测试时间训练(Test-Time Training, TTT)是由斯坦福大学、加州大学和Meta AI共同研究的一种新型的语言模型(LLM)架构,这种模型可以处理更长的文本内容,性能优于现有的Mamba和Transformer模型。
传统的RNN(循环神经网络)在处理长文本时表现不佳,而自注意力机制(如Transformer)尽管表现优秀,但计算复杂度较高。TTT通过在测试时动态调整模型的内部状态来解决这些问题。
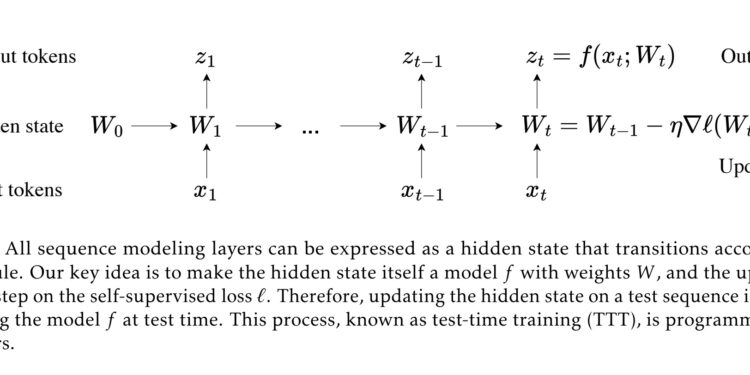
其核心思想是将隐藏状态本身设为一个机器学习模型,并将更新规则设为一个自监督学习步骤。TTT层在处理输入序列时,通过在测试阶段对其隐藏状态进行训练来更新模型参数,从而使模型在测试阶段具备学习能力。
TTT层不仅在语言建模方面表现出色,还可以应用于视频处理,通过密集采样帧提高效果。这种新机制可以取代Transformer中的自注意力层,提升模型效率并加快运行速度。
具体来说,TTT层通过以下方式工作:
- 隐藏状态是一个模型:TTT层的隐藏状态(例如一个线性模型或多层感知机)会随着输入序列的变化进行更新。
- 自监督学习更新规则:在处理每个输入序列时,TTT层会进行自监督学习,即根据输入序列的自监督损失函数对隐藏状态进行梯度下降更新。
- 实时更新:这种更新在测试阶段进行,因此称为“测试时间训练”。每处理一个新输入,TTT层的模型参数都会更新,使其能够更好地适应当前输入。
 TTT 解决了什么问题?
TTT 解决了什么问题?
TTT主要解决了现有序列建模方法在处理长上下文(长序列)时的两个关键问题:
-
性能问题:现有的循环神经网络(RNN)虽然在理论上具有线性复杂度,但在实际应用中,它们在处理长上下文时表现不佳。这是因为RNN的隐藏状态需要在固定大小的状态向量中压缩大量上下文信息,这种压缩方式的表达能力有限。相比之下,TTT层通过在测试阶段对隐藏状态进行训练,提高了其表达能力,使其在处理长上下文时表现更优。
-
