。以下是GPQA的一些关键点:
- 高难度问题:GPQA测试的问题往往涉及研究生水平的内容,涵盖多个科学领域,如物理、化学、生物学等。这些问题通常比一般问答系统中遇到的问题复杂得多。
- 零次推理(0-shot CoT)和多次推理(5-shot CoT):
- 0-shot CoT:模型在没有任何示例提示的情况下直接回答问题。
- 5-shot CoT:模型在看过几个示例问题和答案后再回答新问题。这种方式可以帮助模型更好地理解问题类型和预期答案的格式。
在GPQA(Graduate-Level Question Answering)评估中,Claude 3.5 Sonnet的Maj@32 5-shot CoT得分为67.2%。Claude 3.5 Sonnet的得分显著高于其前代模型Claude 3 Opus(59.5%)和Claude 3 Sonnet(46.3%)。
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
Forefront Chat 是一款免费的 AI 在线聊天机器人,支持多种主流模型.