
阿里云发布Qwen2-VL 最新视觉语言模型版本,较其前代Qwen-VL有显著提升。
Qwen2-VL具备多分辨率和比例图像的先进理解能力,并在多个视觉理解基准上表现出色,包括MathVista、DocVQA、RealWorldQA和MTVQA等。
此外,Qwen2-VL能够理解长达20分钟以上的视频内容,支持复杂推理和决策,使其能够与移动设备、机器人等进行自动化操作。
该模型还增加了多语言支持,能理解包括大部分欧洲语言、日语、韩语、阿拉伯语等在内的图像文本。
 模型规模:
模型规模:
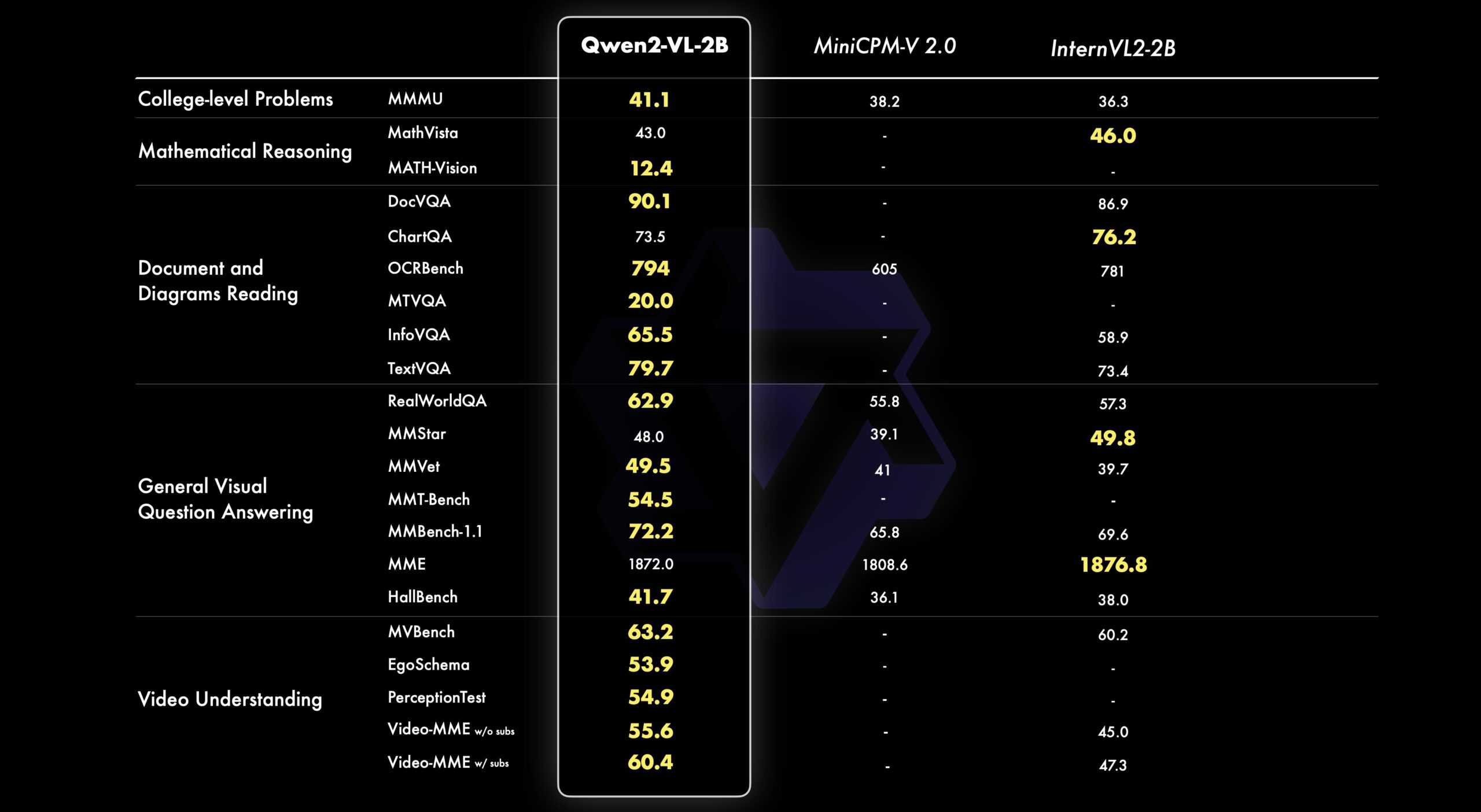
此次发布的模型包括开源的Qwen2-VL-2B和Qwen2-VL-7B,以及Qwen2-VL-72B的API。
- Qwen2-VL-72B: 作为模型家族中最大的一款,在多数评测指标上都表现出色,特别是在文档理解方面具有显著优势。
- Qwen2-VL-7B: 在保留图像、多图像和视频输入支持的同时,提供了具有成本效益的竞争性能,模型在 DocVQA 等文档理解任务和从图像中理解多语言文本方面表现出色(经 MTVQA 评估),建立了最先进的性能。
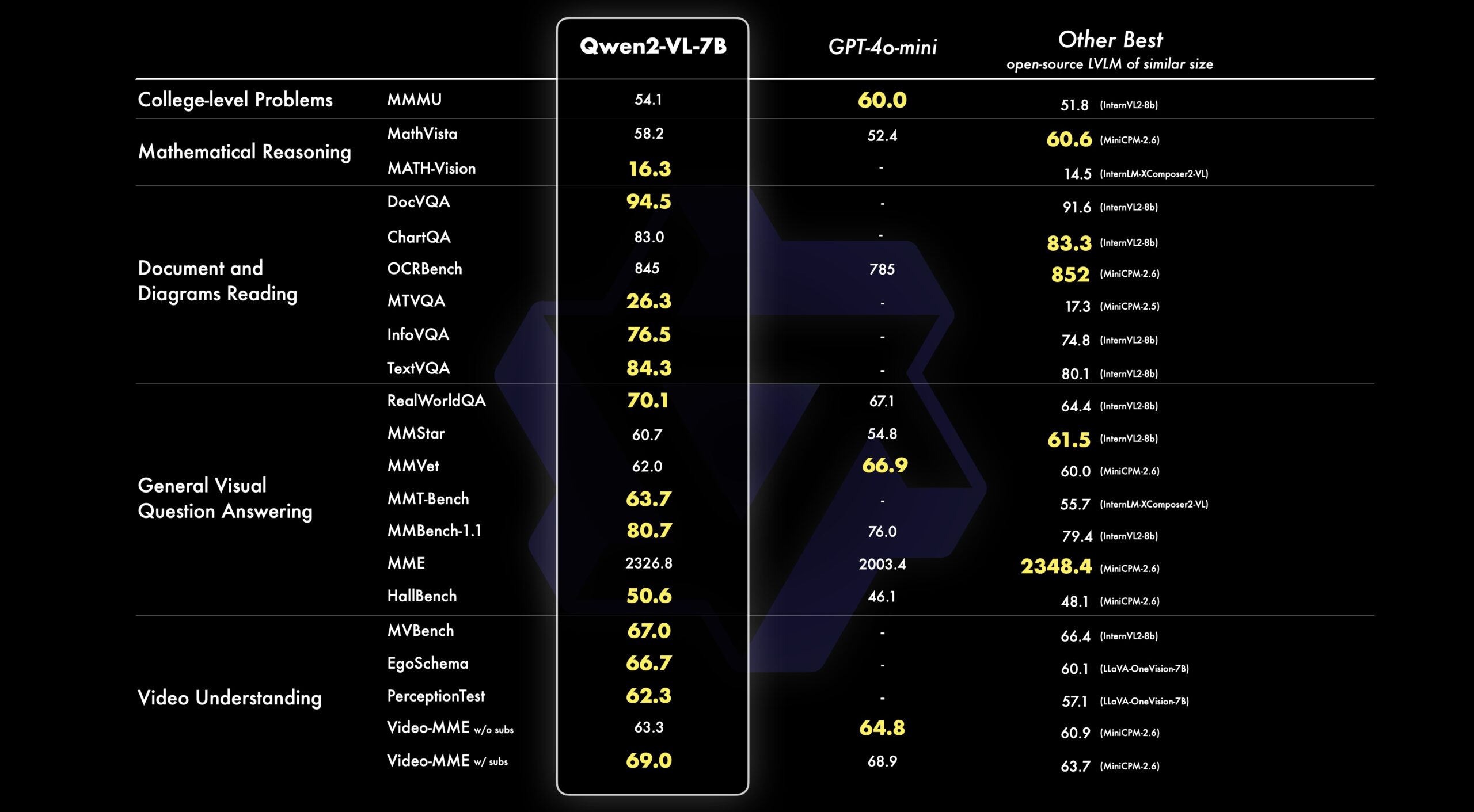