计算效率问题:ransformer模型在处理长文本时表现很好,但计算量非常大,尤其是文本越长,计算量增长越快。TTT在保持计算效率的同时,通过自监督学习的方式提高了模型的表现能力。在处理较长文本(比如8k长度的文本)时,TTT模型的计算速度比Transformer更快。
举个简单的例子
假设我们有一个AI系统,它需要阅读并理解一本书。这本书很长,传统的RNN模型在阅读了前半部分后,可能会“记不住”太多信息,导致在后半部分表现不佳。而Transformer虽然能“记住”很多内容,但每次阅读内容越多,需要的计算资源就成倍增长,非常耗时。
而 TTT 就像是你在读书的过程中不断地做新的笔记,不断地进行“自我学习”,根据每一章的内容实时调整你的笔记,从而更好地理解整本书。每读到一页内容,系统都会对自己进行调整和优化,这样它在读到后面的内容时,能更好地理解和记住前面的内容。而且这种自我调整的过程非常高效,不会像Transformer那样需要太多计算资源。
优势
- 长文本处理:TTT模型在处理长文本内容时表现优异,能够更好地捕捉长距离的依赖关系,相比于传统的RNN和Transformer模型,具有更强的表达能力和更高的计算效率。
- 高效计算:通过自监督学习和mini-batch并行计算,TTT模型在计算效率上优于Transformer,尤其是在处理超长文本时能够显著减少计算量。
- 适用广泛:除了在语言建模方面表现出色,TTT层还可以应用于视频处理等其他领域。例如,通过对视频帧进行密集采样和实时学习,TTT可以提高视频处理的效果。
 Test-Time Training (TTT) 的具体方法
Test-Time Training (TTT) 的具体方法
TTT层的关键思想是将隐藏状态设计为一个机器学习模型,并使更新规则成为自监督学习的一步。传统模型只在训练阶段进行学习,而 TTT 允许模型在处理新数据时也能进行学习和调整,从而在处理长文本时表现更好。
- 背景:现在的很多AI模型,比如RNN和Transformer,处理长文本时有一些问题。Transformer虽然表现好,但计算量太大。RNN计算量小,但在处理长文本时效果不好。
- 目标:研究如何在保持计算量小的同时,提高AI模型在长文本中的效果。
解决方案是什么?
