
Prime Intellect推出了OpenDiLoCo,这是DeepMind分布式低通信(DiLoCo)方法的开源实现和扩展,允许在分布式硬件上进行协作模型开发,旨在促进全球分布式AI模型训练。它通过减少频繁的通信需求,使得在多个、连接不良的设备上训练模型成为可能。
OpenDiLoCo框架可以使多个不同地点和设备上的计算资源协同工作,共同训练和开发AI模型。这意味着不同的计算机和硬件可以在全球范围内分布并通过网络连接起来,一起参与AI模型的训练过程,而不需要将所有计算资源集中在一个地方。这种方法提高了资源利用率,并使得更多人可以参与AI开发。
在两个大洲和三个国家之间训练模型,展示了其有效性,并保持了90-95%的计算利用率。
视频播放器
00:00
00:00
工作原理
1. DiLoCo算法原理
DiLoCo (Distributed Low-Communication) 是一种针对大规模语言模型的分布式低通信训练方法。其核心思想是通过减少工作节点间的通信频率,降低带宽需求,从而实现高效的全球分布式训练。
2. 本地SGD算法
DiLoCo算法采用本地SGD (Stochastic Gradient Descent) 算法,结合两个优化器进行训练:
- 内外部优化算法
- 内部优化:每个工作节点独立使用本地的 AdamW 优化器进行多次权重更新。
- 外部优化:每约500次更新后,算法使用 Nesterov 动量优化器进行外部优化,同步所有工作节点的伪梯度(所有本地梯度的总和)。
这种方法显著减少了通信频率(最多可减少500倍),从而降低了分布式训练的带宽需求。
 3. 工作步骤
3. 工作步骤
初始化
- 模型副本:创建两个模型副本,一个用于本地更新(主模型),另一个保留原始权重(副本模型)。
- 优化器:初始化内部优化器(如AdamW)和外部优化器(如SGD with Nesterov momentum)。
训练过程
- 本地更新:
- 每个训练步长内,使用内部优化器对主模型进行本地更新。
- 内部优化器在每个步长结束时调用,用于更新模型参数。
- 伪梯度计算:
- 在特定的本地步数后,计算伪梯度。伪梯度通过减去当前主模型参数和副本模型参数得到。
- 伪梯度同步:
- 使用all-reduce操作在所有工作节点间同步伪梯度,平均化所有节点的伪梯度。
- 外部更新:
- 使用外部优化器更新副本模型参数,将其与伪梯度进行合并。
- 更新后的副本模型参数再次作为新的副本进行存储,以备下一次伪梯度计算使用。
伪代码示例
for batch, step in enumerate(train_loader):
