Vchitect 2.0 是由上海人工智能实验室开发的视频生成模型,它支持通过文本和图像生成5 到 20 秒的高清短视频,用户可以灵活调整视频的宽高比。该模型集成了超分辨率和帧插入功能,支持内容修正,生成的视频更加流畅。
- 文本到视频生成:用户可以通过文本提示生成 5-20 秒的视频
- 图像到视频转换:允许将静态图像转换为 5-10 秒的视频
- 灵活的宽高比:允许用户生成任意宽高比的视频。
- 高清质量和集成的超分辨率和帧插入,具有用户可调节的内容校正功能。
 模型功能特点
模型功能特点
-
高质量视频生成:
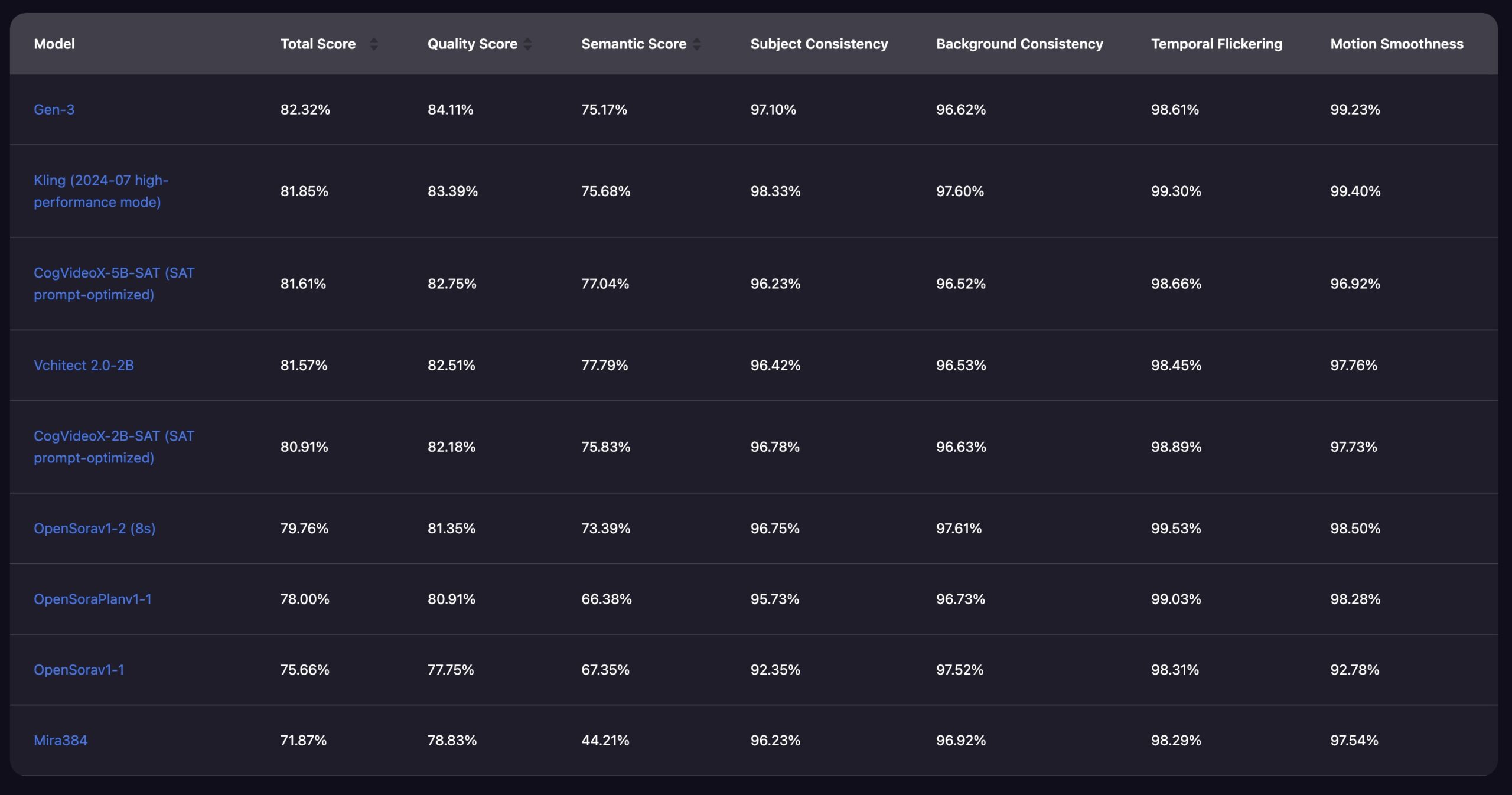
- Vchitect 2.0 是一个具备20 亿参数的视频生成模型,能够生成10-20 秒长度的高质量视频,分辨率最高支持 720×480。未来还计划推出拥有 50 亿参数的更大版本模型,进一步提升生成能力。
-
灵活的分辨率和时长:
- 该模型支持多种视频宽高比的生成,用户可以灵活选择视频的分辨率和时长,使其更加适应不同应用场景的需求。
-
时空增强框架:
- VEnhancer 是 Vchitect 2.0 的一个时空增强模块,能够对生成视频进行超分辨率处理和帧插入,使视频达到2K 分辨率和 24 FPS 的标准,进一步提升视频的视觉质量和流畅度。
-
文本到视频和图像到视频:
- Vchitect 2.0 支持通过文本提示生成视频,也可以将静态图像转换为视频,为用户提供多种创作方式。
一些案例
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
长视频剪辑
视频播放器
00:00
00:00
视频播放器
00:00
00:00
视频播放器
00:00
00:00
官网:https://vchitect.intern-ai.org.cn/
GitHub:https://github.com/Vchitect
超级简历,智能简历在线编辑工具,提供很多可直接使用的优秀简历模板。