
Mistral 通过 Mamba 2架构训练了一个7B 的代码模型:Codestral Mamba,以及新推出一个与 Mistral 7B 相同的架构的数学推理和科学发现的模型:Mathstral 7B
Codestral Mamba超越了 DeepSeek QwenCode,成为小于 10B 参数的最佳模型,并且可以与 Codestral 22B 竞争,并且支持256K的上下文。
与传统的Transformer模型不同,Mamba模型在处理时间上更高效,并且可以处理无限长度的输入序列。用户可以免费使用、修改和分发该模型,适用于各种代码相关的应用场景。
Codestral Mamba 具有以下特点:
-
线性时间推理:Mamba 模型在推理时间上具有线性时间优势,这使得它可以更高效地处理大规模输入数据。
-
无限长度序列建模:理论上可以处理无限长度的序列,使其在处理长文本或代码时表现出色。
-
高级代码和推理能力:该模型专门针对代码生产力进行了训练,具备高级的代码理解和推理能力,可以在代码相关任务中表现优异。
-
高效上下文检索:在上下文检索能力测试中,Mamba 模型能够处理多达 256k tokens 的上下文,适合需要处理大量上下文信息的应用场景。
-
多平台部署:
- 支持通过 mistral-inference SDK 部署,该 SDK 依赖于 Mamba 的 GitHub 仓库中的参考实现。
- 也可以通过 TensorRT-LLM 部署,并计划在 llama.cpp 中提供本地推理支持。
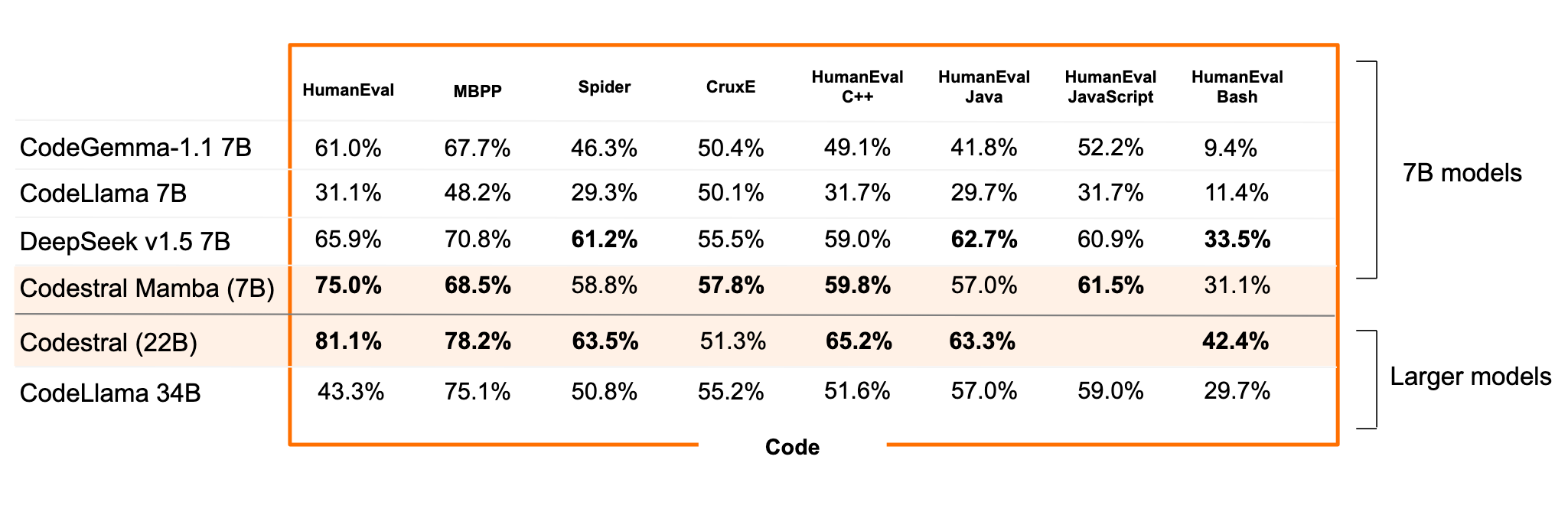
与其他开源模型对比,Codestral Mamba 的性能如下:
- CodeGemma 1.1 7B:在大多数测试中,Codestral Mamba 表现更好,特别是在 HumanEval 和 HumanEval C++ 测试中。
- CodeLlama 7B:Codestral Mamba 明显优于 CodeLlama 7B,特别是在 HumanEval 和 MBPP 基准测试中。