- 核心思想:我们设计了一种新的方法,叫做“测试时训练”(Test-Time Training,简称TTT),在处理每一段新文本时,AI模型会在测试时进行自我学习和调整,提升效果。
- 具体做法:创建两种新模型,叫做TTT-Linear和TTT-MLP,分别使用线性模型和两层MLP作为隐藏状态。
具体方法
- 隐藏状态模型化:
- 传统方法:模型有一个隐藏状态,用于记忆文本信息,但这个状态是固定的,不会自我调整。
- TTT方法:把隐藏状态变成一个可以自我学习的小模型,每次处理新文本时,隐藏状态会根据新文本自我调整,类似于再次训练。
- 自我学习和预测:
- 自我学习:自监督学习是一种无需人工标注数据的学习方法。模型通过自己生成“假标签”进行学习和调整。在 TTT 中,自监督学习用于更新隐藏状态,使模型能更好地处理当前输入的数据。这个过程就像在训练模型。
- 预测输出:用调整后的隐藏状态来预测文本的下一个词,提升预测效果。
- 实时更新:每次模型处理新的数据时,它都会进行一次自监督学习,调整自己的参数。这种实时更新的过程在测试阶段进行,使得模型在处理长文本时能不断优化自己的表现。
两种具体实现方法
- TTT-Linear:隐藏状态是一个简单的线性模型。
- 线性模型:输入一些数据,乘以一个权重矩阵,再加上一个偏置,得到输出。这种模型计算简单,但表达能力有限。
- TTT-MLP:隐藏状态是一个两层的多层感知器(MLP)。
- MLP:输入一些数据,经过多层神经元的非线性变换,得到输出。相比线性模型,MLP的表达能力更强,但计算复杂度稍高。
提高计算效率的方法
- 批量处理(mini-batch TTT):
- 传统方法:逐个处理文本中的每一个词,这样做效率低。
- TTT方法:把文本分成小批量,批量处理多个词,提高计算效率。
- 矩阵运算(dual form):
- 传统方法:直接计算每一步的梯度和隐藏状态,计算量大。
- TTT方法:通过矩阵运算,利用现代硬件(如GPU)的高效矩阵乘法,快速计算结果,大幅提高计算速度。
具体例子帮助理解
假设你是一个老师,你有两种教学方法:
- 传统方法:你用一种固定的方法来回答学生的问题,但这种方法在面对大量问题时效果不好。
- TTT方法:每次上课时,你根据学生提出的问题自我调整教学方法,这样能更好地回答学生的问题。
具体来说:
- 隐藏状态模型化:传统方法中,你的教学策略是固定的,不会改变。TTT方法中,你每次根据新问题调整策略,相当于在每次上课时重新学习。
- 自我学习和预测:你根据学生的问题自我调整,然后用调整后的策略回答下一个问题。
- 两种具体实现:
- TTT-Linear:你用一个简单的规则调整策略,这种方法快速但效果可能一般。
- TTT-MLP:你用一个稍复杂的规则调整策略,这种方法效果更好但稍慢。
- 提高效率:
- 批量处理:你一次处理多个问题,提高效率。
- 矩阵运算:利用电脑快速计算答案。
通过这种自我调整和高效计算的方法,你在面对大量问题时表现更好,回答问题更准确。
TTT 和现有方法的比较
1. 性能比较
现有方法的问题
- 循环神经网络(RNN):RNN模型在处理长文本时表现不佳。因为RNN的隐藏状态需要在固定大小的状态向量中压缩大量信息,这限制了它的表达能力。
- Transformer:Transformer在处理长文本时表现优异,但其计算复杂度是二次的(随着文本长度增加,计算量成平方增长),这使得在处理特别长的文本时效率非常低。
TTT的优势
- 表达能力更强:TTT通过自监督学习不断更新隐藏状态,使其在处理长文本时能够更好地捕捉和理解上下文信息。
- 计算效率更高:TTT在保持线性复杂度的同时,优化了计算效率。在8k长度的上下文中,TTT模型的计算速度比Transformer更快,并且在墙钟时间上也匹敌现代RNN(如Mamba)。
2. 计算复杂度比较
现有方法的问题
- RNN:RNN的复杂度是线性的,但其性能在长文本处理中受到限制。
- Transformer:Transformer的复杂度是二次的,即计算量随着输入长度的平方增长,这使得其在处理超长文本时非常耗时。
TTT的优势
- 线性复杂度:TTT保持了线性复杂度,这意味着其计算量随着输入长度线性增长,计算效率更高。
