Mistral AI 宣布了其旗舰模型的最新一代——Mistral Large 2。与前代相比,Mistral Large 2 在代码生成、数学和推理方面显著提升,并提供更强的多语言支持和先进的函数调用能力。
该模型具备128k的上下文窗口,支持多种语言和80多种编程语言。Mistral Large 2 设计用于单节点推理,适合长上下文应用,拥有1230亿参数。
- 多语言支持:设计时即支持多种语言。
- 编程能力:在80多种编程语言上进行了训练,如Python、Java、C、C++、JavaScript和Bash,还包括Swift和Fortran等特定语言。
- 代理能力:具备最佳的代理功能,支持本地函数调用和JSON输出。
- 高级推理:拥有最先进的数学和推理能力。
- 大上下文窗口:提供128k的上下文窗口。
- MMLU (大规模多语言理解测试): 84.0%
- Human Eval (编程能力测试): 92%
- GSM8K (数学基准测试): 93%
 主要特性
主要特性
性能
- 效率与成本:在性能和成本的权衡方面,Mistral Large 2 设立了新的标准。在MMLU评估中,预训练版本的准确率达到了84.0%。
- 代码与推理:模型经过大量代码数据训练,在代码生成和推理能力上超过了前代模型,与GPT-4o、Claude 3 Opus、Llama 3 405B等领先模型表现相当。通过细致的微调,模型在减少“幻觉”现象方面取得了显著进展。
