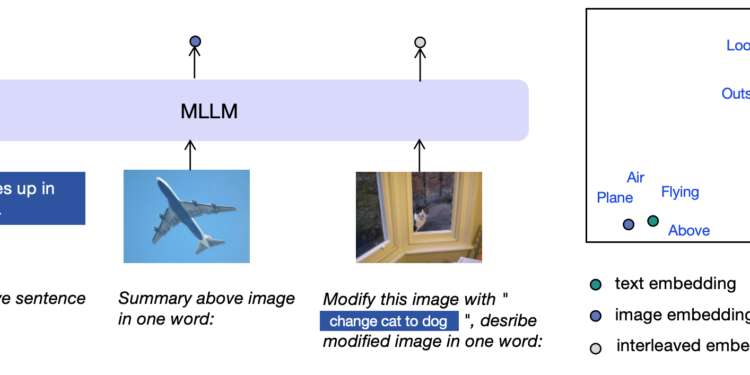
多模态大语言模型(MLLMs)已经在理解图像和文本方面取得了很大的进展,但在如何表示和整合这两种类型的信息方面还存在不足。
E5-V是一个新框架,通过只使用文本对进行训练,成功地解决了图像和文本这两种输入在表示上的差异问题,从而实现了通用的多模态嵌入。这意味着E5-V能够在同一个语义空间中同时处理和表示图像和文本信息,使得多模态信息的表示更加统一和高效。
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
言之画,一句话文本描述生成图片,减少设计师手动创作素材的时间和精力,10秒内即可生成大量的合格优质素材。