- 优化的计算:通过使用mini-batch和对偶形式,TTT进一步优化了计算效率,显著减少了计算时间和资源消耗。
3. 实时更新能力
现有方法的问题
- RNN和Transformer:传统的RNN和Transformer模型在测试阶段不进行学习和更新,这限制了它们在处理新数据时的适应能力。
TTT的优势
- 实时学习:TTT在测试阶段进行自监督学习,根据新输入数据实时更新模型参数。这使得模型能够更好地适应和处理新的数据,表现更佳。
举例说明
假设我们有一个AI模型需要处理一本非常长的小说:
- RNN:由于RNN的隐藏状态需要在固定大小的向量中压缩大量信息,当小说越长,RNN的表现就越差,因为它“记不住”太多内容。
- Transformer:虽然Transformer能够很好地理解和记住内容,但它的计算量会随着小说长度成平方增长,这使得处理非常长的小说变得非常耗时。
- TTT:TTT模型在处理每一章内容时,通过自监督学习不断调整和优化自己,使其能够实时适应新的内容。在处理长小说时,TTT既能保持较高的计算效率,又能保持优异的性能。
实验结果
为了验证TTT(测试时训练)方法的有效性,本文进行了大量的实验,比较了TTT-Linear和TTT-MLP与现有的Transformer和现代RNN(如Mamba)在不同数据集和不同上下文长度下的表现。以下是实验结果的详细总结:
数据集与设置
- 数据集:
- Pile:一个标准数据集,用于训练和评估大规模语言模型。
- Books3:Pile数据集的一个子集,包含长文本,特别适用于评估模型在长上下文下的表现。
- 模型参数规模:
- 对每个评估设置,实验了四种模型规模:125M、350M、760M、1.3B参数。
- 上下文长度:
- 实验评估了2k、8k、32k的上下文长度。
- 基线模型:
- Transformer:基于Llama架构。
- Mamba:一种现代RNN。
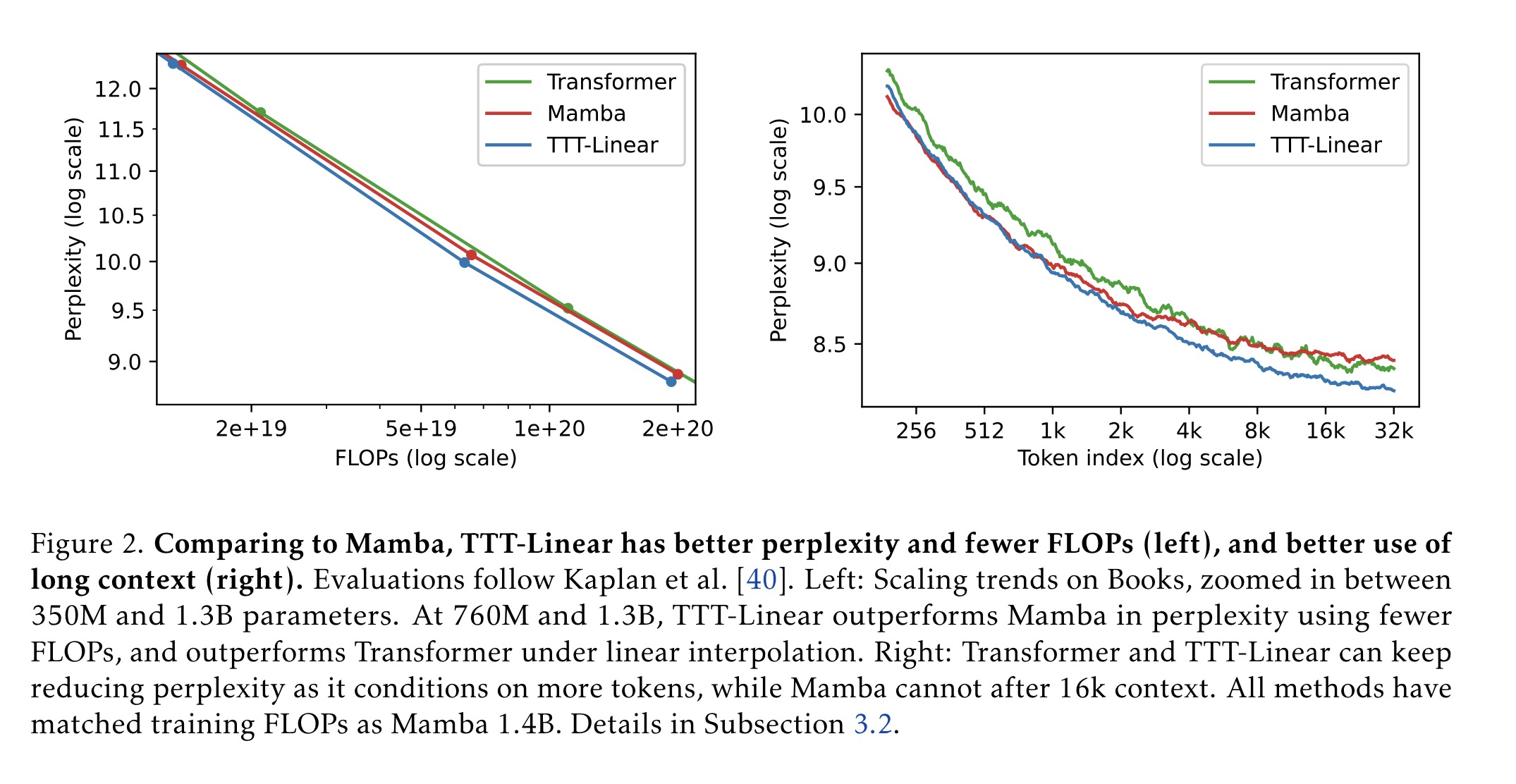
主要实验结果
- 短上下文(2k)上的表现:
- 结果:
- 在2k上下文长度下,TTT-Linear(Mamba架构)与Mamba和Transformer的性能相当。