多语言支持
- 语言多样性:Mistral Large 2 在多语言数据上训练,特别擅长处理多种语言,如英语、法语、德语、西班牙语、意大利语、葡萄牙语、俄语、中文、日语、韩语、阿拉伯语和印地语。以及包括Python、Java、C、C++、JavaScript和Bash在内的80多种编程语言。
- 多语言MMLU性能:在多语言MMLU基准测试中的表现优于之前的Mistral Large和其他同类模型。
功能调用
- 增强的函数调用与检索技能:模型经过训练,能够有效执行并行和顺序的函数调用,适用于复杂业务应用。
评估结果
总体性能
- 性能/成本:Mistral Large 2 在性能和成本的权衡方面设立了新的标准。在 MMLU(多任务语言理解)评估中,预训练版本的准确率达到了 84.0%,在开源模型中占据了性能/成本的前沿。
代码与推理能力
- 代码生成基准测试:在代码生成基准测试中,Mistral Large 2 表现优异,与领先的模型如 GPT-4o、Claude 3 Opus 和 Llama 3 405B 相当。
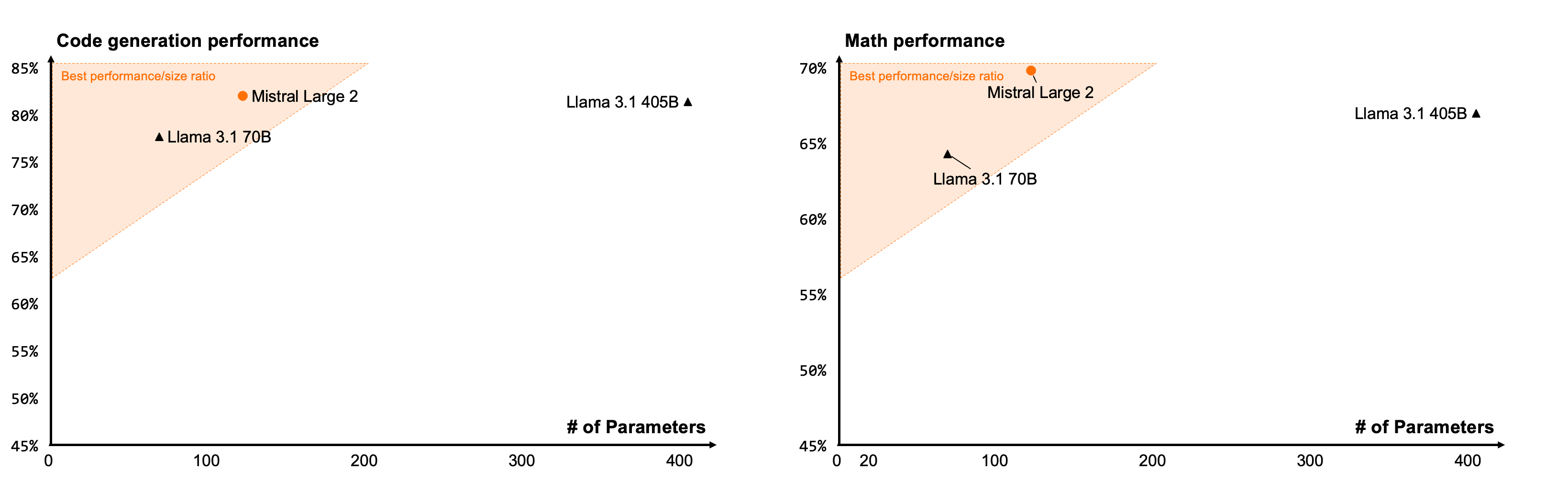
- 推理能力:模型在推理能力上显著提升,通过细致的微调,减少了生成不准确或无关信息的“幻觉”现象。模型在数学基准测试中的表现证明了其增强的推理和问题解决能力。
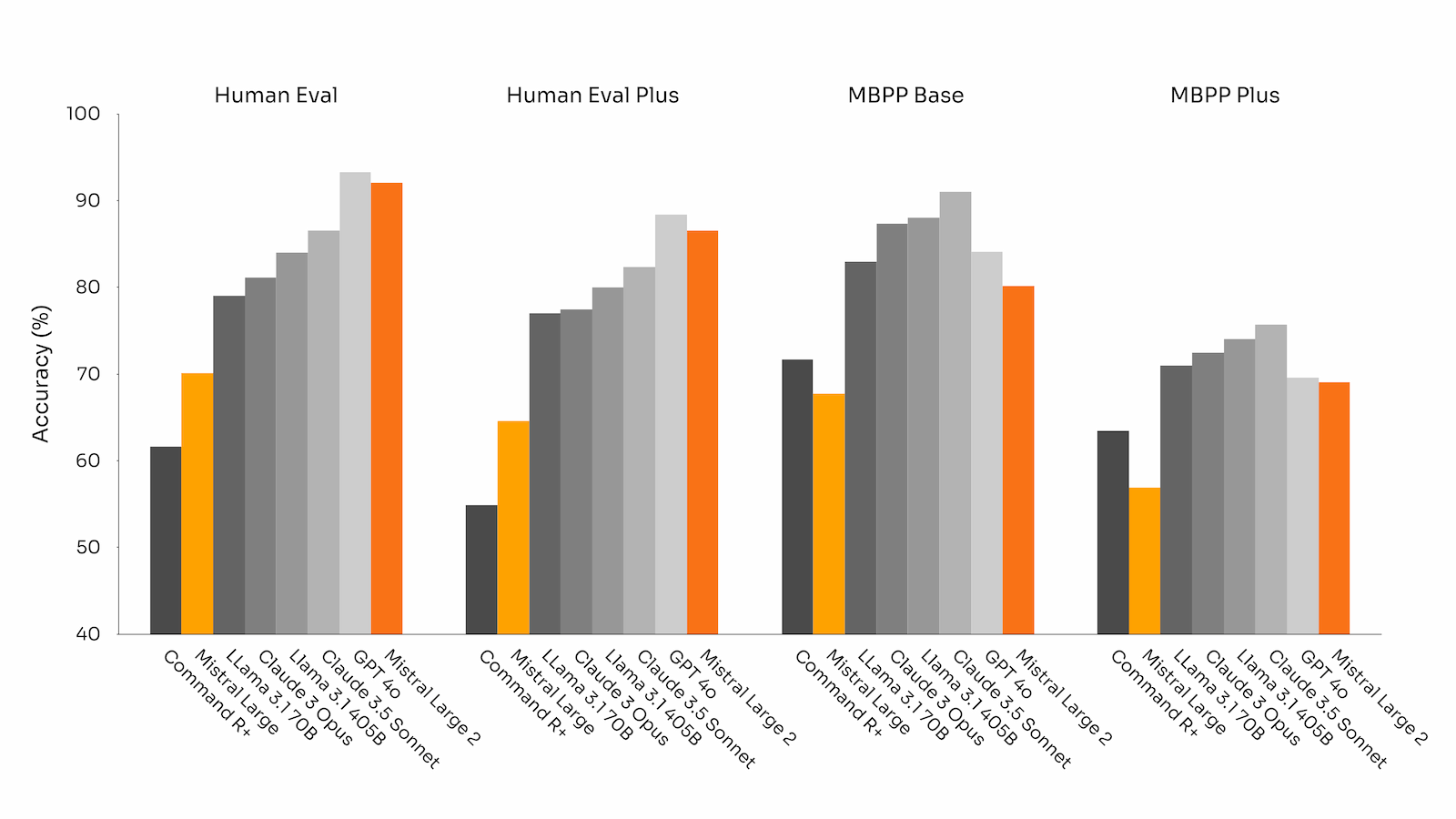