- Qwen2-VL-2B: 一款更小的 2B 模型,该模型针对潜在的移动部署进行了优化。尽管体积小巧,但该模型在图像、视频和多语言理解方面拥有强大的性能。与其他类似规模的模型相比,它在视频相关任务、文档理解和一般场景问答方面尤其出色。
主要功能与亮点
- 增强的识别能力:
- 对象识别: Qwen2-VL 提升了对复杂场景中多个对象的识别能力,不仅限于植物和地标,还能理解多个对象之间的复杂关系。
- 文本识别: 显著增强了对手写文本和多语言的识别能力,使其能够识别图像中的多种语言文本,包括大部分欧洲语言、日语、韩语、阿拉伯语等。
Output the color and number of each box.
输出每个盒子的颜色和数量。
The image shows a stack of colorful blocks with numbers on them. Here is the color and number of each block from top to bottom:
该图像显示了一堆带有数字的彩色块。这是从上到下每个块的颜色和数量:- Top row (single block): Blue with the number 9
顶行(单块):蓝色,数字 9 - Second row (two blocks): Light blue with the number 7, and green with the number 8
第二行(两个区块):浅蓝色代表数字 7,绿色代表数字 8 - Third row (three blocks): Purple with the number 4, pink with the number 5, and light green with the number 6
第三行(三块):紫色代表数字 4,粉色代表数字 5,浅绿色代表数字 6 - Bottom row (four blocks): Red with the number 0, orange with the number 1, yellow with the number 2, and light green with the number 3
底行(四个块):红色代表数字 0,橙色代表数字 1,黄色代表数字 2,浅绿色代表数字 3
- Top row (single block): Blue with the number 9
- 视觉推理:
- 问题解决能力: Qwen2-VL 在数学和编码能力上有了显著提升,能够通过图表分析解决复杂的数学问题,即使是极端比例失真的图像也能正确解释。
- 信息提取: 模型可以从真实世界的图像和图表中提取信息,并具备更好的指令遵循能力,能够解决实际问题,将抽象概念与具体解决方案结合起来。
Solve the algorithmic problem in the web page.
