全球最强的开源模型:Reflection 70B。它使用了一种名为“Reflection-Tuning 反思调优”的技术进行训练,该技术教会模型在推理过程中发现自己的错误并进行自我修正。Reflection 70B 在多个基准测试(MMLU、MATH、IFEval、GSM8K)上超越了顶级闭源模型(如 GPT-4o 和 Claude 3.5 Sonnet),并击败了 Llama 3.1 405B。
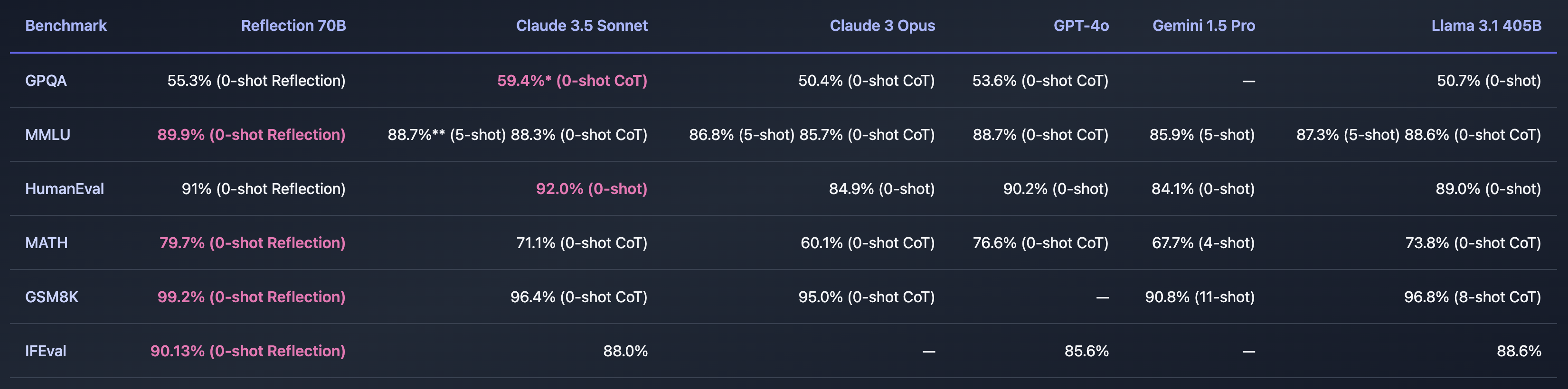 该模型通过将规划过程分离为独立步骤来提高链式思维(CoT)的效果,并保证输出简洁明了。此外,开发团队确保了数据的去污处理。
该模型通过将规划过程分离为独立步骤来提高链式思维(CoT)的效果,并保证输出简洁明了。此外,开发团队确保了数据的去污处理。
AImReply 是一款可帮助您在几秒钟内制作专业、个性化且引人入胜的电子邮件回复的在线 AI 工具。