
Meta AI 发布 Llama 3.2多模态AI模型,旨在提供强大的自然语言处理和图像理解能力。其设计目标是提高AI在边缘计算和移动设备上的性能,
Llama 3.2包括适用于边缘和移动设备的小型和中型视觉大语言模型(11B 和 90B)以及轻量文本模型(1B 和 3B)。
- 多模态处理能力
- LLaMA 3.2支持同时处理文本、图像和视频,能够理解并生成跨媒体内容,增强用户体验。例如,用户可以在同一交互中结合文字和图像。
- 高效边缘计算
- 模型经过优化,能够在边缘设备上高效运行,降低延迟并提高响应速度。这使得实时应用(如视频通话中的AI助手)成为可能。
- 改进的上下文理解
- 通过增强的上下文处理能力,LLaMA 3.2能够更好地理解复杂对话,并进行多轮交流,使得人机互动更加自然流畅。
Llama 3.2 系列中最大的两个模型,11B 和 90B,支持图像推理用例,如文档级理解,包括图表和图形的理解、图像说明以及基于自然语言描述的视觉定位任务。例如,一个人可以询问自己的小企业在去年哪一月份销售最好,Llama 3.2 可以基于可用图表进行推理并快速提供答案。在另一个示例中,模型可以根据地图进行推理,并帮助回答诸如何时徒步旅行可能变陡峭或某条特定小径的距离等问题。11B 和 90B 模型还可以通过从图像中提取细节、理解场景,然后构造一两句话作为图像说明来填补视觉和语言之间的鸿沟,从而帮助讲述故事。
视频播放器
