动作识别模型有哪些
发布时间:2024年06月06日
动作识别模型主要有:
· TWO-STREAM CNN:网络顾名思义分为两个部分,一部分处理RGB图像,一部分处理光流图像。最终联合训练。
· TSN:是在two-Stream CNN基础上改进的网络。目前基于two-stream的方法基本上是由TSN作为骨干网络。
· C3D:主要思想为用三维的卷积核处理视频。
· RNN:因为视频除了空间维度外,最大的痛点是时间序列问题,因此不少人希望使用RNN来解决问题
除此之外,还有TRN模型,SlowFast模型,TSM模型等等...
TWO STREAM方法
Two-Stream方法是深度学习在动作识别方向的一大主流方向。最早是VGG团队在NIPS上提出来的。其实在这之前也有人尝试用深度学习来处理动作识别,例如李飞飞团队通过叠加视频多帧输入到网络中进行学习,但不幸的是这种方法比手动提取特征更加糟糕。当Two-Stream CNN出来后才意味着深度学习在动作识别中迈出了重大的一步。
TWO-STREAM CNN
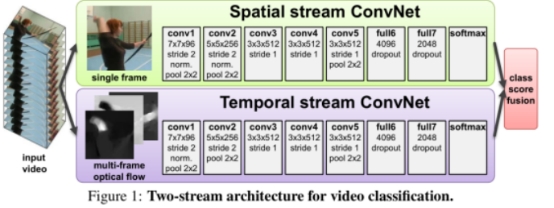
Two-Stream CNN网络顾名思义分为两个部分,一部分处理RGB图像,一部分处理光流图像。最终联合训练,并分类。这篇文章主要有以下三个贡献点。
1. 论文提出了two-stream结构的CNN网络,由空间(RGB)和时间(光流)两个维度的网络组成;
2. 作者提出了利用网络训练多帧密度光流,以此作为输入能在有限训练数据的情况下取得不错的结果;
3. 采用多任务训练的方法将两个动作分类的数据集联合起来,增加训练数据,最终在两个数据集上都取得了更好的效果(作者提到,联合训练也可以去除过拟合的可能)。
网络结构: 因为视频可以分为空间和时间两个部分。空间部分,每一帧代表的是空间信息,比如目标、场景等等。而时间部分是指帧间的运动,包括摄像机的运动或者目标物体的运动信息。所以网络相应的由两个部分组成,分别处理时间和空间两个维度。每个网络都是由CNN和最后的softmax组成,最后的softmax的fusion主要考虑了两种方法:平均,在堆叠的softmax上训练一个SVM。网络的结构图如下所示。
光流栈,或者叫做光流的简单叠加。简单的来说就是计算每两帧之间的光流,然后简单的stacking。
考虑对一小段视频进行编码,假设起始帧为T,连续L帧(不包含T帧)。计算两帧之间的光流,最终可以得到L张光流场,每张光流场是2通道的(因为每个像素点有x和y方向的移动)。
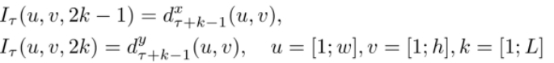
最后将这些光流场输入,得到相应的特征图。 该方法在UCF-101和HMDB-51上取得了与iDT系列最好的一致效果。在UCF-101上准确度为88.0%,在HMDB上准确度为59.4%。
TSN
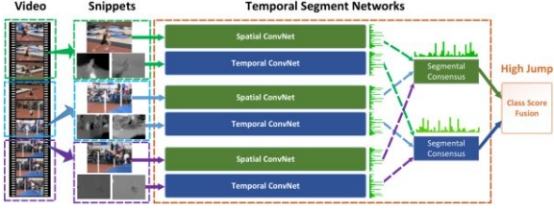
TSN(Temporal Segments Networks)[5]是在two-Stream CNN基础上改进的网络。目前基于two-stream的方法基本上是由TSN作为骨干网络。
two-stream方法很大的一个弊端就是不能对长时间的视频进行建模,只能对连续的几帧视频提取temporal context。为了解决这个问题,TSN网络提出了一个很有用的方法,先将视频分成K个部分,然后从每个部分中随机的选出一个短的片段,然后对这个片段应用上述的two-stream方法,最后对于多个片段上提取到的特征做一个融合。下图是网络的结构图。
C3D方法