解决网页中的算法问题。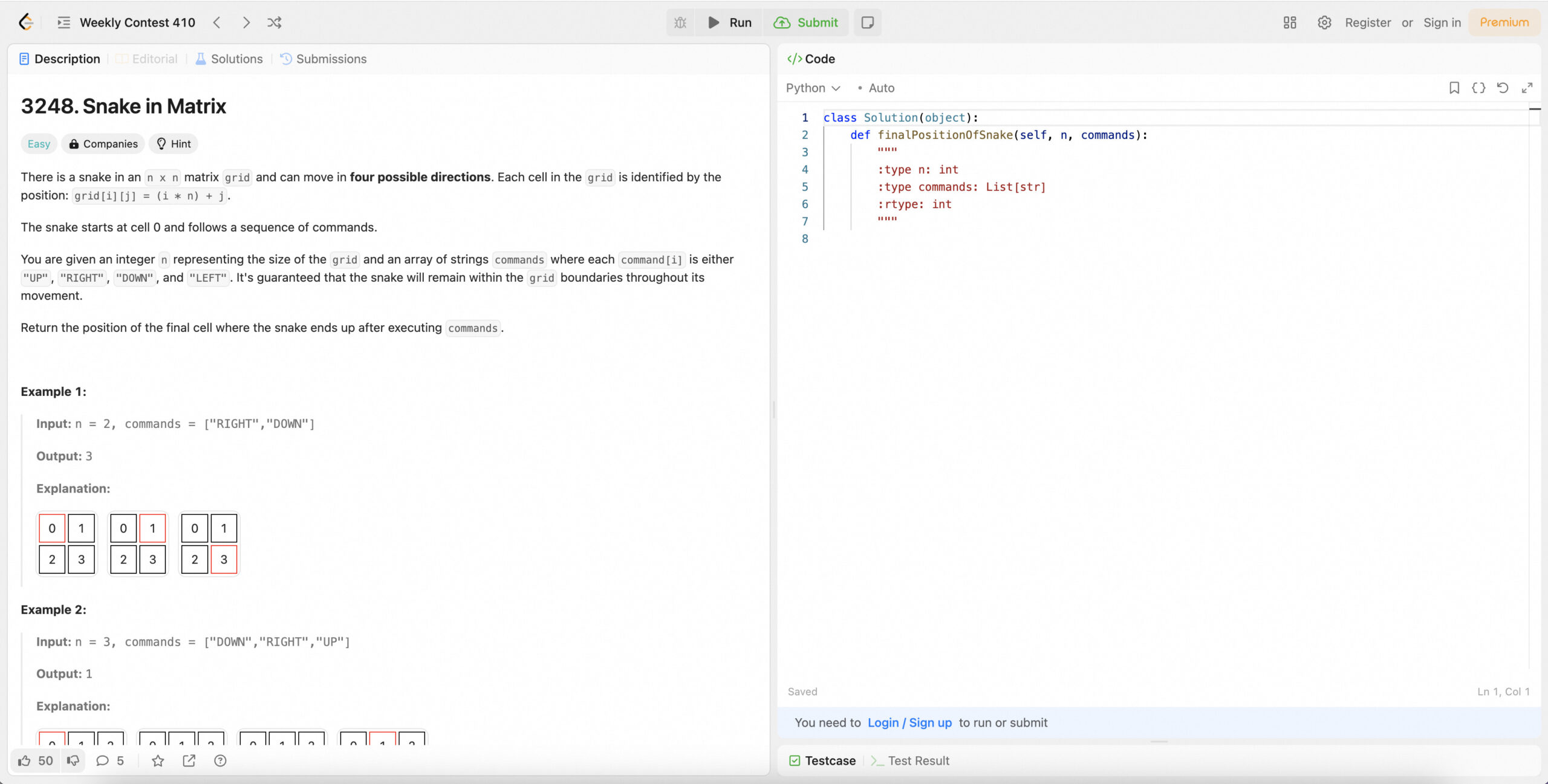
To solve the “Snake in Matrix” problem, we need to implement a function that takes the size of the matrix
nand a list of commands, and returns the final position of the snake after executing all the commands. Here’s a step-by-step approach to solve this problem:
为了解决“矩阵中的蛇”问题,我们需要实现一个函数,该函数接受矩阵n的大小和命令列表,并在执行所有命令后返回蛇的最终位置。以下是解决此问题的分步方法:-
Initialize Variables:
初始化变量:- Initialize the current position of the snake as
0.
将蛇的当前位置初始化为0。 - Initialize the direction of the snake as “RIGHT” (initially, the snake moves to the right).
将蛇的方向初始化为“RIGHT”(最初,蛇向右移动)。
- Initialize the current position of the snake as
-
Define Movement Functions:
定义运动功能:- Create a function to move the snake based on the current direction and the size of the matrix
n.
创建一个函数,根据当前方向和矩阵n的大小来移动蛇。 - Update the position of the snake accordingly.
相应地更新蛇的位置。
- Create a function to move the snake based on the current direction and the size of the matrix
-
Process Commands:
处理命令:- Iterate through each command in the list of commands.