轻量级的 1B 和 3B 模型具有强大的多语言文本生成和工具调用能力。这些模型使开发者能够构建个性化的、本地智能应用程序,保护隐私,确保数据永远不会离开设备。例如,这样的应用程序可以帮助总结最近收到的 10 条消息,提取行动项,并利用工具调用直接发送后续会议的日历邀请。
模型评估
评估表明,Llama 3.2 的视觉模型在图像识别和一系列视觉理解任务中与领先的基础模型 Claude 3 Haiku 和 GPT4o-mini 竞争。3B 模型在遵循指令、总结、提示重写和工具使用等任务上超越了 Gemma 2 2.6B 和 Phi 3.5-mini 模型,而 1B 模型与 Gemma 竞争力相当。
在 150 多个基准数据集上评估了性能,这些数据集覆盖了多种语言。对于视觉大语言模型,我们评估了图像理解和视觉推理的基准性能。
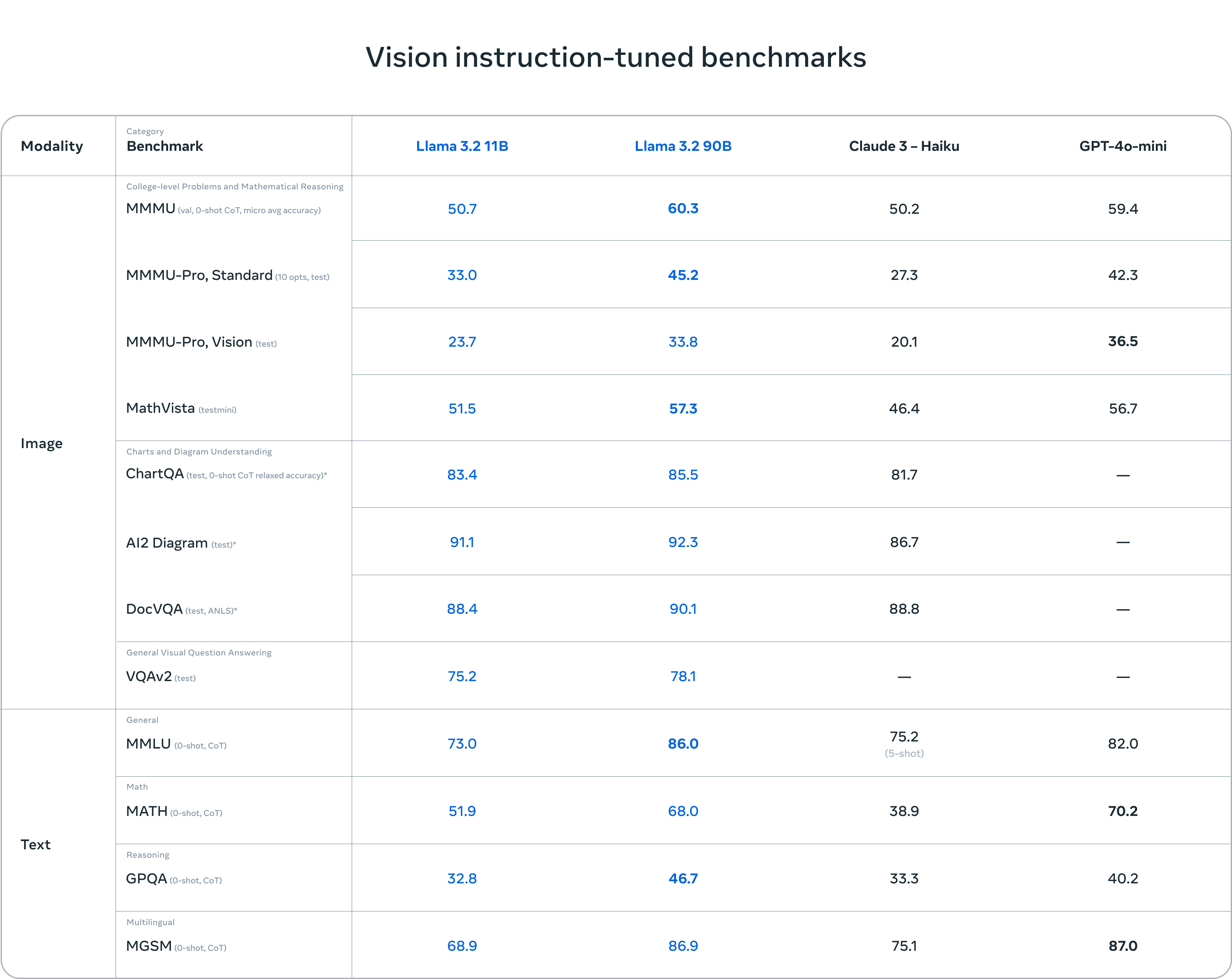
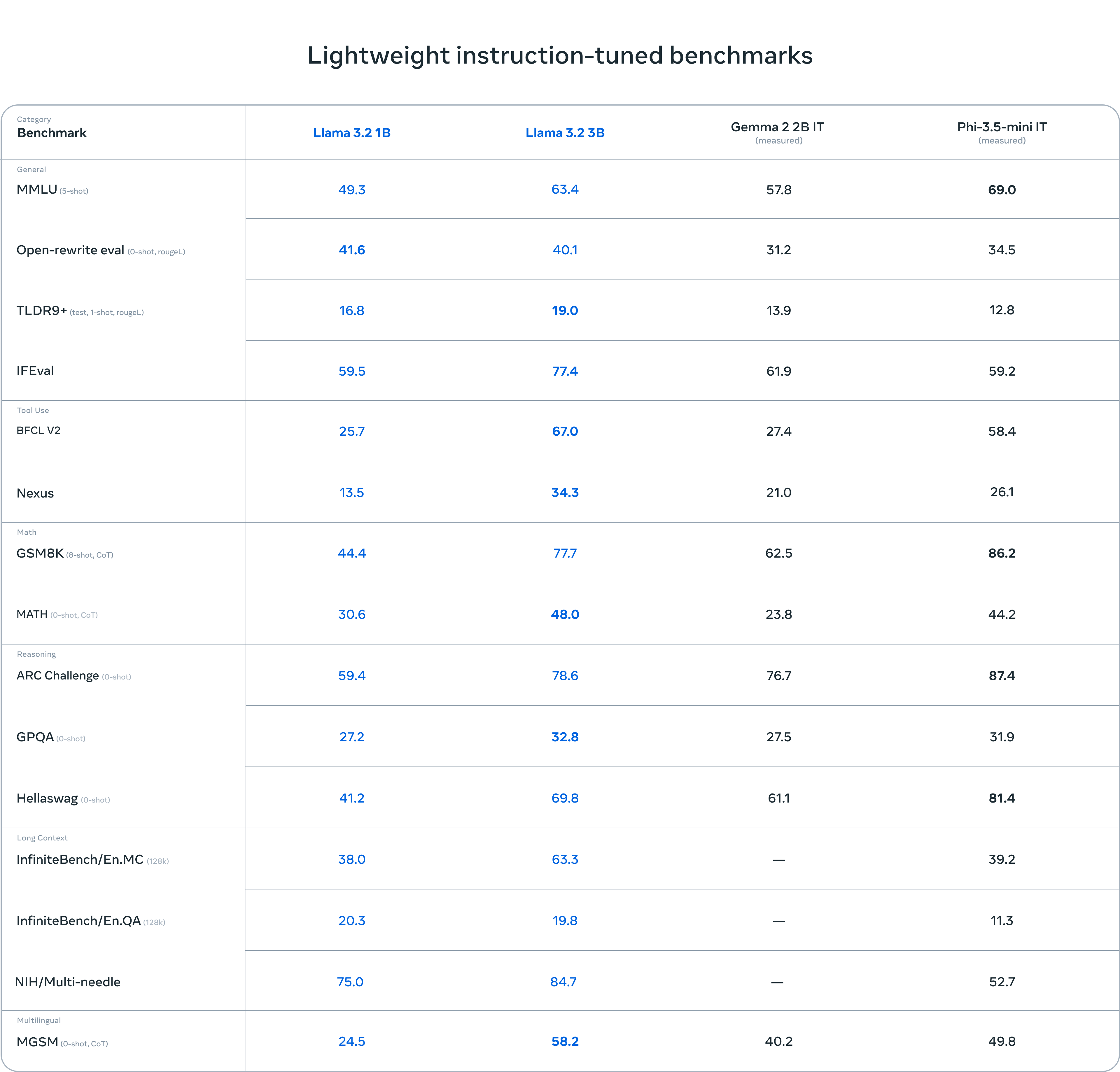
视觉模型
作为首批支持视觉任务的 Llama 模型,11B 和 90B 模型需要全新的模型架构以支持图像推理。
为了添加图像输入支持,Meta训练了一组适配器权重,将预训练的图像编码器整合到预训练的语言模型中。适配器由一系列交叉注意层组成,这些层将图像编码器的表示输入到语言模型中。在文本-图像对上训练适配器,以将图像表示与语言表示对齐。在适配器训练过程中,还更新了图像编码器的参数,但故意不更新语言模型参数。通过这种方式,保持了所有文本仅模型的能力,为开发者提供了 Llama 3.1 模型的直接替代。