代码生成基准的性能精度(所有模型均通过相同的评估管道进行基准测试)
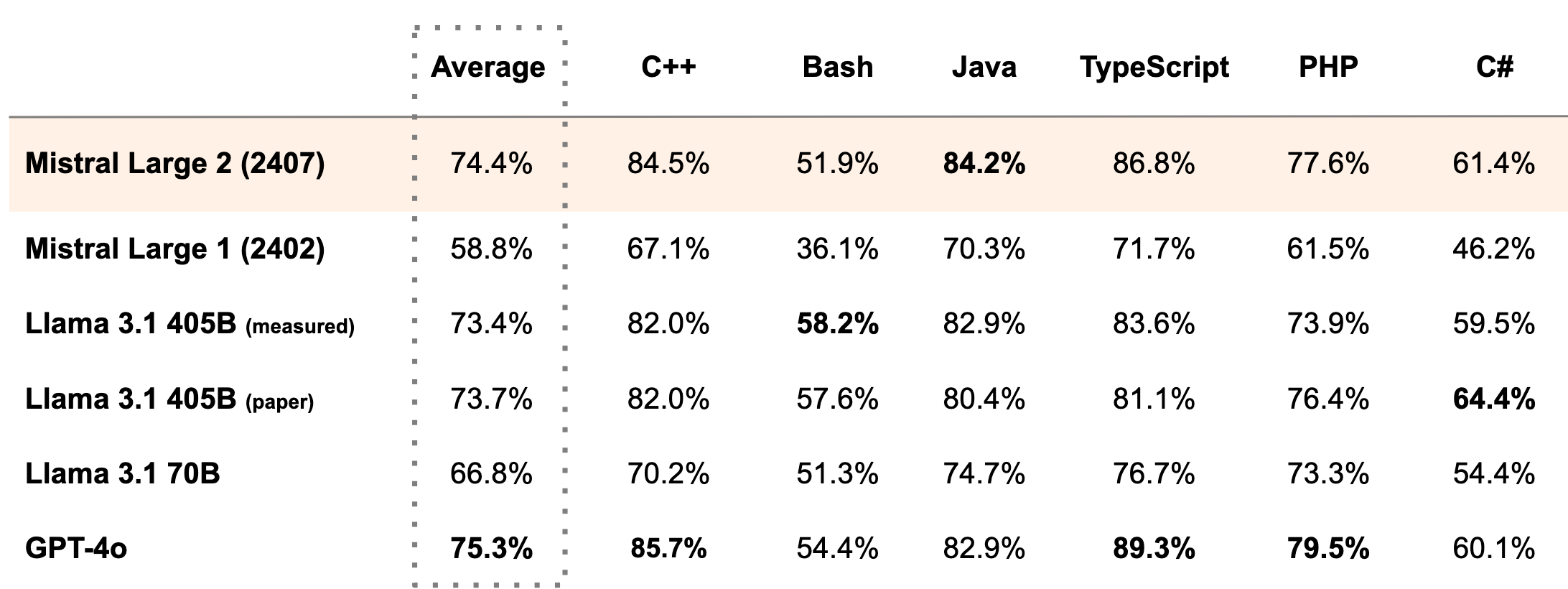 在 MultiPL-E 上的性能精度(除 “纸质 “行外,所有模型均通过相同的评估管道进行基准测试)
在 MultiPL-E 上的性能精度(除 “纸质 “行外,所有模型均通过相同的评估管道进行基准测试)
多语言支持
- 多语言 MMLU 性能:Mistral Large 2 在多语言 MMLU 基准测试中的表现优于之前的 Mistral Large 