迭代命令列表中的每个命令。 - For each command, update the direction and position of the snake.
对于每个命令,更新蛇的方向和位置。
- Iterate through each command in the list of commands.
-
Return Final Position:
返回最终位置:- After processing all commands, return the final position of the snake.
处理完所有命令后,返回蛇的最终位置。
- After processing all commands, return the final position of the snake.
Here’s the Python code to implement the solution:
下面是实现该解决方案的 Python 代码:class Solution: def finalPositionOfSnake(self, n: int, commands: List[str]) -> int: # Initialize variables position = 0 direction = "RIGHT" # Define movement functions def move_right(): nonlocal position position += 1 def move_down(): nonlocal position position += n def move_left(): nonlocal position position -= 1 def move_up(): nonlocal position position -= n # Process commands for command in commands: if command == "RIGHT": move_right() elif command == "DOWN": move_down() elif command == "LEFT": move_left() elif command == "UP": move_up() # Return final position return positionThis code defines a class
Solutionwith a methodfinalPositionOfSnakethat takes the size of the matrixnand a list of commands, and returns the final position of the snake after executing all the commands. The movement functions (move_right,move_down,move_left,move_up) are used to update the position of the snake based on the current direction.
此代码定义了一个Solution类,其方法为finalPositionOfSnake,该方法获取矩阵n的大小和命令列表,并在执行所有命令后返回蛇的最终位置。移动函数(move_right、move_down、move_left、move_up)用于根据当前方向更新蛇的位置。 -
- 视频理解与实时对话:
- 视频分析: Qwen2-VL 扩展了对视频内容的分析能力,可以总结视频内容,回答与视频相关的问题,并在实时对话中持续提供信息和支持。
Please describe the video in detail.
请详细描述一下视频。
视频播放器00:0000:00Qwen2-VLThe video begins with a man speaking to the camera, followed by a group of people sitting in a control room. The camera then cuts to two men floating inside a space station, where they are seen speaking to the camera. The men appear to be astronauts, and they are wearing space suits. The space station is filled with various equipment and machinery, and the camera pans around to show the different areas of the station. The men continue to speak to the camera, and they appear to be discussing their mission and the various tasks they are performing. Overall, the video provides a fascinating glimpse into the world of space exploration and the daily lives of astronauts.
视频开始时,一名男子对着镜头说话,后面是一群人坐在控制室里。然后镜头切换到两个漂浮在空间站内的男子,可以看到他们对着镜头说话。这些人似乎是宇航员,他们穿着太空服。空间站里充满了各种设备和机械,镜头四处移动以显示空间站的不同区域。这些人继续对着镜头说话,他们似乎在讨论他们的使命和他们正在执行的各种任务。总的来说,该视频让人们对太空探索的世界和宇航员的日常生活有了一个有趣的了解。User 用户What is the color of the clothes the two astronauts wearing?
两位宇航员穿的衣服是什么颜色的?Qwen2-VLThe two astronauts are wearing blue and black clothes.
