Baptiste Adrien 在X上介绍了其正在使用 @vercel 和 @nextjs 技术,开发一个 RAG(检索增强生成)系统,他分享整个开发的流程。
详细直观的介绍了RAG(检索增强生成)的基本原理和构建框架。
视频播放器
00:00
00:00
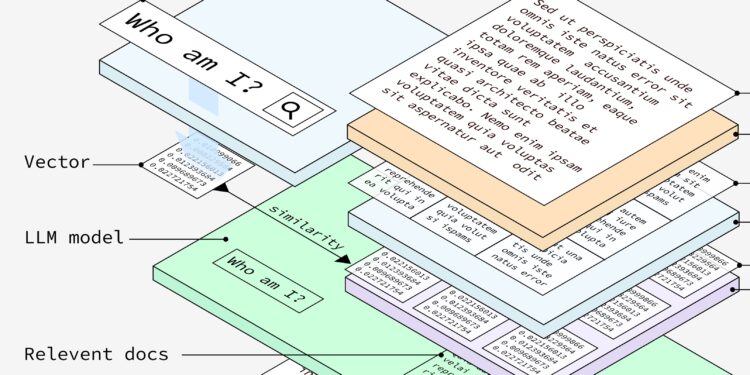
1. 文档处理
开发 RAG 系统的第一步是准备文档。这些文档将作为系统的基础数据。