C3D(3-Dimensional Convolution)[6]是Two-Stream之外的另一大主流方法,但是目前来看C3D的方法得到的效果普遍比Two-Stream方法低好几个百分点。但是C3D仍然是目前研究的热点,因为该方法比Two-Stream方法快很多,而且基本上都是端到端的训练,网络结构更加简洁。该方法思想非常简单,图像是二维,所以使用二维的卷积核。视频是三维信息,那么可以使用三维的卷积核。所以C3D的意思是:用三维的卷积核处理视频。
网络结构:
C3D共有8次卷积操作,5次池化操作。其中卷积核的大小均为333,步长为111。池化核为222,但是为了不过早的缩减在时序上的长度,第一层的池化大小和步长为122。最后网络再经过两次全连接层和softmax层后得到最终的输出结果。网络的输入为316112112,其中3为RGB三通道,16为输入图像的帧数,112112是图像的输入尺寸。

RNN方法
因为视频除了空间维度外,最大的痛点是时间序列问题。而众所周知,RNN网络在NLP方向取得了傲人的成绩,非常适合处理序列。所以除了上述两大类方法以外,另外还有一大批的研究学者希望使用RNN网络思想来解决动作识别问题。
典型工作有中科院深圳先进院乔宇老师的工作:《RPAN:An End-to-End Recurrent Pose-Attention Network for Action Recognition in Videos》[7]。这篇文章是ICCV2017年的oral文章。但是与传统的Video-level category训练RNN不同,这篇文章还提出了Pose-attention的机制。

这篇文章主要有以下几个贡献点:
1. 不同于之前的pose-related action recognition,这篇文章是端到端的RNN,而且是人体姿态的时空演变;
2. 不同于独立的学习关节点特征(human-joint features),这篇文章引入的pose-attention机制通过不同语义相关的关节点(semantically-related human joints)分享attention参数,然后将这些通过human-part pooling层联合起来;
3. 视频姿态估计,通过文章的方法可以给视频进行粗糙的姿态标记。
此外,RNN方向比较新的研究包括如下:
1. 2018 Zhenxing ZHENG等人的《Multi-Level Recurrent Residual Networks for Action Recognition》,提出了一种新的多层次循环残差网络(MRRN),它结合了三种识别流。每个流由一个剩余网络(resnet)和一个循环模型组成。该模型通过使用两个可选的网格从静态帧中学习空间表示,并使用叠加简单循环单元(SRU)来建模时间动态,从而捕获时空信息。通过计算SoftMax分数的加权平均值来融合三个独立学习的低、中、高级别表示的不同级别流,以获得视频的互补表示。与以前以时间复杂度和空间复杂度为代价提高性能的模型不同,该模型通过使用快捷连接降低了复杂度,并以更高的效率进行端到端培训。与CNN-RNN框架基线相比,MRRN显示出显著的性能改进,并获得了与最新技术相当的性能,在HMDB-51数据集上达到51.3%,在UCF-101数据集上达到81.9%,尽管没有额外的数据。
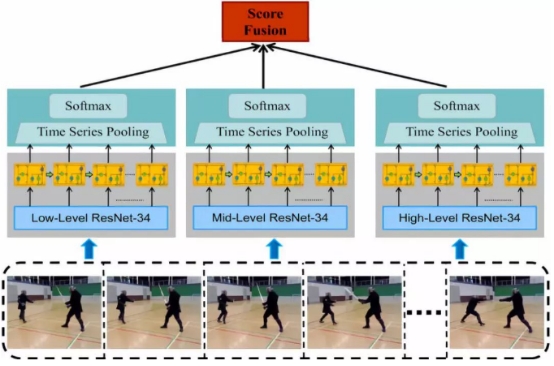
2. 2019年Lin Sun等人的《Coupled Recurrent Network (CRN)》,提出了一种新的循环结构,称为耦合循环网络(CRN),用于处理多个输入源。在CRN中,RNN的并行流耦合在一起。CRN的关键设计是一个循环解释块(RIB),它支持以循环方式从多个信号中学习互易特征表示。与在每个时间步或最后一个时间步叠加训练损失的RNN不同,也提出了一种有效的CRN训练策略。实验证明了该方法的有效性。特别是,在人类动作识别和多人姿态估计的基准数据集上取得了新的进展。
