
Google发布了Gemma 2,这是其下一代开放模型,旨在为研究人员和开发者提供更高性能和效率的AI工具。Gemma 2拥有9B和27B参数规模,相比第一代模型在推理效率和安全性上有显著提升。
- Gemma 2采用全新的架构设计,优化了性能和推理效率。
- 专为在不同硬件环境下实现卓越的推理速度和性能而构建。
- 27B Gemma 2在同类模型中表现最佳,能够与体积两倍的模型竞争。
- 9B Gemma 2超越了同类模型如Llama 3 8B,提供了领先的性能。
- 27B模型在全精度推理时,具备高效运行的能力,显著降低了部署成本。
- 能在单个NVIDIA H100 Tensor Core GPU或TPU主机上实现高效推理。
- Gemma 2在多种硬件上优化了推理速度,在高端桌面、游戏笔记本和云端设置上都能实现高效运行。
- 模型版本:Gemma 2有两个版本,9亿参数和27亿参数,分别有基础版和指令微调版。
- 训练数据:Gemma 2的训练数据量是其前一版本的两倍,27B模型使用了13万亿tokens,9B模型使用了8万亿tokens,主要包括英文、代码和数学数据。
- 许可:与第一版相同,Gemma 2采用宽松的许可,允许再分发、微调、商业使用和派生作品。
Gemma 2 的技术进步
Gemma 2 相较于其前代产品,在多个方面进行了技术升级和改进。以下是其主要的技术进步:
1. 滑动窗口注意力(Sliding Window Attention)
- 描述:在每隔一层使用滑动窗口注意力(局部注意力,覆盖4096个tokens),其他层使用全局注意力(覆盖8192个tokens)。
- 优点:这种混合方法在处理长文本时既能提高生成质量(因为一半的层仍然关注所有tokens),又能部分享受滑动注意力的优势,减少内存和时间消耗。
2. Logit 软封顶(Soft-capping)
- 描述:防止logits过度增长,将其缩放到固定范围内。具体方法是将logits除以最大值阈值(soft_cap),然后通过tanh层,确保它们在(-1, 1)范围内,最后再乘以阈值。
- 优点:保证最终值在(-soft_cap, +soft_cap)区间内,不丢失太多信息,同时稳定训练过程。Gemma 2对注意力层和最终层使用了这种方法,注意力层的logits上限为50.0,最终logits上限为30.0。
3. 知识蒸馏(Knowledge Distillation)
- 描述:使用更大的教师模型训练较小的学生模型,通过丰富的token概率分布提供更有意义的学习信号。
- 应用:在Gemma 2的预训练过程中,9B模型使用知识蒸馏,而27B模型则是从头开始预训练。在训练后阶段,使用教师模型生成的多样化完成数据进行训练,以增强学生模型的表现。
- 优点:这种方法通过减少学生和教师模型之间的训练推理不匹配,显著提升了学生模型的生成质量。
