
步骤 1:准备图片
- 收集照片:准备10到20张你的自拍或照片,这些照片应展示不同的姿势和背景。
- 命名规则:为了便于检索,请使用相同的前缀给每张照片命名(例如:“Heather1, Heather2”)。
- 可选步骤:可以将所有照片放入一个文件夹或压缩文件中。

步骤 2:开始训练
- 访问模型:前往模型页面,点击“Train a FLUX LoRA”按钮。
- 添加图片:在训练界面中,点击“Add Images”或“Pick a .zip file”按钮,将你的照片添加到训练中。
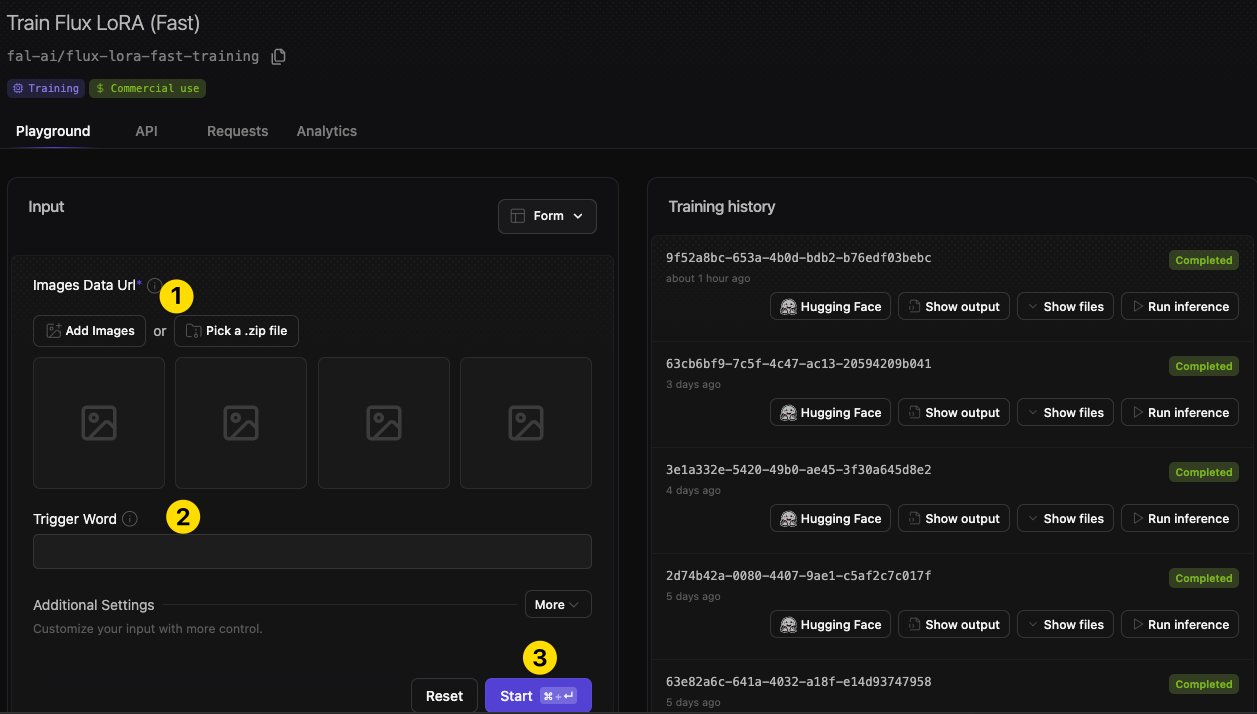
- 设置触发词:输入一个与你的图片文件名中包含的关键词——例如,“Heather”。
- 启动训练:点击“Start”按钮,开始训练。训练过程大约需要5分钟。
步骤 3:生成提示
- 运行推理:当训练状态显示“Completed”时,点击“Run Inference”按钮,开始生成提示词。
视频播放器
00:00
00:00
费用与其他信息
- 训练费用:在Fal上训练FLUX LoRA的费用为2美元。
- 创建仓库:你可以在训练页面创建一个Hugging Face 仓库来保存你的模型。
Support authors and subscribe to content
This is premium stuff. Subscribe to read the entire article.
Login if you have purchased
Mootion让你可以通过简单的文字描述来生成3D角色的动作。