... # 损失计算
inner_optimizer.step() # 内部优化器更新
if step % local_steps == 0: # 每 local_steps 步长计算一次伪梯度并同步
for old_param, param in zip(original_params, model.parameters()):
param.grad = old_param - param.data
dist.all_reduce(tensor=param.grad, op=dist.ReduceOp.AVG)
param.data = old_param
outer_optimizer.step() # 外部优化器更新
original_params = [p.detach().clone() for p in model.parameters()]
4. Hivemind实现
- DHT (Distributed Hash Table):使用分布式哈希表在工作节点间传输元数据和同步信息,减少网络通信的复杂性。
- 自动同步:通过Hivemind API实现自动化的节点间通信和同步,简化实现过程。
Hivemind代码示例
from hivemind.dht.dht import DHT
from open_diloco import DiLoCoOptimizer
optimizer = DiLoCoOptimizer(
batch_size, learning_rate_scheduler, DHT(),
inner_optimizer, outer_optimizer, model.parameters()
)
for batch in train_dataloader:
model(batch).loss.backward()
optimizer.step()
optimizer.zero_grad()
5. 性能优化
- 混合精度训练 (Mixed Precision Training):在训练过程中使用FP16进行梯度计算,进一步减少通信量而不影响模型性能。
- 全归约 (All-Reduce):使用FP16进行伪梯度的全归约操作,降低通信时间。
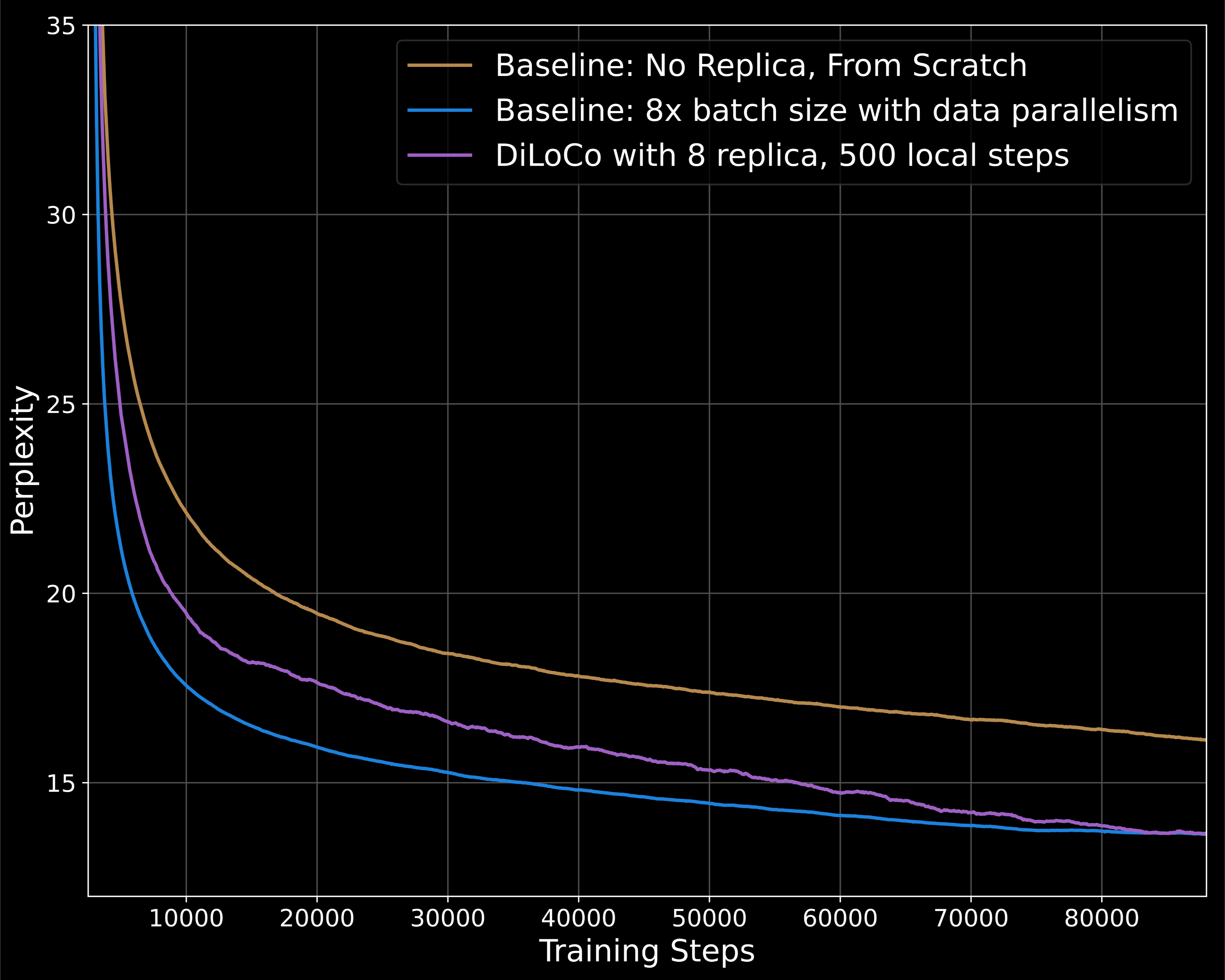
实验结果
1. 150M参数模型的训练结果
- 实验设置:使用C4数据集进行语言建模任务,训练了一个150M参数的模型。
- 性能对比:
- DiLoCo的8个副本显著优于没有副本的基线。
- 在相同计算预算下,DiLoCo的性能与使用8倍批处理大小的更强基线相匹配,尽管其通信需求降低了500倍。