- TTT-MLP(Mamba架构)在较大FLOP预算下表现稍差,但在每种模型规模下,TTT-MLP的困惑度(perplexity)均优于TTT-Linear,只是额外的计算成本抵消了其优势。
- 结论:
- 在较短上下文下,TTT-Linear的性能与现有方法相当,但TTT-MLP表现略差。
- 结果:
- 长上下文(8k)上的表现:
- 结果:
- 在8k上下文长度下,TTT-Linear(Mamba架构)和TTT-MLP(Mamba架构)的表现显著优于Mamba。
- 即使是TTT-MLP(Transformer架构),在1.3B参数规模时也比Mamba表现更好。
- Transformer虽然在每种模型规模下困惑度依然很好,但其FLOP成本较高。
- 结论:
- 随着上下文长度的增加,TTT层对Mamba的优势逐渐显现。
- 随着上下文长度的增加,TTT层对Mamba的优势逐渐显现。
- 结果:
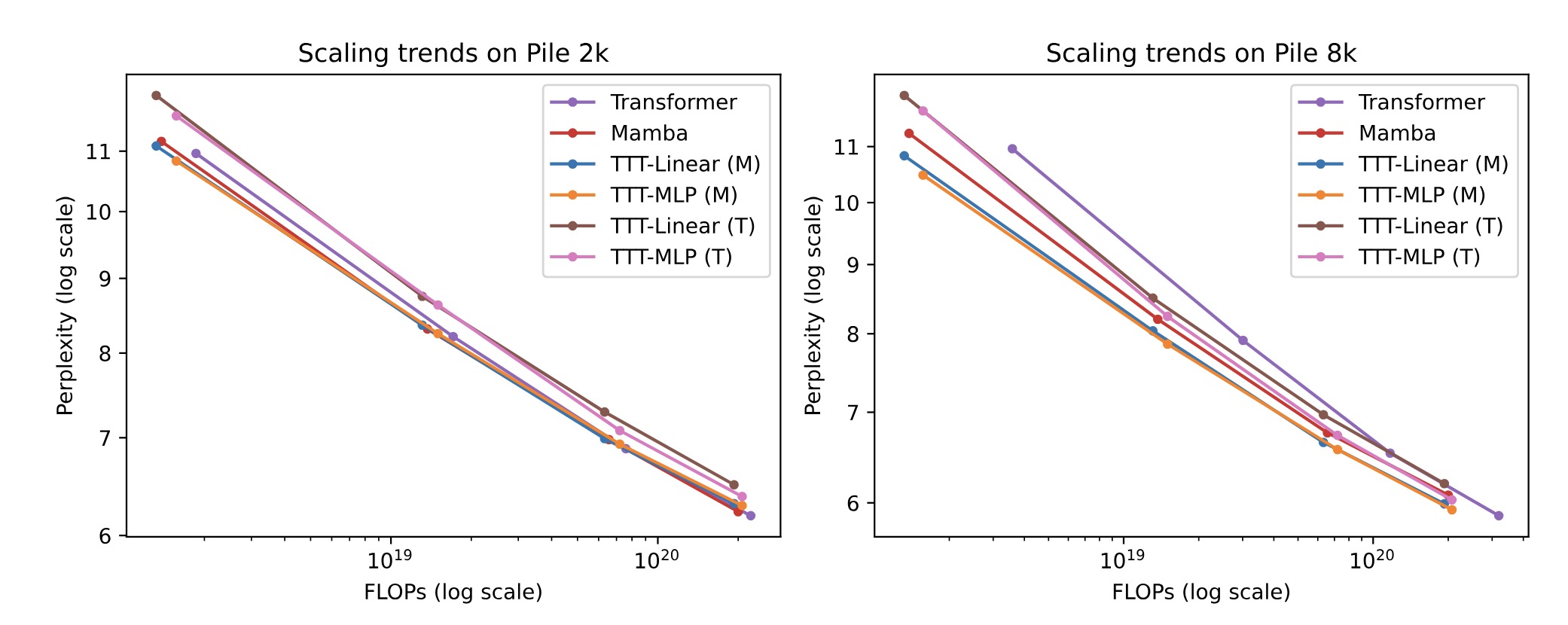
- 超长上下文(32k)上的表现:
- 结果:
- 在32k长度的上下文下,TTT-Linear(Mamba架构)和TTT-MLP(Mamba架构)的表现优于Mamba,尤其是在处理超长文本时,TTT模型不仅在性能上优于Mamba和Transformer,还在计算效率上显著优于Transformer。
- TTT-MLP(Transformer架构)在32k上下文长度下也略优于Mamba。
- TTT-MLP模型在更长的上下文中展示了更强的表现能力,这表明MLP的表达能力在处理复杂长序列数据时具有优势。
- 结论:
- 在处理超长文本时,TTT方法的优势更加明显。
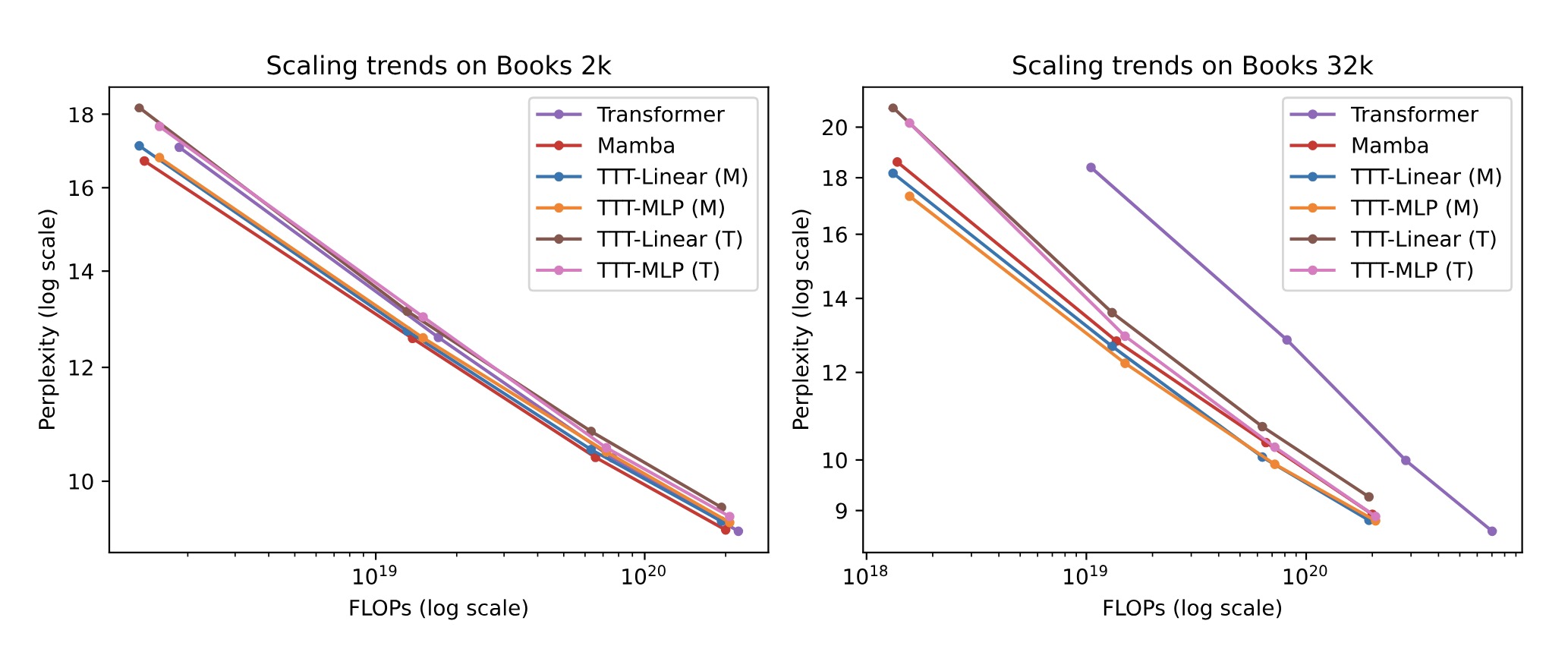
- 在处理超长文本时,TTT方法的优势更加明显。
- 结果:
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Vowel AI是一款可帮助远程团队主持、总结、搜索和共享视频会议而无需任何附加组件的工具。