2. 文本提取
接下来,使用 OCR(光学字符识别)模型处理文档。如果需要,该模型可以从图像中提取文本。

3. 文本分块
将提取的文本分解为更小、更易管理的部分。这种分块处理有助于提高后续处理和分析的效率。

4. 嵌入模型
将每个文本块通过嵌入模型转换为向量。这些向量是捕捉文本语义含义的数字表示。
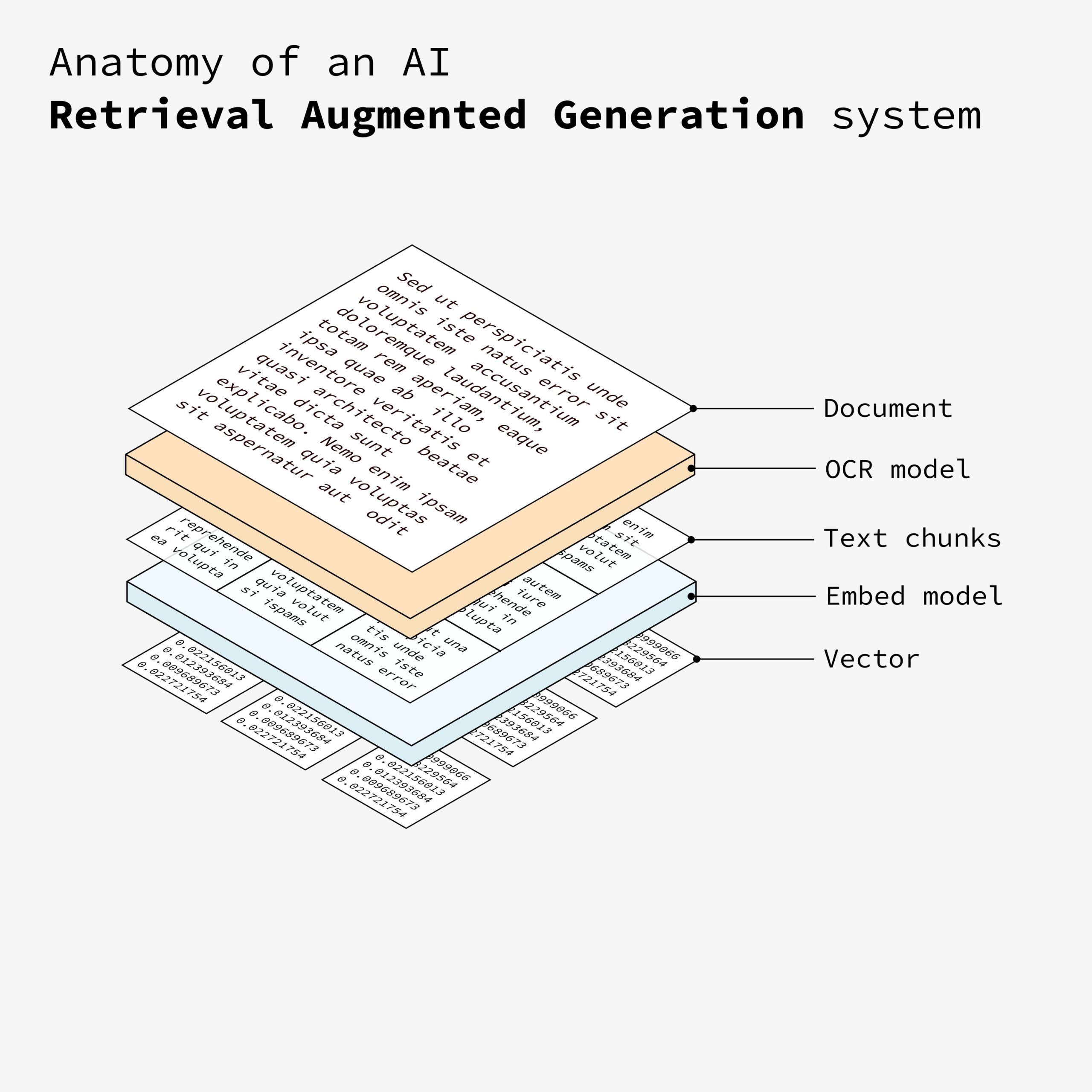