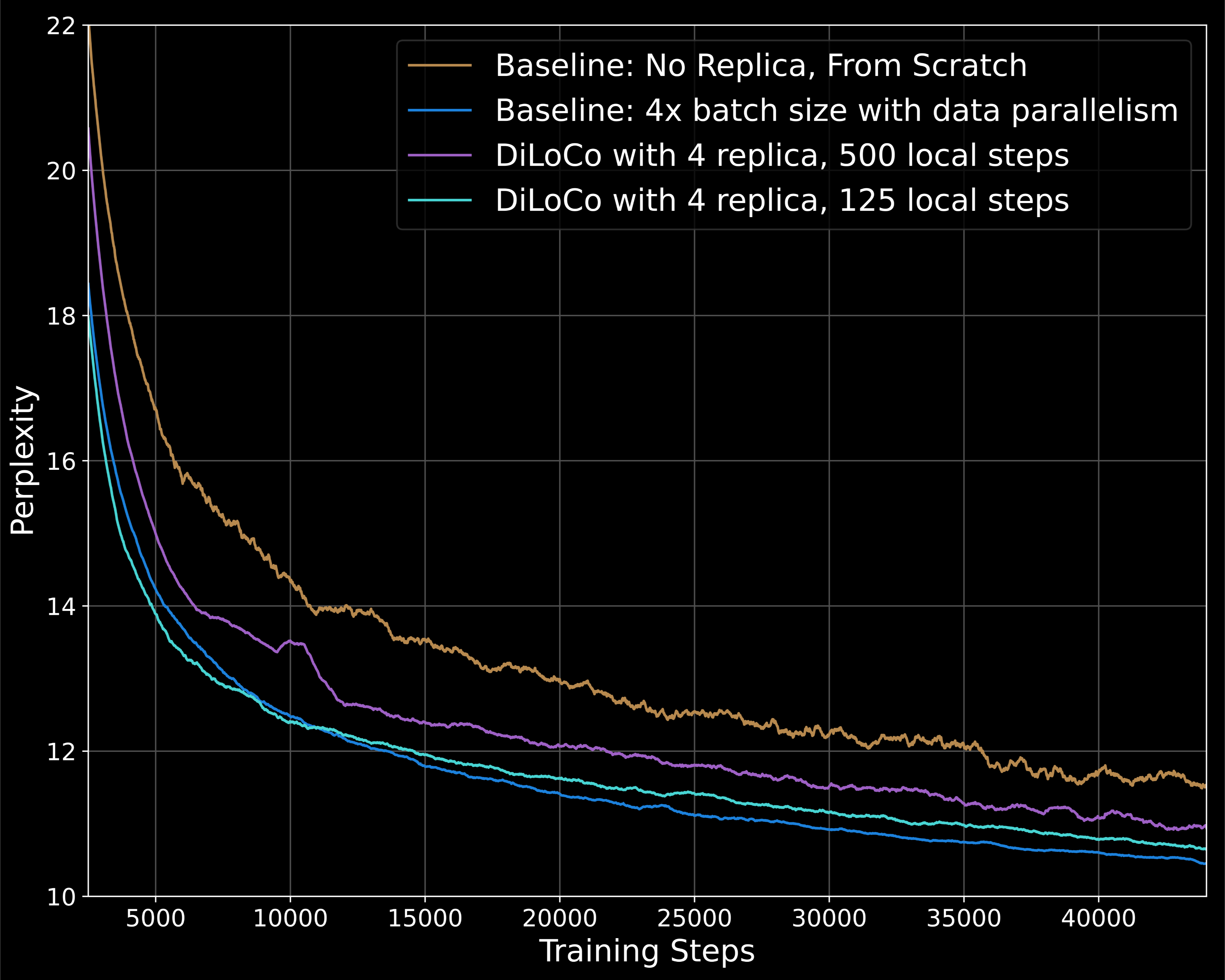
 2. 1.1B参数模型的扩展实验
2. 1.1B参数模型的扩展实验
- 实验设置:
- 使用1.1B参数模型进行实验,采用与TinyLlama相同的超参数,总批处理大小包含8M个token(批处理大小为8192,序列长度为1024)。
- 训练步数设定为44k步(由于较大的批处理大小,较前一次实验训练步数减少一半)。
- 结果对比:
- 在每500步同步一次的设置下,早期训练阶段的收敛效果较差,但在后期训练中有所改善,可能在进一步训练至88k步时达到基线水平。
- 在每125步同步一次的设置下,早期训练阶段的收敛效果更好,性能几乎匹配更强的基线,同时通信需求减少了125倍。
 3. 全球分布式训练实验
3. 全球分布式训练实验
- 实验设置:
- 节点分布:使用四个DiLoCo工作节点,每个节点配备8个H100 GPU,节点分别位于加拿大、芬兰和美国两个不同的州。
- 网络带宽在127至935 Mbit/s之间,梯度在FP16中进行全规约。
- 训练设置:使用1.1B参数模型,500步的本地步长,FP16进行梯度全归约。
- 训练性能:
- 由于通信时间的显著减少,各节点的计算利用率达到90-95%,通信瓶颈只占训练时间的6.9%。
- 在训练过程中,最快的工作节点存在一定的空闲时间,未来将通过探索异步设置来减少此问题。
- 通过这种方式,OpenDiLoCo实现了在全球范围内的分布式低通信训练,使得大规模模型的训练更加灵活和高效。
 4. 效率和性能分析
4. 效率和性能分析
- 消融研究:
- 重点研究了DiLoCo算法随工作节点数量和计算效率的扩展性。
- 证明了DiLoCo伪梯度在FP16中的全规约效果没有性能下降。
结论与未来方向
- 成功复现了DiLoCo的主要实验结果,并将方法扩展到原始工作的三倍参数规模。
- 展示了DiLoCo在真实环境中的应用能力,验证了其在全球范围内高效训练模型的潜力。
- 未来工作将致力于将DiLoCo扩展到更大模型和更多分布式工作节点,并探索模型合并技术以提高稳定性和收敛速度。
详细介绍:https://www.primeintellect.ai/blog/opendiloco
论文:https://arxiv.org/abs/2407.07852
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
Hotpot.ai 是一个可让您在线创建和编辑图像,可以使用它来制作logo、图标、插图、漫画、模板等设计的网站。