训练管道由多个阶段组成,从预训练的 Llama 3.1 文本模型开始。首先,我们添加图像适配器和编码器,然后在大规模噪声(图像,文本)对数据上进行预训练。接下来,我们在中等规模的高质量领域内和知识增强的(图像,文本)对数据上进行训练。
在后期训练中,我们使用与文本模型类似的配方,通过多轮对监督微调、拒绝采样和直接偏好优化进行调整。我们利用合成数据生成,使用 Llama 3.1 模型过滤和增强基于领域内图像的问题和答案,并使用奖励模型对所有候选答案进行排名,以提供高质量的微调数据。我们还增加了安全缓解数据,以生产出具有高安全性的模型,同时保留模型的实用性。
最终结果是一组能够接受图像和文本提示并对其组合进行深刻理解和推理的模型。这是 Llama 模型拥有更丰富的自主能力的又一步。
轻量模型
Llama 3.2 1B 和 3B 模型使用了修剪和蒸馏两种方法,使它们成为首批高效适配设备的小型 Llama 模型。
修剪能够在保持尽可能多的知识和性能的同时减少 Llama 群体中现有模型的大小。对于 1B 和 3B 模型,采用从 Llama 3.1 8B 模型中一次性结构修剪的方法。这涉及系统性地移除网络的一部分,并调整权重和梯度的大小,以创建一个较小、更高效的模型,保留原始网络的性能。
知识蒸馏使用一个较大的网络来向较小的网络传授知识,意在使小模型在有教师的情况下能够比从头开始实现更好的性能。在 Llama 3.2 的 1B 和 3B 模型中,模型开发的预训练阶段,将来自 Llama 3.1 8B 和 70B 模型的 logits 纳入其中,这些较大模型的输出(logits)用作标记级目标。知识蒸馏是在修剪后进行的,以恢复性能。
