
Mistral AI 宣布发布 Mistral NeMo,这是一个由 NVIDIA 协作开发的 12B 参数模型,具备高达 128k 令牌的上下文窗口。该模型旨在支持企业应用,包括聊天机器人、多语言任务、编码和摘要。在其尺寸类别中,Mistral NeMo 在推理、世界知识和代码准确性方面均处于领先地位。使用标准架构,Mistral NeMo 易于使用,可作为任何使用 Mistral 7B 系统的直接替代品。
主要特点
- 广泛的上下文窗口:支持高达 128k 令牌的上下文窗口,使其在处理长文本时具有明显优势。
- 多语言支持:针对全球多语言应用进行了优化,特别是在英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语方面表现出色。
- 量化感知训练:支持 FP8 推理,减少内存占用并加快部署速度,同时不降低准确性。
性能表现
- 高性能和灵活性:Mistral NeMo模型在多轮对话、数学、常识推理、世界知识和编码方面表现出色,提供精确可靠的性能。
- 128K上下文长度:能够更连贯和准确地处理复杂信息,确保输出具有上下文相关性。
- 企业级支持和安全:模型作为NVIDIA NIM推理微服务提供,性能优化,支持灵活部署。
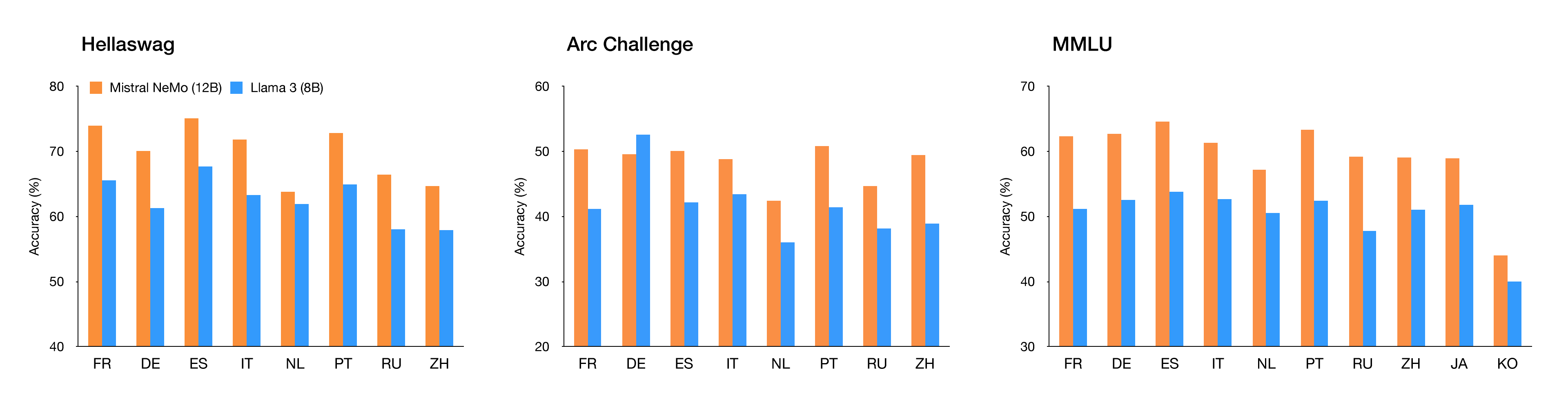