- DeepSeek v1.5 7B:尽管 DeepSeek 在某些基准上表现较好,但总体而言,Codestral Mamba 在 HumanEval 和 HumanEval C++ 中表现更为突出。
- Codestral 22B:相比于更大的 Codestral 22B,Mamba 在一些测试中略逊一筹,但在 HumanEval 和 HumanEval Bash 中表现依然优异。
- CodeLlama 34B:Codestral Mamba 的表现超过了 CodeLlama 34B 在多数测试中的结果。
官方介绍:https://mistral.ai/news/codestral-mamba/
模型下载:https://huggingface.co/mistralai/mamba-codestral-7B-v0.1
Mathstral 的特点:
-
高效数学推理:专为处理复杂、多步逻辑推理的高级数学问题而设计,在数学和科学领域表现出色,能够处理复杂的多步推理问题,如数学证明和复杂的科学计算。
-
大上下文窗口:拥有32k的上下文窗口,能够处理和理解更大范围的输入信息,对于复杂问题和长文本推理非常有用。
-
先进的性能:
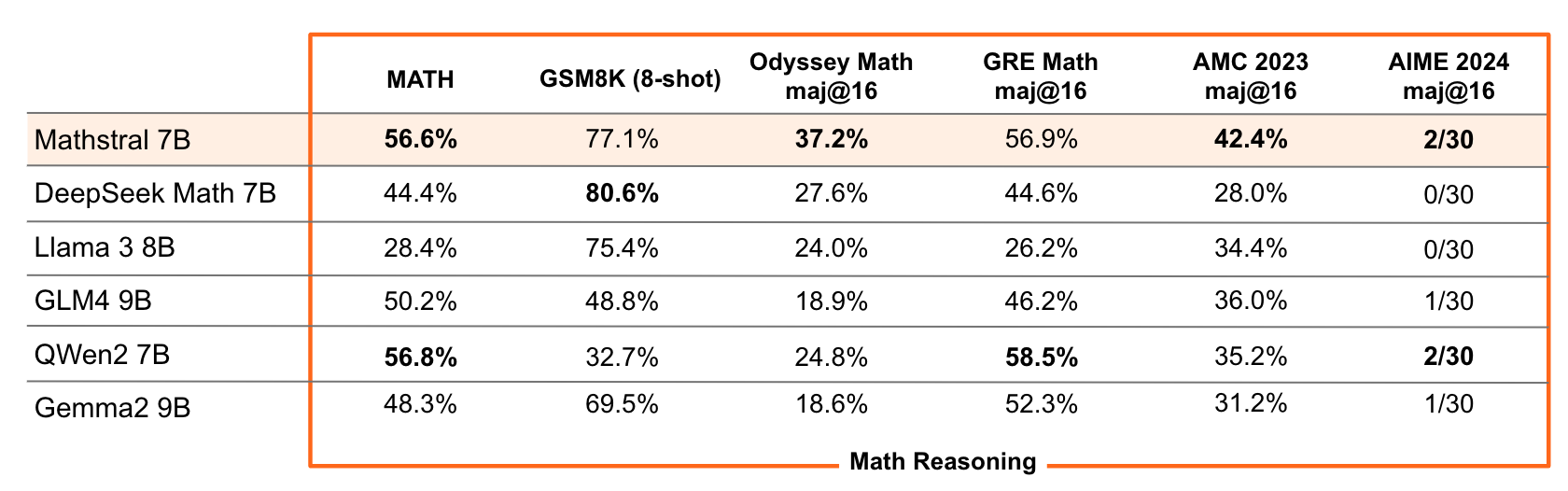
- 在各种行业标准基准测试中表现优异,例如在MATH测试中取得56.6%的成绩,在MMLU测试中取得63.47%的成绩。
- 使用多数投票方法时,Mathstral 7B在MATH测试中的得分可以提高到68.37%,在64个候选者中使用强奖励模型时得分为74.59%。
-
模型架构:Mathstral 7B 构建在Mistral 7B的基础上,继承了其强大的基础能力和架构优势。该模型具有7B参数,
-
定制和微调能力:
- 用户可以通过mistral-inference和mistral-finetune工具进行模型部署和微调,以满足特定需求。
- 提供灵活的微调能力,用户可以根据具体应用场景对模型进行优化。
 官方介绍:
官方介绍:
HomeCourt是一款搭配AI人工智能的篮球训练APP应用程序,可以帮助任何人变得更好。私人篮球教练始终与您同在,捕捉您的表现、统计数据和进步,引导您更上一层楼。