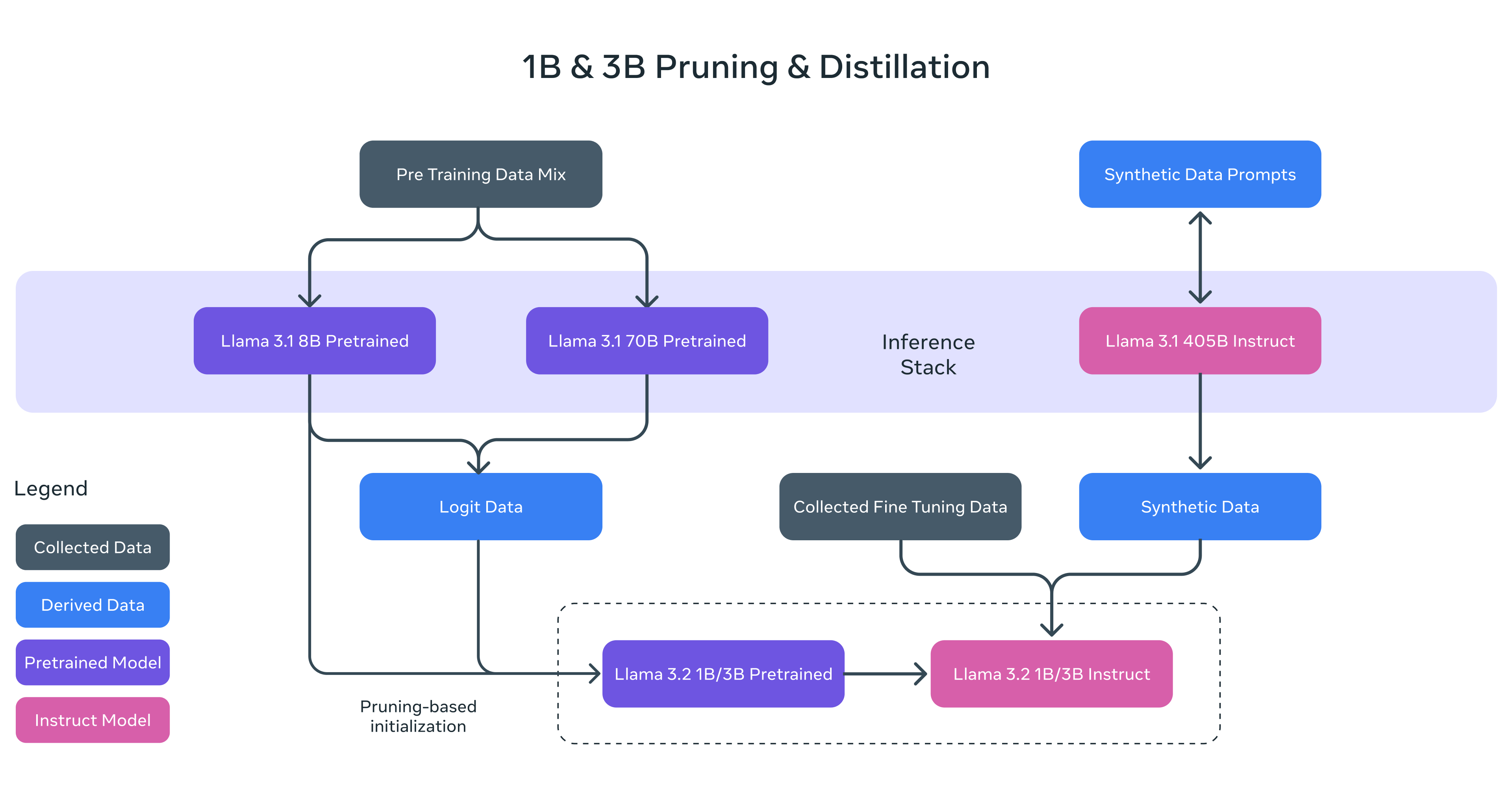 在后期训练中,使用与 Llama 3.1 相似的配方,通过多轮对预训练模型的调整,生成最终聊天模型。每轮涉及监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)。
在后期训练中,使用与 Llama 3.1 相似的配方,通过多轮对预训练模型的调整,生成最终聊天模型。每轮涉及监督微调(SFT)、拒绝采样(RS)和直接偏好优化(DPO)。
在后期训练中,将上下文长度支持扩展到 128K 个令牌,同时保持与预训练模型相同的质量。Meta还进行合成数据生成,经过仔细的数据处理和过滤,以确保高质量。我们仔细混合数据,以在摘要、重写、指令跟随、语言推理和工具使用等多种能力上优化高质量。
为了促进社区在这些模型上的创新,Meta与全球领先的移动系统芯片公司,如Qualcomm和MediaTek,以及为99%移动设备提供基础计算平台的Arm,进行了紧密合作。今天发布的模型权重采用了BFloat16数值格式,这使得新一代硬件能够得到更好的利用。Meta期待基于LLaMA 3.2开发的新应用和功能,这些应用将显著提升移动设备和边缘AI的能力。
详细内容:https://ai.meta.com/blog/llama-3-2-connect-2024-vision-edge-mobile-devices
Audo Studio,使用最新的音频处理和人工智能技术,自动去除背景噪音,噪音消除、声音平衡、音量调节并增强你的语音。