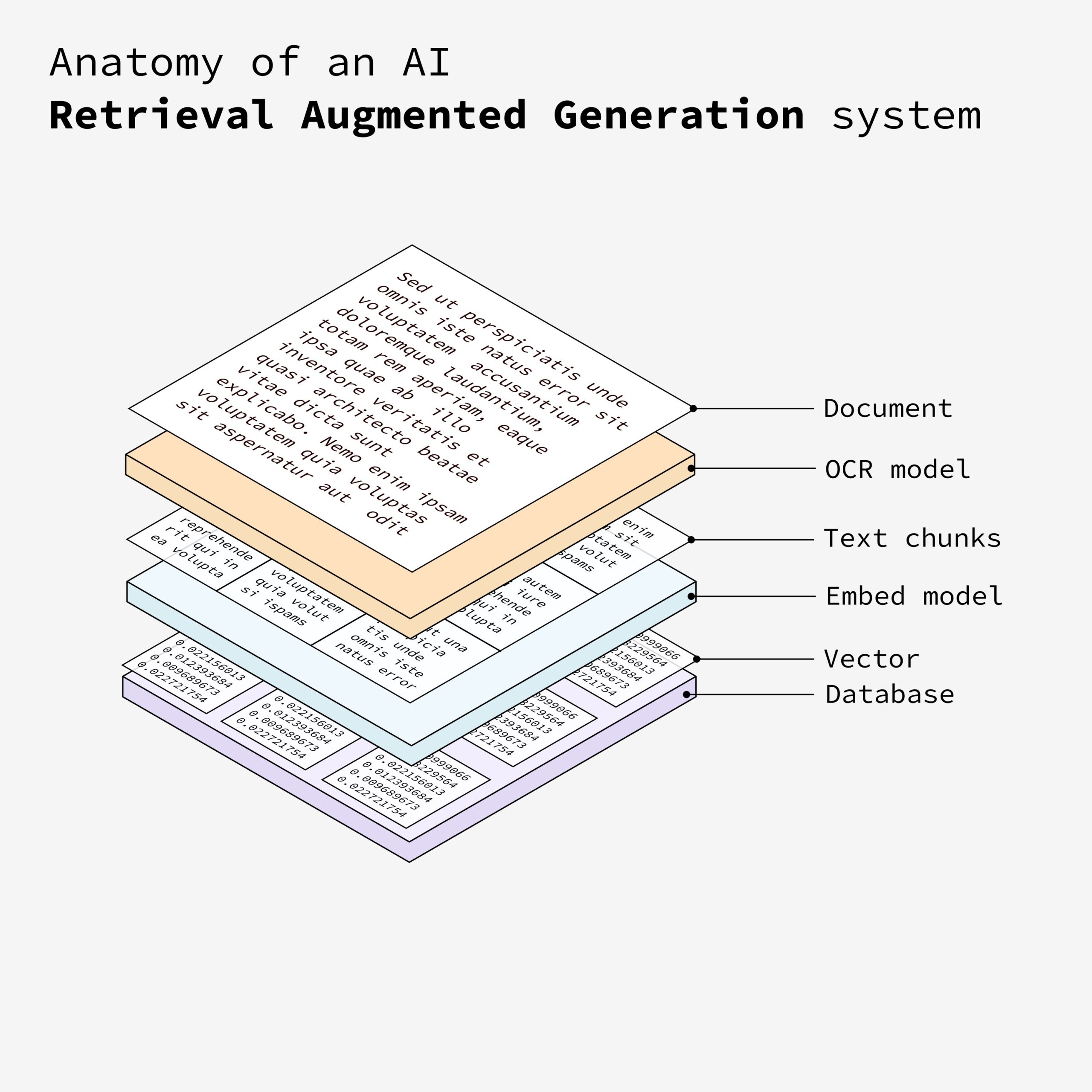
5. 向量存储
将生成的向量存储在一个向量数据库中。这个数据库使系统能够根据语义相似性高效地检索相关信息。
6. 用户输入问题
用户通过系统输入问题。这个问题将用于从向量数据库中检索最相关的信息。
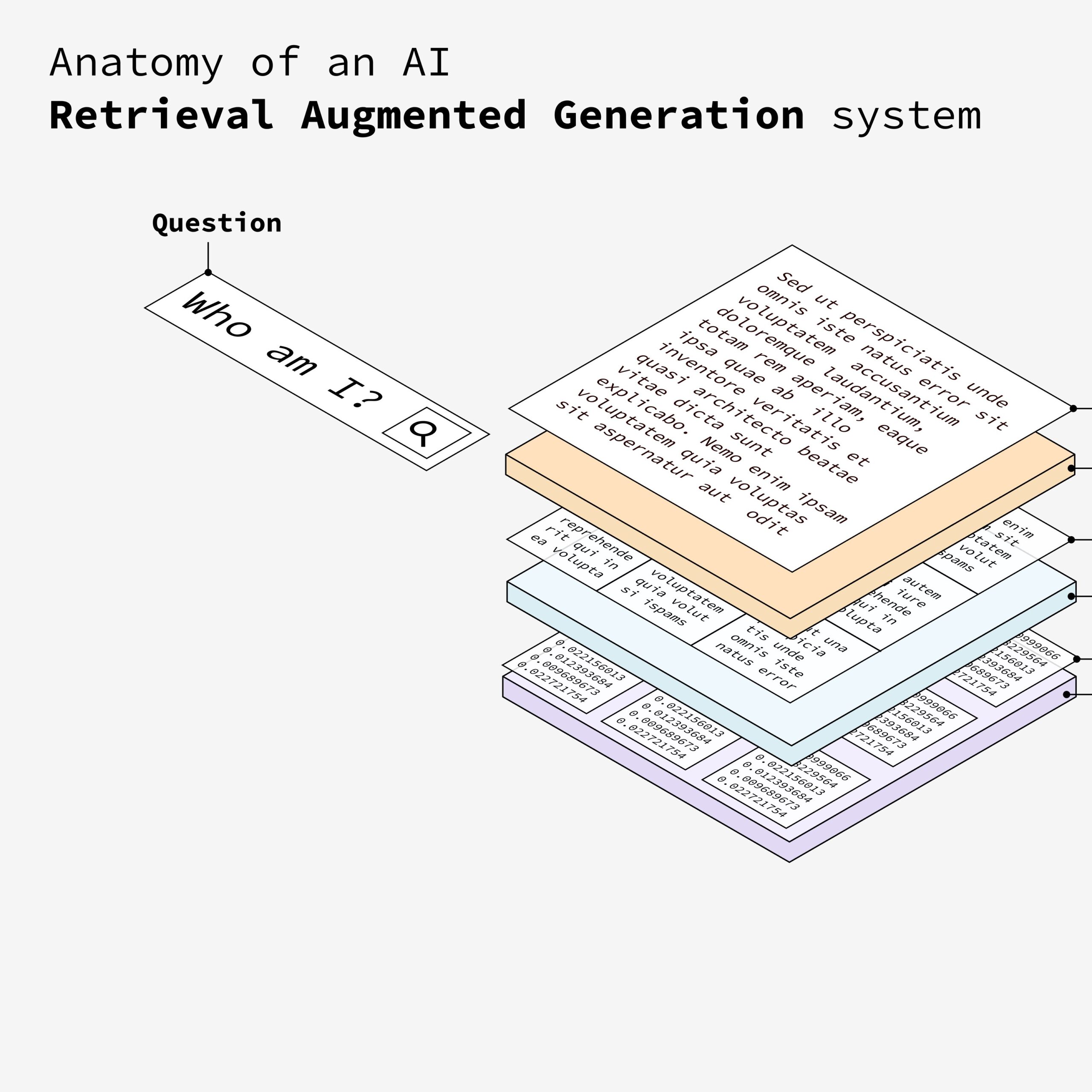
7. 问题嵌入
将用户输入的问题使用相同的嵌入模型进行处理,确保问题和文本块都在同一个向量空间中。