4. 模型合并(Model Merging)
- 描述:将两个或多个LLM合并为一个新模型。Gemma 2使用了一种称为Warp的新合并技术,分三个阶段进行:
- 指数移动平均(EMA):在强化学习(RL)微调过程中应用。
- 球面线性插值(SLERP):在RL微调多个策略之后应用。
- 向初始化线性插值(LITI):在SLERP阶段之后应用。
- 优点:这种技术可以在没有加速器的情况下使用,增强了模型的整体性能。
Gemma 2 的评估结果
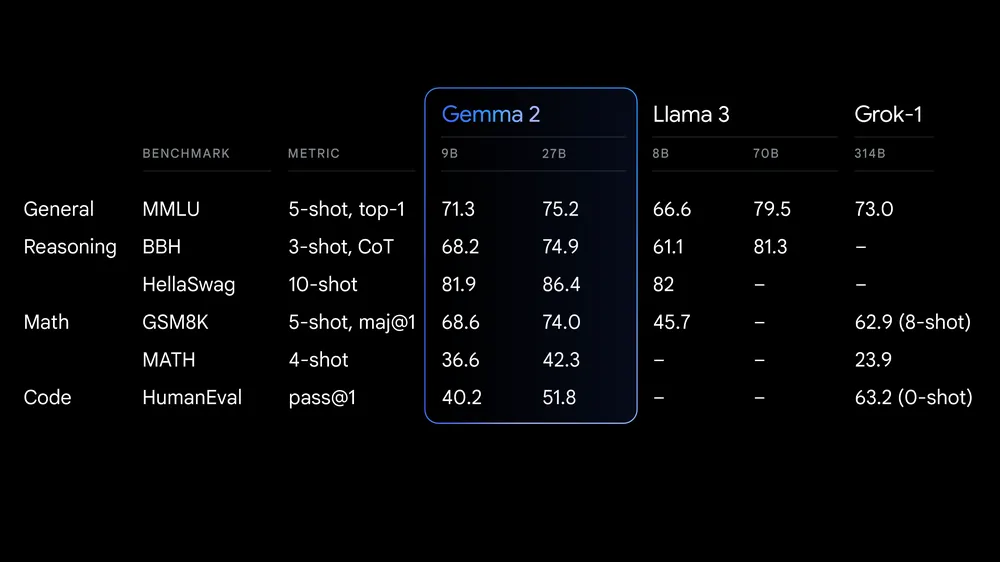
Gemma 2 在多个基准测试中表现出色,与其他开源大型语言模型(LLM)进行了详细比较。以下是其主要评估结果:
大型模型评估结果

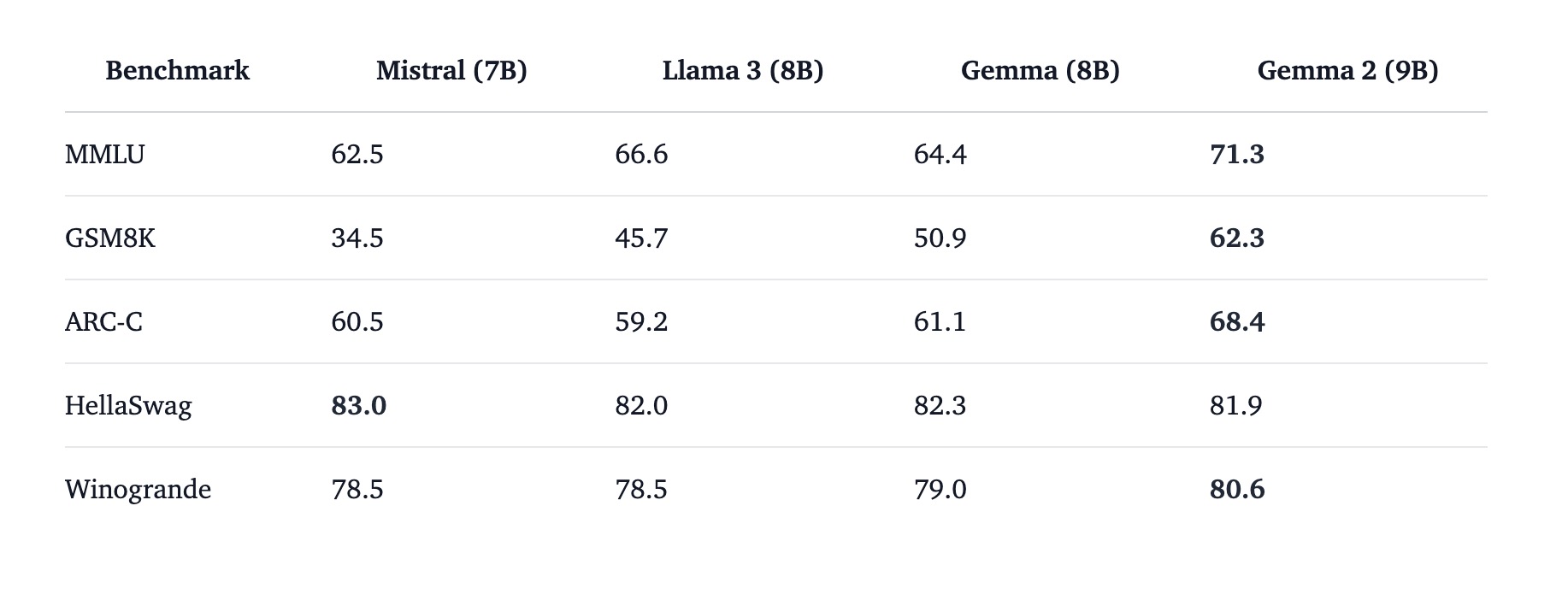
小型模型评估结果
评估分析
- 大型模型评估:在MMLU、GSM8K和ARC-C等基准测试中,Gemma 2 (27B)的表现接近甚至超过了Qwen 1.5 (32B),显示出其强大的综合能力。
- 小型模型评估:在多个基准测试中,Gemma 2 (9B)的表现显著优于Mistral (7B)和Llama 3 (8B),特别是在MMLU和GSM8K测试中,表现尤为突出。
- MMLU (Massive Multi-Task Language Understanding):评估模型在多个任务上的理解能力,Gemma 2在此基准上表现出色。
- GSM8K (Grade School Math 8K):评估模型解决数学问题的能力,Gemma 2在此测试中几乎与Llama 3 (70B)持平。
- ARC-C (AI2 Reasoning Challenge – Challenge Set):评估模型的推理能力,Gemma 2超过了Qwen 1.5 (32B)。
- HellaSwag:评估模型在选择正确描述事件序列方面的能力,Gemma 2表现稳定。
- Winogrande:评估模型在理解和推理常识知识方面的能力,Gemma 2表现优于大多数同类模型。
Gemma 2在多个基准测试中的表现表明,它是目前最先进的开源大语言模型之一。其在理解、推理和解决问题方面的能力得到了显著提升,使其在学术和实际应用中都具有很高的价值。通过这些评估结果,可以看到Gemma 2在开源LLM领域中的强大竞争力和广泛的应用前景。
模型下载:https://huggingface.co/blog/gemma2
在线体验:https://huggingface.co/chat/models/google/gemma-2-27b-it
官方介绍:https://blog.google/technology/developers/google-gemma-2
DoNotPay是一个运用 AI 技术为普通人提供法律服务的AI律师 APP。