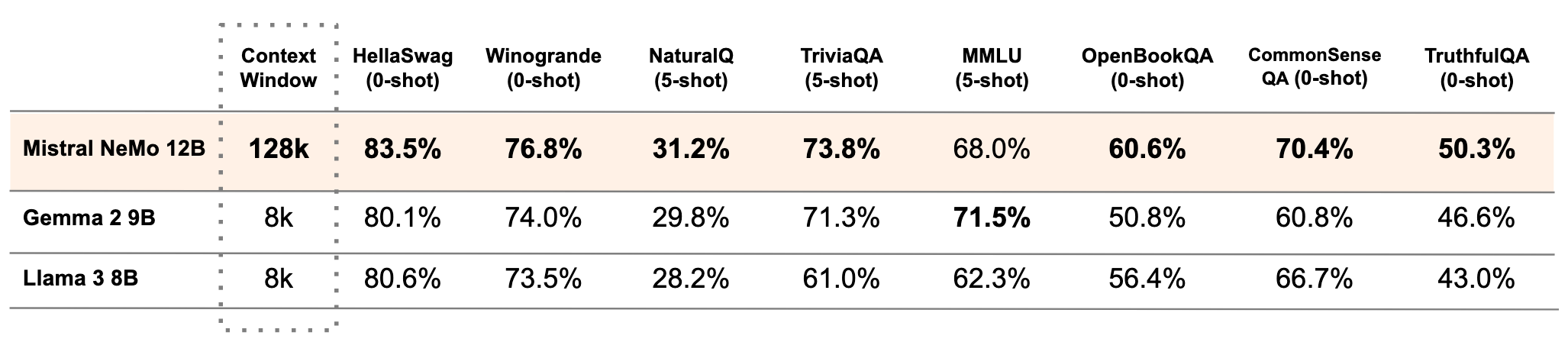
- 与其他模型的比较:在与 Gemma 2 9B 和 Llama 3 8B 的对比中,Mistral NeMo 基础模型在多项基准测试中表现优异。
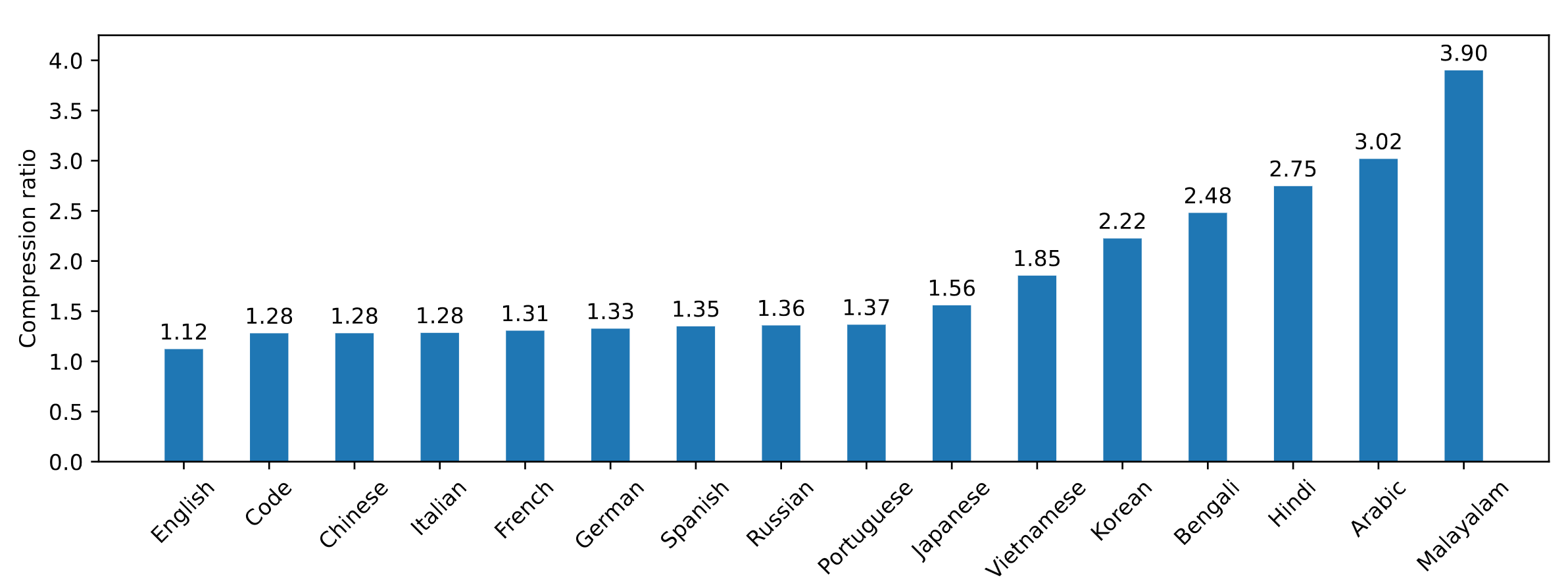
- 高效的分词器:Mistral NeMo 使用新型 Tekken 分词器,比之前的 SentencePiece 分词器在压缩源代码、中文、意大利语、法语、德语、西班牙语和俄语方面更高效,压缩效率提高约 30%。对于韩语和阿拉伯语,其压缩效率分别提高了 2 倍和 3 倍。这意味着它能以更少的存储空间表示相同数量的文本。
指令微调
- 精细调优:Mistral NeMo 经过高级微调和对齐,与 Mistral 7B 相比,能够更好地遵循精确指令、推理、处理多轮对话和生成代码。
 官方介绍:https://mistral.ai/news/mistral-nemo
官方介绍:https://mistral.ai/news/mistral-nemo
模型下载: base and instruct
UVR5,终极人声去除器,使用先进的 AI技术,从音视频提取伴奏,简单易用、无需注册即可使用来获取高质量的伴奏和其他音轨文件。