两名宇航员穿着蓝色和黑色的衣服。 - 实时互动: 模型支持实时对话功能,能够充当个人助理,从视频内容中直接提供见解和信息。
Live chat 在线聊天
- 视频分析: Qwen2-VL 扩展了对视频内容的分析能力,可以总结视频内容,回答与视频相关的问题,并在实时对话中持续提供信息和支持。
- 视觉代理能力:
- 功能调用: Qwen2-VL 展现了作为视觉代理的强大潜力,能够通过解读视觉线索调用外部工具,实现实时数据获取,如航班状态、天气预报或包裹追踪等。
函数调用
Ask about the weather 询问天气
- 用户界面交互: 通过允许模型与视觉刺激互动,Qwen2-VL 将AI的感知能力推向新的高度,使其不仅是观察者,更是视觉体验的主动参与者。
UI 交互
Operate a Mobile Phone 操作手机
- 功能调用: Qwen2-VL 展现了作为视觉代理的强大潜力,能够通过解读视觉线索调用外部工具,实现实时数据获取,如航班状态、天气预报或包裹追踪等。
性能表现
Qwen2-VL 在多个关键维度的视觉能力上进行了评估,展示了卓越的性能,尤其是在以下方面:
- 复杂的大学级问题解决:
- Qwen2-VL 展现了在解决复杂数学问题和逻辑推理方面的强大能力,能够应对高级别的学术和实际问题。
- 文档和表格理解:
- 在文档理解任务中,如DocVQA(文档视觉问答),Qwen2-VL 72B 模型表现尤为突出,超过了许多闭源模型(如GPT-4o和Claude 3.5-Sonnet),展现了顶级性能。
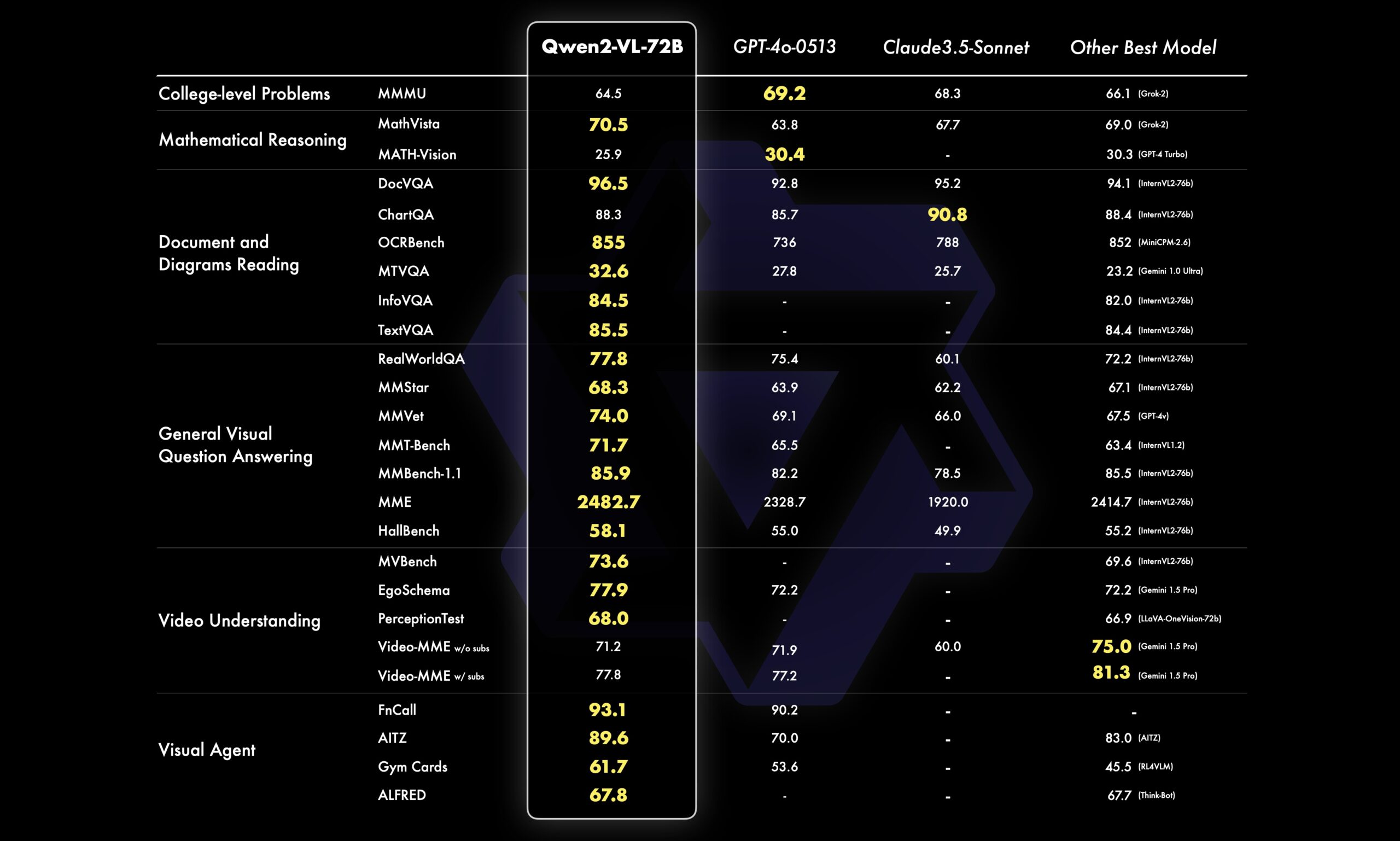
- 在文档理解任务中,如DocVQA(文档视觉问答),Qwen2-VL 72B 模型表现尤为突出,超过了许多闭源模型(如GPT-4o和Claude 3.5-Sonnet),展现了顶级性能。
- 多语言文本-图像理解:
- Qwen2-VL 在多语言文本-图像理解任务中表现出色,尤其是在MTVQA(多语言文本视觉问答)任务中,达到了业界领先的性能水平。
- 一般场景问答:
- 在通用场景问答任务中,Qwen2-VL 展现了强大的理解和回答能力,适应了多种复杂场景。
- 视频理解:
- Qwen2-VL 对视频内容的理解能力非常强大,能够处理超过20分钟的视频,并在视频相关任务中展现出卓越的表现。
- 代理互动能力:
- Qwen2-VL 具备与设备(如移动设备、机器人)进行复杂互动的能力,支持自动化操作,并在多种互动任务中表现良好。
模型架构
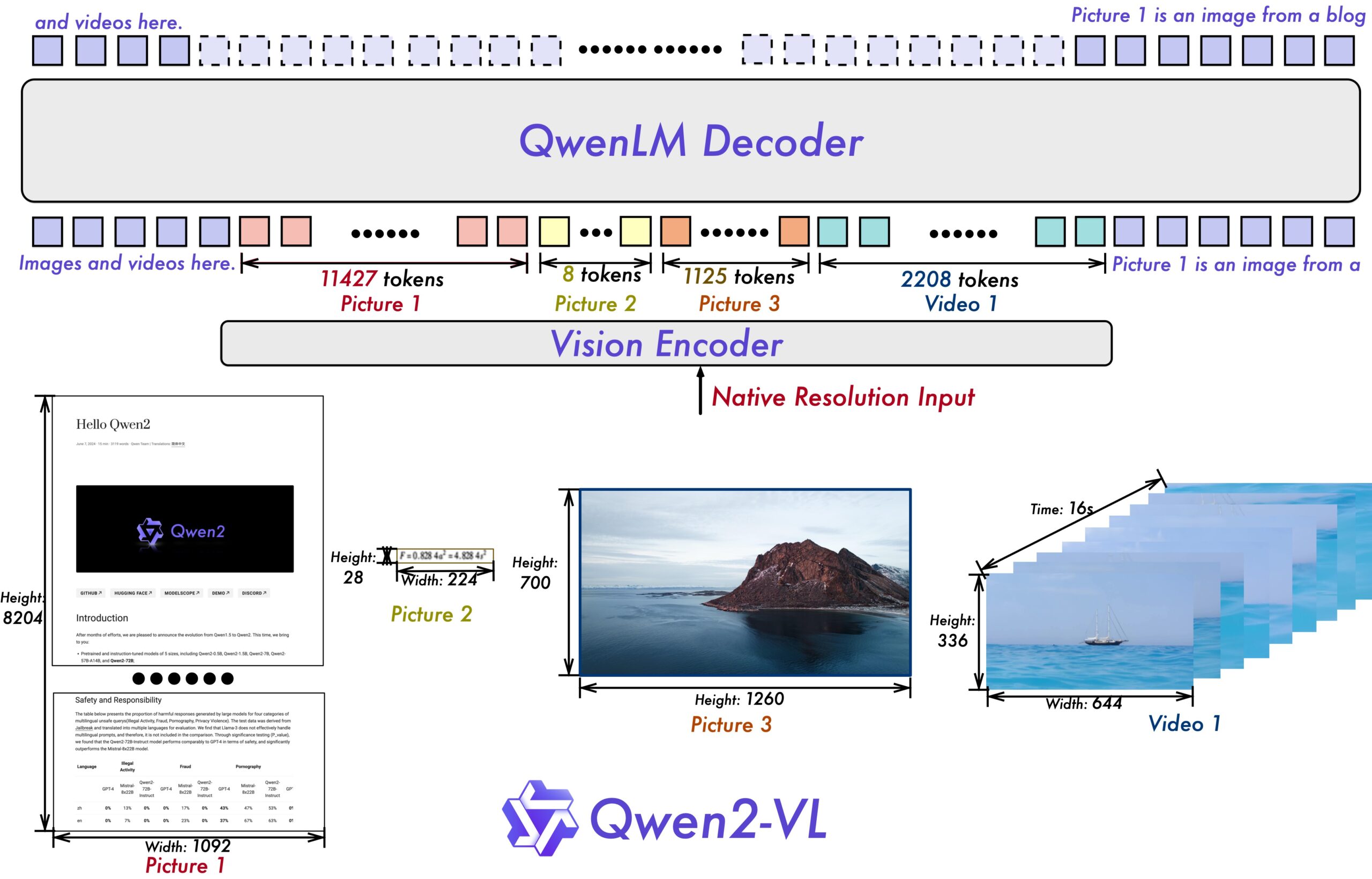 Qwen2-VL 继承了 Qwen-VL 的架构设计,并在此基础上进行了多项关键改进,以提升其视觉和语言处理能力,特别是在图像和视频输入的处理方面。以下是 Qwen2-VL 的主要架构特点:
Qwen2-VL 继承了 Qwen-VL 的架构设计,并在此基础上进行了多项关键改进,以提升其视觉和语言处理能力,特别是在图像和视频输入的处理方面。以下是 Qwen2-VL 的主要架构特点:
- 视觉Transformer (ViT)模型:
- Qwen2-VL 使用了大约600M参数的视觉Transformer (ViT)模型,专门用于处理图像和视频输入。ViT模型的使用使得Qwen2-VL能够有效地感知和理解视觉信息,适应各种输入类型,包括静态图像和动态视频。
- Naive Dynamic Resolution 支持:
- Qwen2-VL 引入了 Naive Dynamic Resolution 技术,允许模型处理任意分辨率的图像。这种技术通过将图像映射为动态数量的视觉标记(visual tokens),确保了模型输入与图像中的固有信息之间的一致性。这种方法更贴近人类视觉感知,能够处理任意清晰度或大小的图像。