和其他同类模型,特别是在英语、法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语、俄语、中文、日语、韩语、阿拉伯语和印地语方面。
指令跟随与对话能力
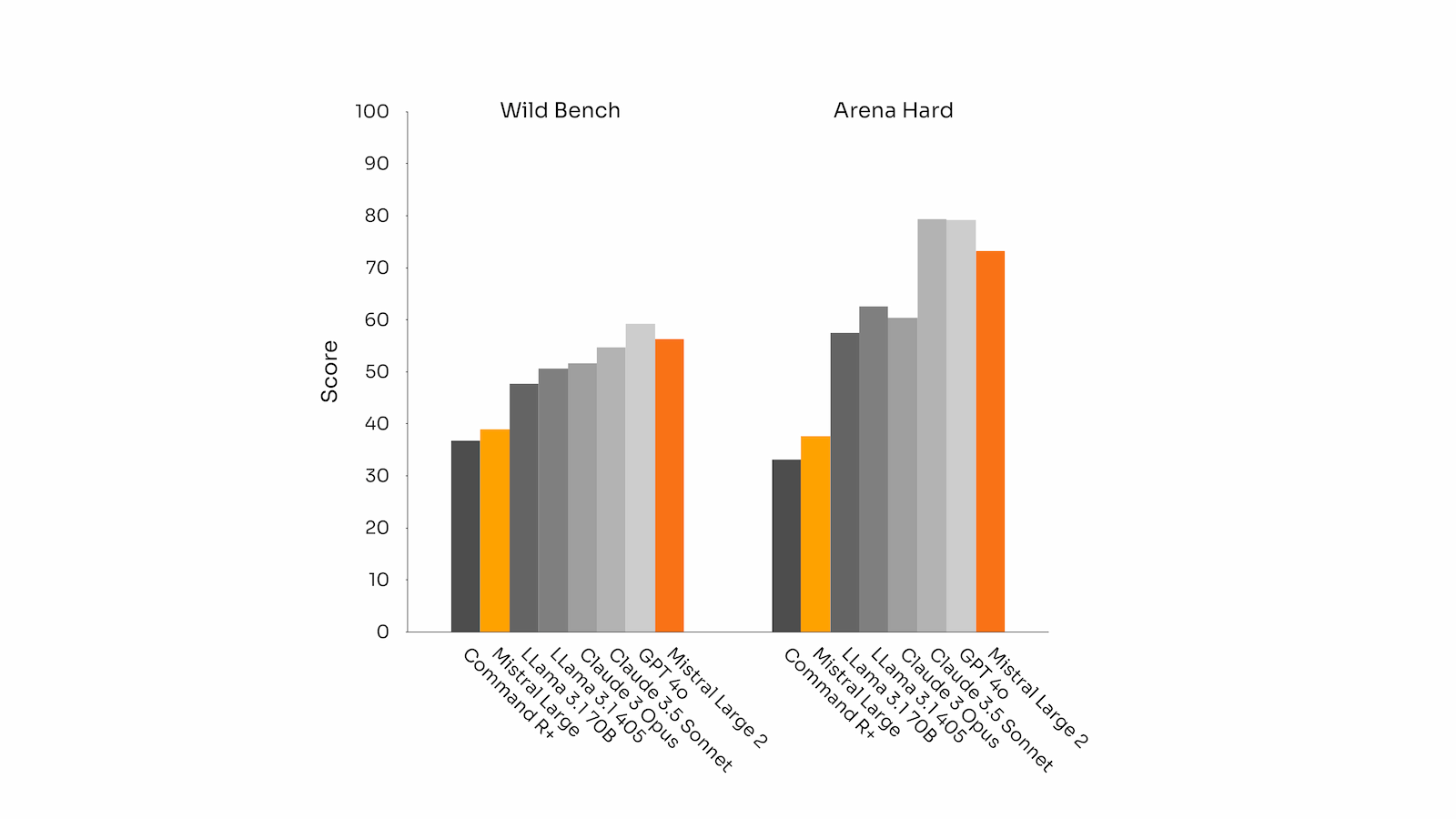
- 指令跟随能力:在指令跟随和对话能力上,Mistral Large 2 表现显著改善。模型在处理精确指令和长多轮对话方面表现特别出色。
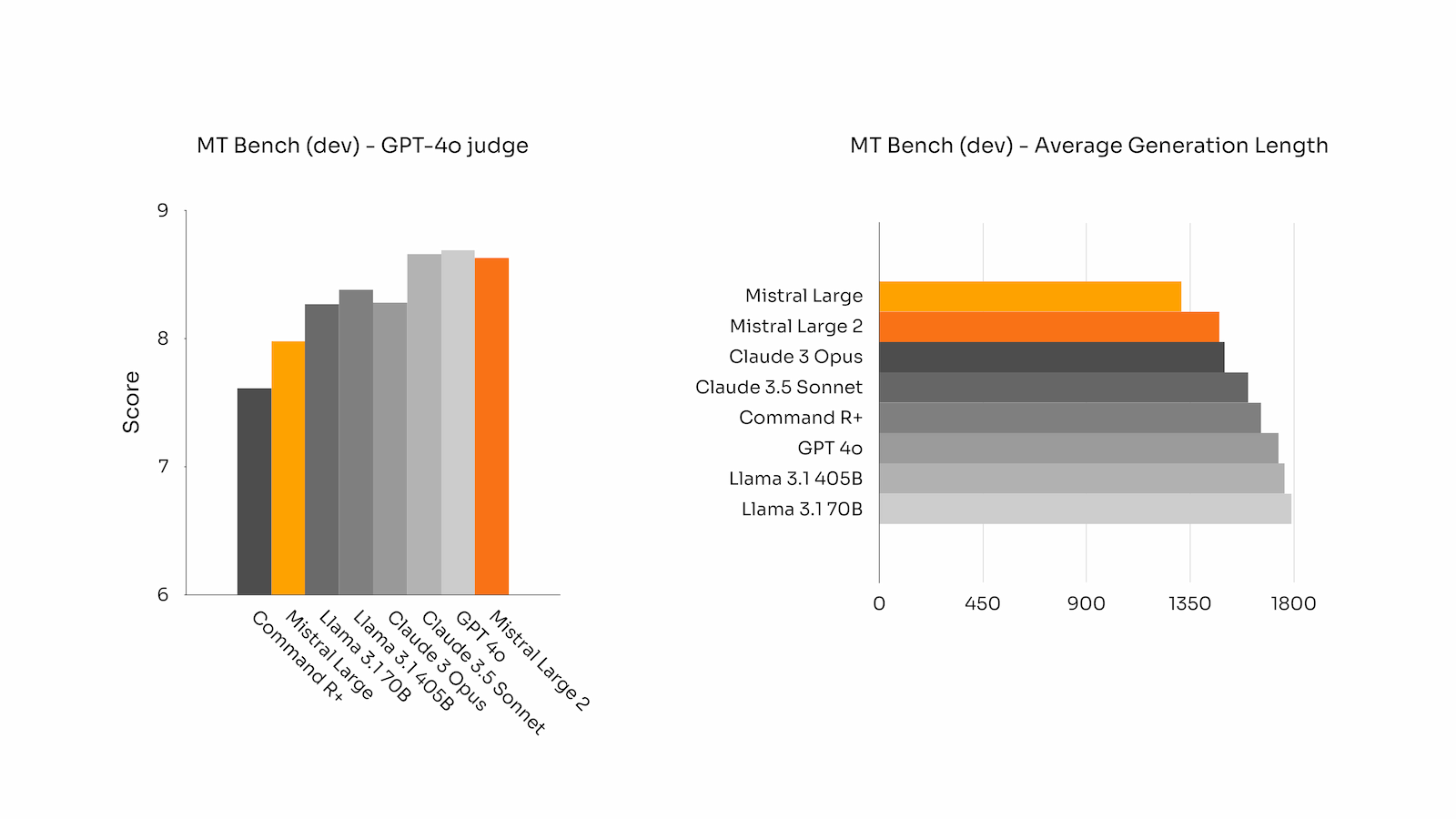
- 对齐基准测试:在 MT-Bench、Wild Bench 和 Arena Hard 基准测试中的表现表明,模型在生成简洁且切中要点的回答方面表现良好。