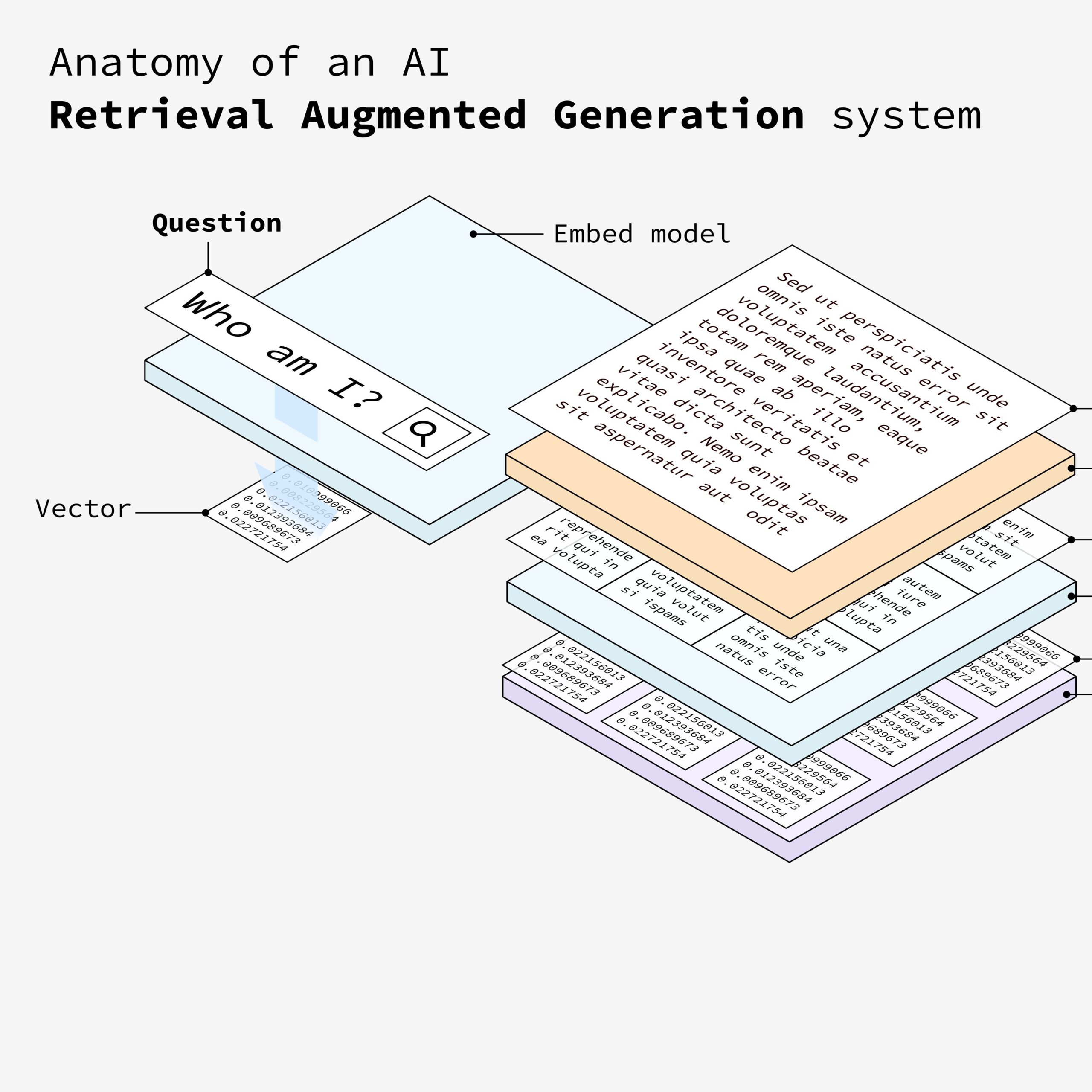
8. 向量匹配
系统根据相似性将嵌入的问题与数据库中的向量进行匹配,并检索出最相似的文本块。
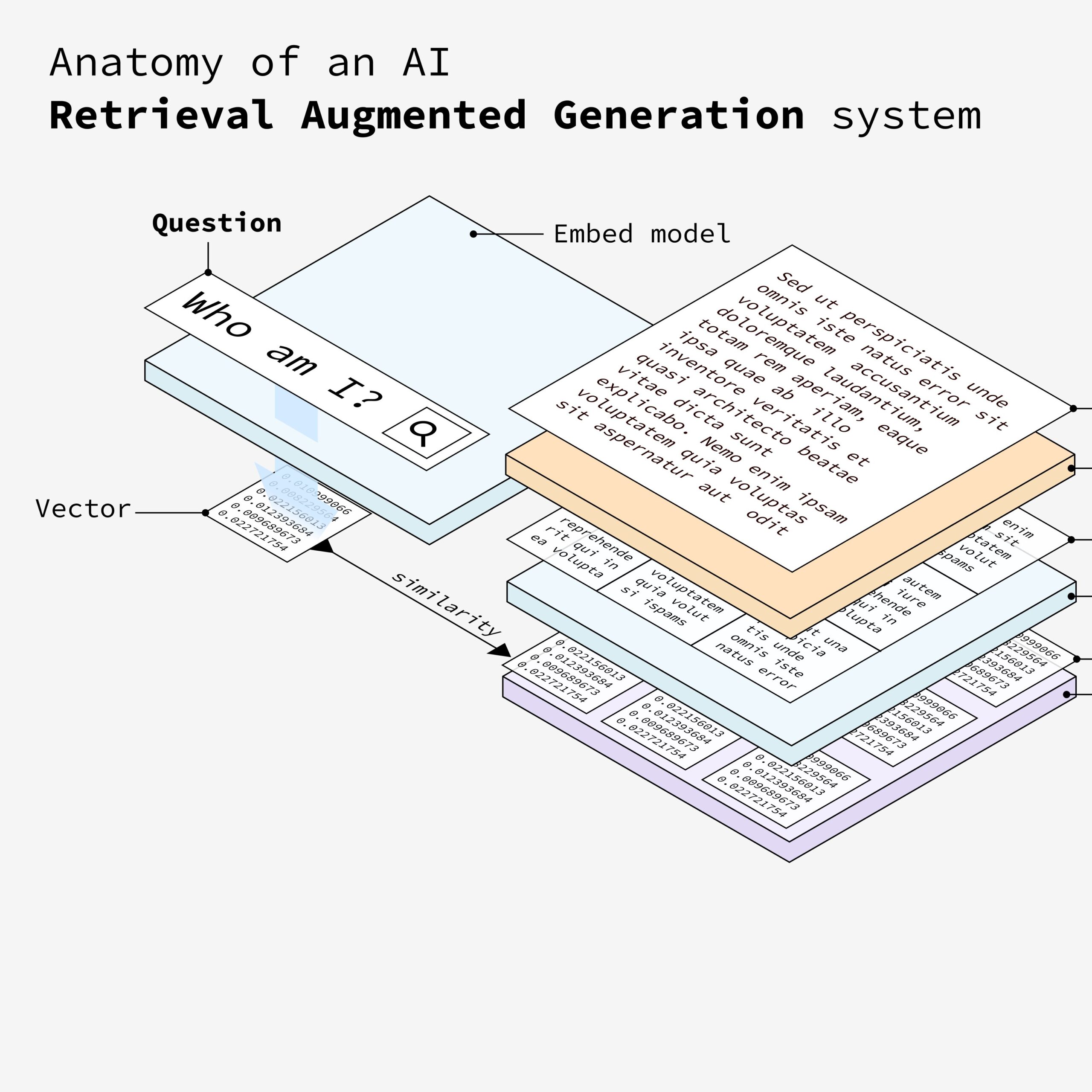
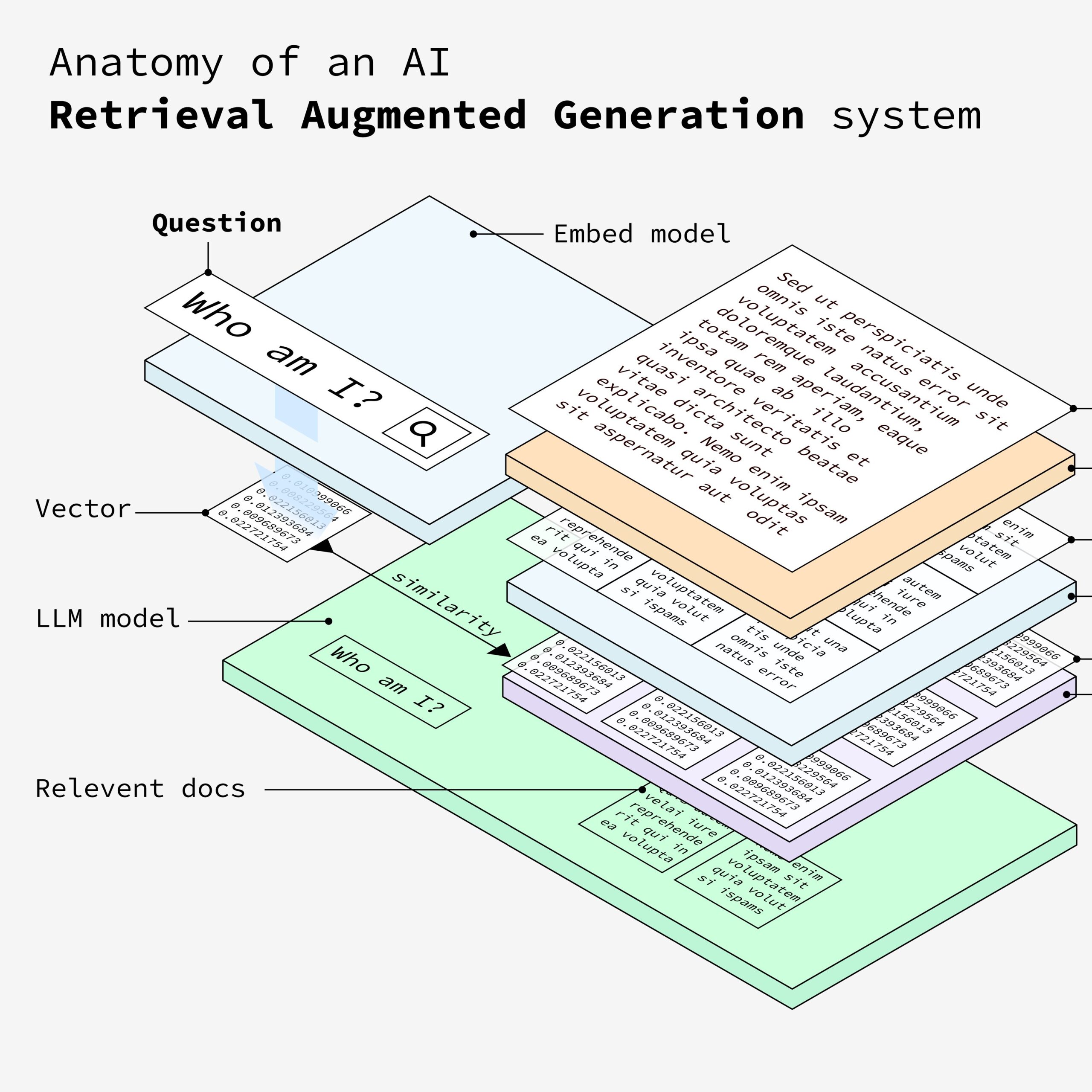
9. 信息处理
