
智谱AI发布其最新基座大模型GLM-4-Plus以及展示了类似OpenAI GPT 4o模型的视觉能力,能进行自由语音通话和视觉推理,并宣布8月30日开放!
- 语言基座模型 GLM-4-Plus:在语言理解、指令遵循、长文本处理等方面性能得到全面提升,保持了国际领先水平。
- 文生图模型 CogView-3-Plus:具备与当前最优的 MJ-V6 和 FLUX 等模型接近的性能。
- 图像/视频理解模型 GLM-4V-Plus:具备卓越的图像理解能力,并具备基于时间感知的视频理解能力。该模型将上线开放平台( bigmodel.cn ),并成为国内首个通用视频理解模型 API 。
- 视频生成模型 CogVideoX:在发布并开源 2B 版本后,5B 版本也正式开源,其性能进一步增强,是当前开源视频生成模型中的最佳选择。
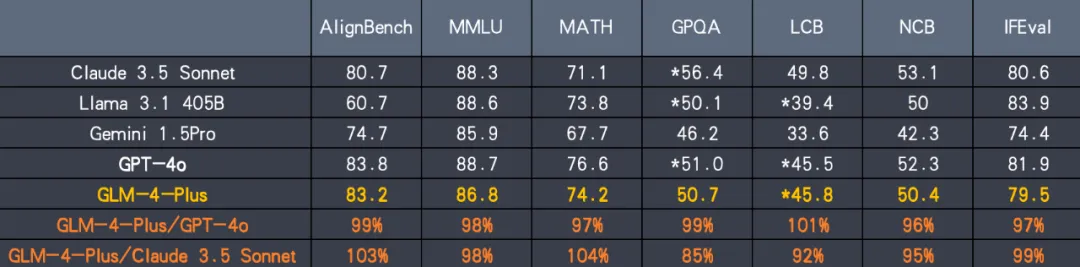
GLM-4-Plus在多个方面表现出了卓越的性能,在语言理解、指令遵循、长文本处理等多个方面取得了显著提升。
功能和特点:
- 语言理解与处理能力:
- 增强的语言理解:GLM-4-Plus在语言理解、指令遵循、长文本处理等方面的性能得到了全面提升,能够更好地理解和处理复杂的文本任务。
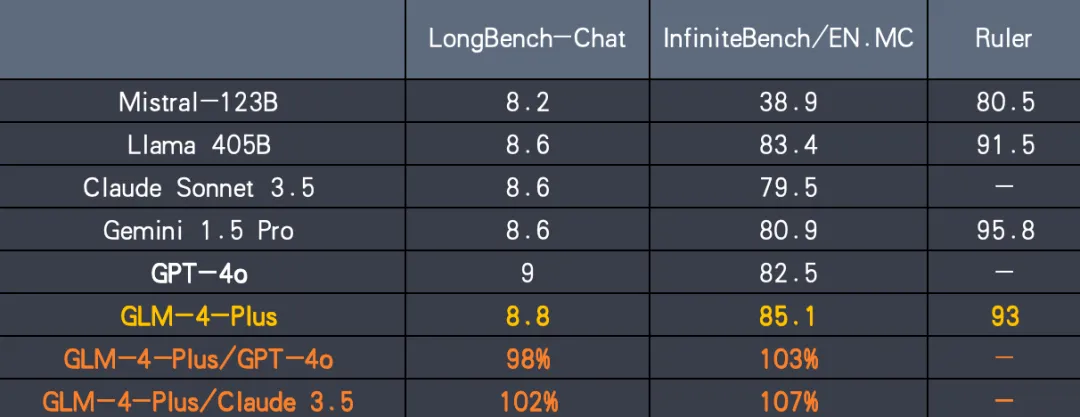
- 长文本处理:通过更精准的长短文本数据混合策略,GLM-4-Plus的长文本推理效果得到了显著提升,比肩国际先进水平。
- GLM-4-Plus 在语言文本能力上与 GPT-4o 及 405B 参数量的 Llama3.1 相当。
- 模型构造与数据合成:
- 高质量合成数据:GLM-4-Plus使用了大量模型辅助构造高质量合成数据,以提升模型性能,特别是在推理(如数学、代码算法题)表现方面,更好地反映了人类偏好。
- 多模态能力:
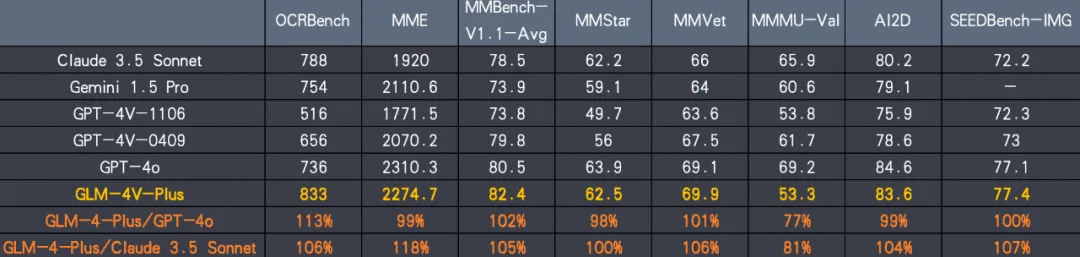
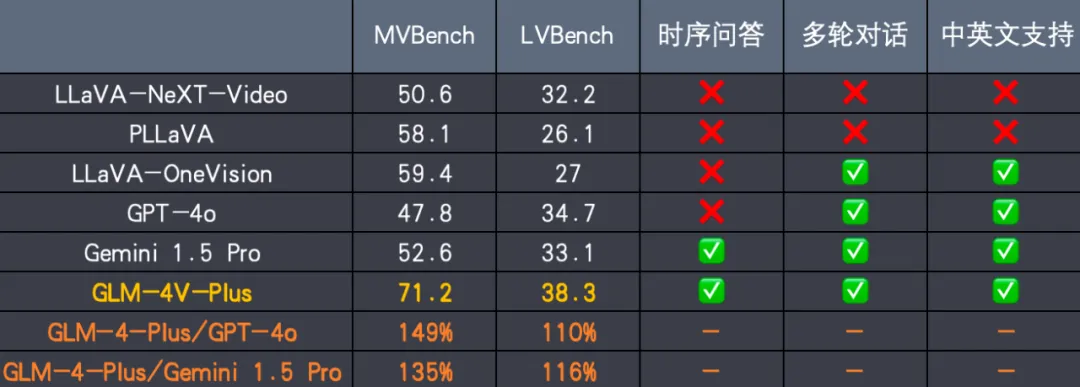
- 图像和视频理解:GLM-4V-Plus作为GLM-4-Plus的扩展,具备卓越的图像理解能力,并新增了时间感知的视频理解能力,可以理解复杂的视频内容并进行时间推理。
- 文生图与视频生成:配合CogView-3-Plus和CogVideoX等模型,GLM-4-Plus能够在图片编辑和视频生成等任务上展现出优越性能。
视频理解示例:
视频播放器00:0000:00【视频总结能力】+【推理能力】+【多轮对话】+【时间问答能力】
- 用户:这个穿绿色衣服的球员在整个视频都做了什么?
- GLM-4V-Plus:在整个视频中,穿绿色衣服的球员在场上运球,然后跳起将球投入篮筐。
- 用户:这个视频的精彩时刻是什么?发生在第几秒?
- GLM-4V-Plus:这个视频的精彩时刻发生在第4秒,当时穿绿色衣服的球员跳起并将球投入篮筐。
智谱的清言 APP将 迎来“视频通话”功能,这也是国内首个面向 C 端开放的视频通话功能。 清言视频通话能力跨越了文本模态、音频模态和视频模态,并具备实时推理的能力。
可以进行流畅通话,即便频繁打断它也能迅速反应。只要打开摄像头,我们看到的画面,清言也可以看到,同时可以听懂指令并准确执行。
视频通话功能将于8 月 30 日上线,首批面向清言部分用户开放,同时开放外部申请。

在线体验:bigmodel.cn
由人工智能驱动的互动PPT演示工具,简化演示创作过程,节省宝贵的时间。