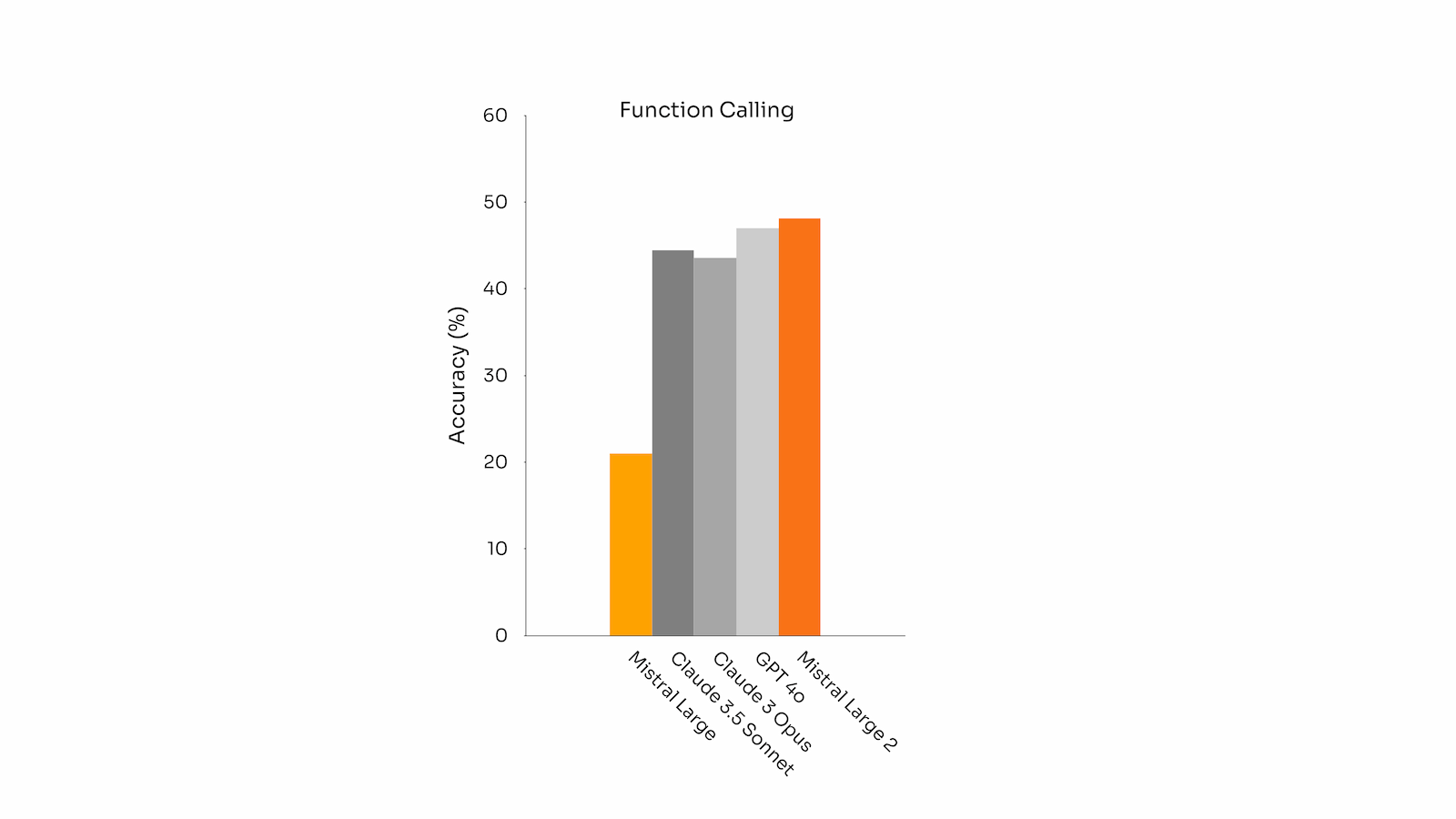
工具使用和功能调用
- Mistral Large 2 配备了增强的函数调用和检索技能,并接受了熟练执行并行和顺序函数调用的培训,使其能够成为复杂业务应用程序的动力引擎。
性能图表
多语言 MMLU 性能
Mistral Large 2 相较于之前的 Mistral Large、Llama 3.1 模型和 Cohere 的 Command R+ 在多语言 MMLU 基准测试中的表现:
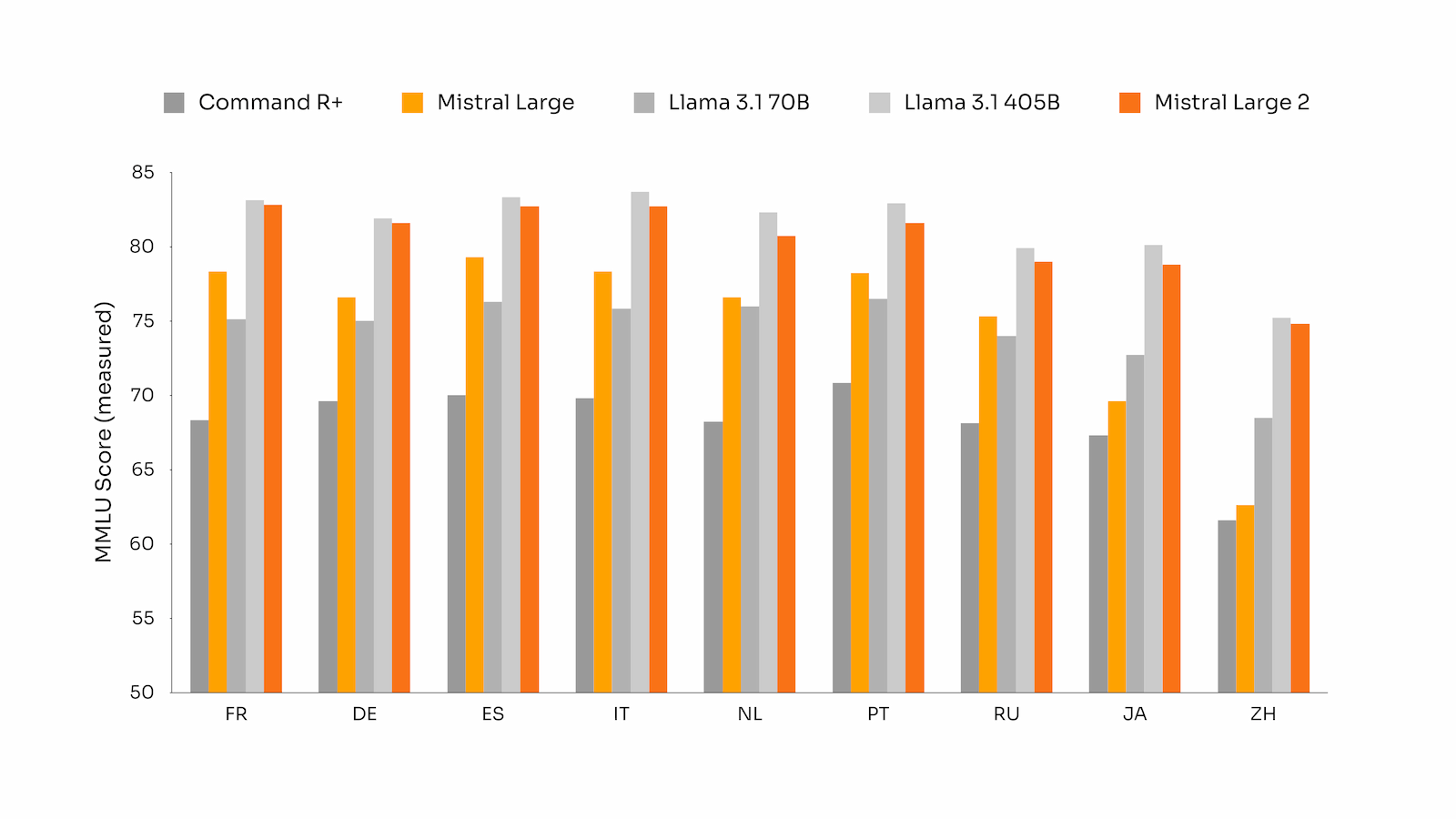 多语言 MMLU 的性能(根据基础预训练模型测得)
多语言 MMLU 的性能(根据基础预训练模型测得)代码生成与推理性能