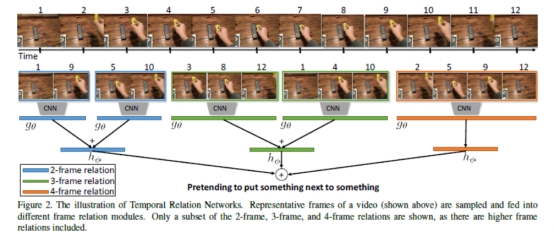
TRN
本文是对TSN最后融合方式做一个改进。TSN每个snippet独立地预测,而TRN在预测前先进行snippet间的特征融合。另外TRN的输入用的是不同帧数的snippet(different scale)。 下图的框架图一目了然,算法实现流程就是先均匀地采样出不同scale的Segment 来对应 2-frame, 3-frame, …, N-frame relation;然后对每个Segment里小片提取 Spatial feature,进行 MLP 的 temporal fusion,送进分类器;最后将不同scale的分类score叠加来作最后预测值。 图中g是两层MLP。h是一层MLP,其输出维度是类别数。
TSM
Motivation:3D网络的计算量大,而2D网络没有利用时序信息。提出了时间移位(temporal shift)模块,能够用2D网络对时间建模。即将当前帧的特征图部分通道替换为前一帧或后一帧的通道。
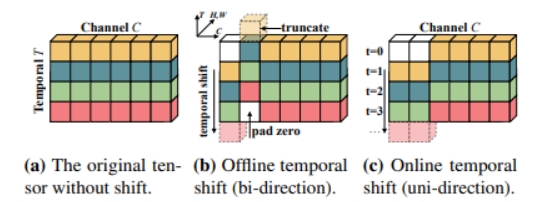
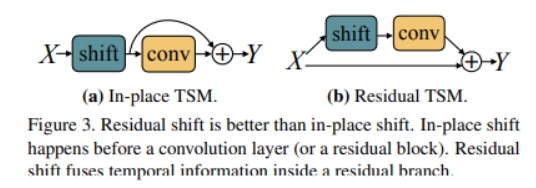
图(a)是原始的特征图(省略了batchsize,w,h这三个与讨论无关的维度),图(b)包括将前一帧和后一帧的通道替换当前帧的通道,适用于离线的方式。视频首尾帧对应位置用零填充。图©仅有前一帧的通道,适用于在线的方式。 temporal shift 模块应该作为原来2D网络的补充(即放在残差分支上,如下图(b)),而不能放在主干网络(如下图(a)),否则会破坏当前帧的空间语义。
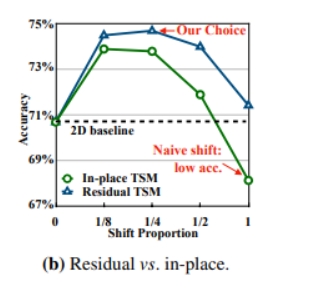
下图显示了in-place和residual两种不同方式,以及其他帧特征的不同占比带来的效果。
SlowFast
Motivation:1,在视频动作识别中,类别语义一般变化得较慢,而动作语义变化得较快 2,人眼有20%的m细胞和80%的p细胞。m细胞在高时间频率下工作,对快速的时间变化有反应,但对空间细节或颜色不敏感。p细胞相反。 所以设计了两路卷积神经网络,一路用来捕获不变或变化较慢的语义信息,称为Slow pathway,一路用来捕获快速变化的语义信息,称为Fast pathway。
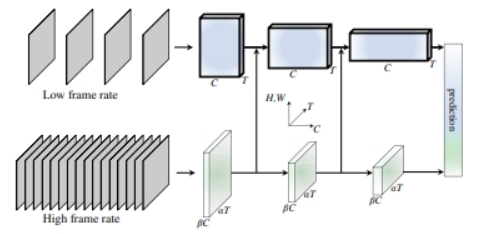
Slow分支的帧采样更稀疏,因此会更侧重不变的语义(空间信息),而Fast 分支的帧采样更密集且通道数更少(限制了表达能力),因此会更侧重变化(语义)的语义。 如果想要Fast分支更少关注空间信息,可以对Fast分支的输入作以下尝试:将帧宽高分别减半; 将帧灰度化;换成光流; 换成前后帧之差 为了维持时间维度上的高分辨率,Fast分支没有时间维度的下采样操作(池化或带孔卷积) Fast分支有侧向连接到Slow分支。这是一个在目标检测和视频理解很常用的手段。可供选择的方法如下:

下面是以resnet50为backbone的SlowFast

1. Slow分支前面的层不宜用时间维度步长大于1的卷积核(称为非退化(non-degenerate)核,即非退化到2D卷积核),否则准确率会下降。可能原因是浅层网络空间感受野不大,如果目标运动速度快的话相邻帧的同一位置上的语义可能没什么联系。
2. 为了捕获时间上的联系,Fast分支宜用非退化核
一个免费的AI生成的图库,提供各种各样的高质量图片供商业和个人使用。StockCake所有照片都完全免费且属于公共领域。