- 多模态旋转位置嵌入 (M-ROPE):
- 该架构创新性地引入了多模态旋转位置嵌入 (Multimodal Rotary Position Embedding, M-ROPE),将原始旋转嵌入分解为三个部分,分别代表时间和空间(高度和宽度)信息。M-ROPE 使得Qwen2-VL能够同时捕捉并整合一维文本、二维视觉和三维视频的位置信息,显著增强了模型的多模态处理能力。
- 多模态融合与推理:
- Qwen2-VL 在处理多模态数据(如文本、图像、视频)时,通过结合视觉Transformer和语言模型的能力,实现了高效的跨模态推理。这种融合使得模型能够在复杂场景中进行多层次的理解和分析。
- 开源与API集成:
- Qwen2-VL-2B和Qwen2-VL-7B模型均在Apache 2.0开源协议下发布,并集成到Hugging Face Transformers、vLLM等第三方框架中,方便开发者进行模型调用和部署。Qwen2-VL-72B模型则通过API提供使用,适用于需要更大模型能力的应用场景。
官方介绍:https://qwenlm.github.io/blog/qwen2-vl/
GitHub:https://github.com/QwenLM/Qwen2-VL
模型下载:https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
在线演示:https://huggingface.co/spaces/Qwen/Qwen2-VL
API:https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
Cleanup.picture 是一种基于人工智能的高级编辑工具,比其他克隆图章工具要好得多。像 adobe photoshop fix 这样的克隆工具需要背景参考,而我们的 AI 只需点击几下,就能真正猜出...