Mistral Large 2 在代码生成基准测试、MultiPL-E、GSM8K(8-shot)和 MATH(0-shot, no CoT)生成基准测试中的表现:
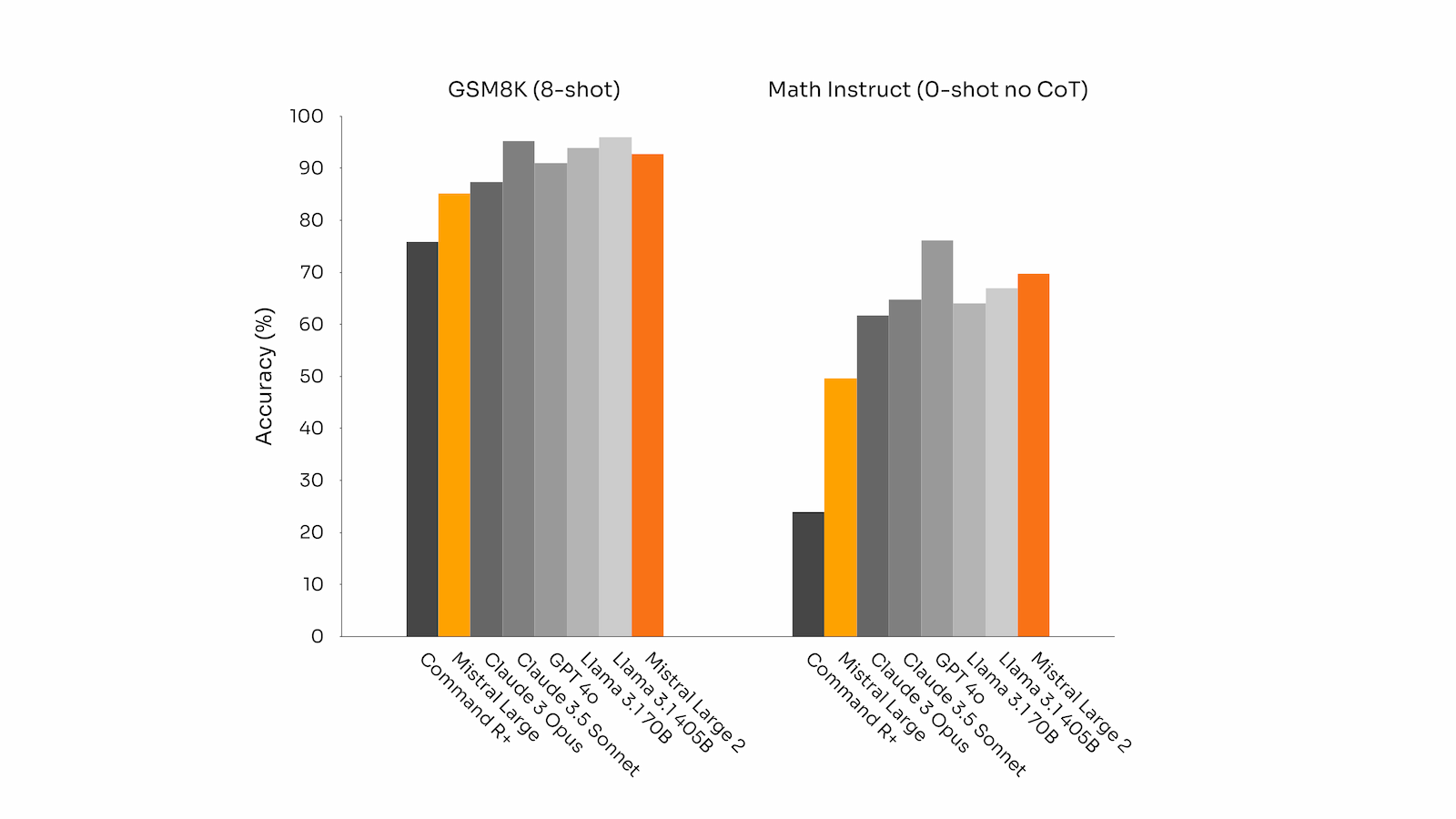
生成长度
在 MT Bench 基准测试中的平均生成长度:
详细内容:https://mistral.ai/news/mistral-large-2407/
模型下载:https://huggingface.co/mistralai/Mistral-Large-Instruct-2407
在线体验:la Plateforme
国民短视频社区,记录和分享生活的平台