系统根据相似度得分检索最相关的文档。然后,LLM(大语言模型)处理这些相关信息,生成对用户问题的详细回答。
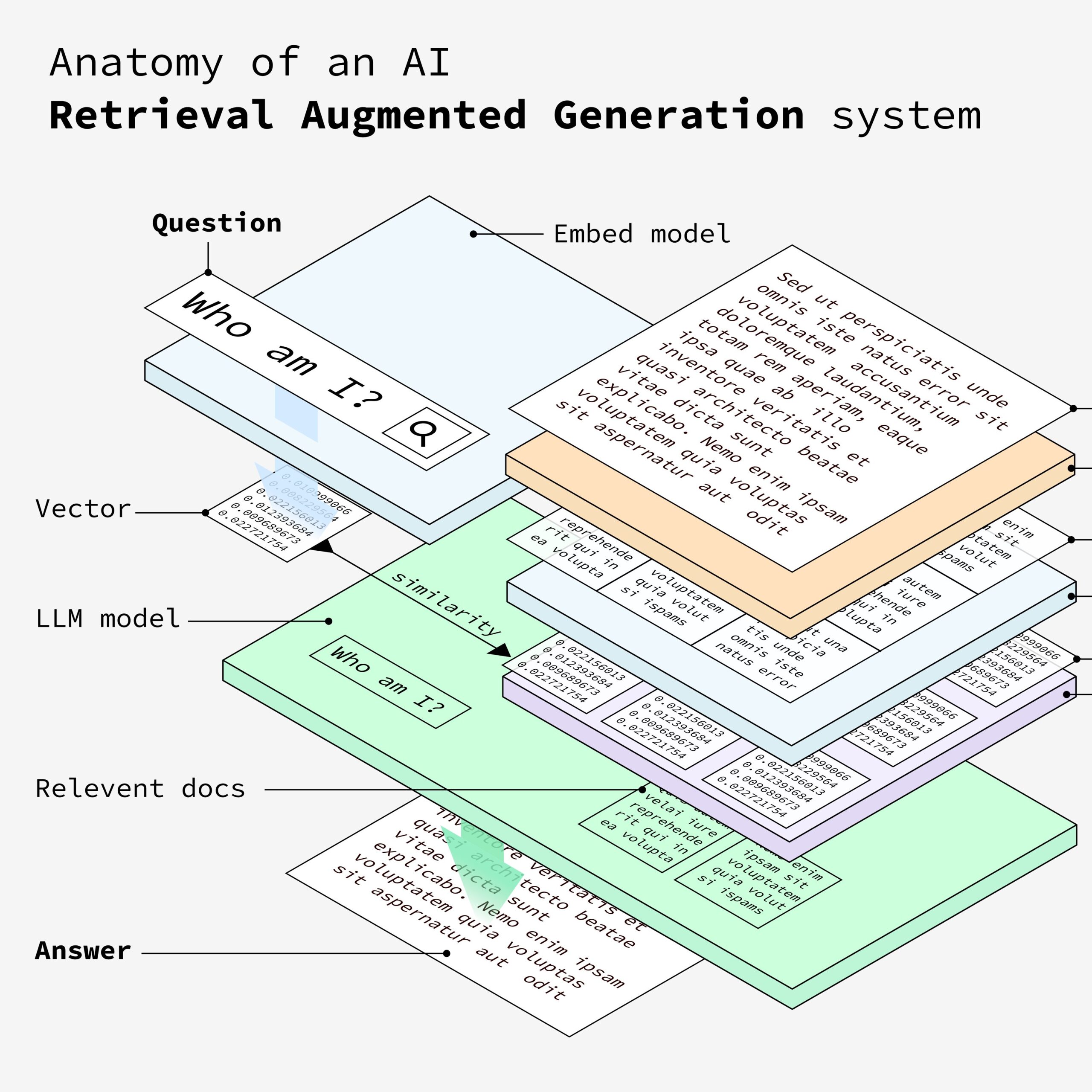
10. 最终答案
最终答案呈现给用户。这些答案是从检索到的文档中最相关的信息生成的,确保了准确性和相关性。
Vercel RAG Chatbot 指南
这篇指南详细介绍了如何构建一个基于检索增强生成(RAG)技术的聊天机器人应用。RAG技术通过为大型语言模型(LLM)提供与提示相关的特定信息来增强其生成能力。其关键步骤包括:
- RAG的基本概念:RAG是一种为LLM提供特定上下文信息以增强其生成能力的过程。
- 重要性:解决LLM只能基于其训练数据回答问题的问题,通过检索相关信息并传递给模型作为上下文来提供准确回答。
- Embedding和向量数据库:用向量表示单词、短语或图像,通过计算向量之间的相似性来实现语义搜索。
- 内容分块:将源材料分解成更小的部分进行嵌入,然后存储在数据库中,以提高嵌入的质量。
- 项目设置:使用Next.js 14、Vercel AI SDK、OpenAI、Drizzle ORM、Postgres和pgvector、shadcn-ui和TailwindCSS等技术栈进行项目开发。
一个由人工智能驱动的代码审查工具,它提供了一个全面的代码审查解决方案,包括上下文感知、智能聊天、深入的见解以及带有代码更改建议的逐行审查。