24年首篇离奇论文:加点噪声,RAG效果翻倍?
发布时间:2024年06月06日
论文:《The Power of Noise: Redefining Retrieval for RAG Systems》
这篇论文探讨了基于检索增强的语言模型(RAG)系统中的信息检索(IR)组件对系统性能的影响。与传统的大型语言模型相比,RAG系统通过引入外部数据提高了其生成能力。然而,大多数关于RAG系统的研究主要集中在语言模型的生成方面,而忽略了IR组件的作用。本研究通过对各种元素进行评估,如文档的相关性、位置和数量等,发现包括不相关文档可以意外地提高准确性超过30%,这与我们的初始假设相反。这些结果强调了开发专门策略以整合检索和语言生成模型的重要性,并为未来的研究奠定了基础。
论文方法
方法描述
本文介绍了使用RAG(Retrieve and Generate)框架来解决开放域问答问题的方法。该方法包括两个主要组件:检索器和生成器。在检索器中,使用密集检索方法将查询和文档转换为高维向量表示,并计算它们之间的相似度得分。然后根据得分排序并选择最相关的文档作为输入传递给生成器。生成器是一个基于语言模型的序列到序列模型,它接收查询和选定的文档作为输入,并预测下一个可能的单词或短语,以生成回答。
方法改进
本文提出的RAG框架结合了检索器和生成器的优点,解决了传统单一模型无法处理复杂、多样化的查询的问题。相比于传统的基于关键词匹配的检索方法,密集检索能够更好地理解文本的语义关系,从而提高检索结果的质量。同时,通过引入生成器,可以利用大量文本数据训练出强大的语言模型,进一步提升系统的性能。
解决的问题
本文提出的RAG框架主要用于解决开放域问答问题,即需要针对各种类型的自然语言问题提供准确且上下文相关的答案。与传统的单一模型相比,RAG框架具有更高的灵活性和适应性,能够处理更复杂的查询,并在多种下游任务上取得更好的表现。此外,本文还探讨了如何优化检索器的选择策略,以提高整个系统的效果。
论文实验
本文主要介绍了关于基于知识图谱的问答系统(RAG)中如何优化问题回答效果的研究。作者进行了多个对比实验来探究不同的因素对RAG系统性能的影响,并总结出了一些关键发现。
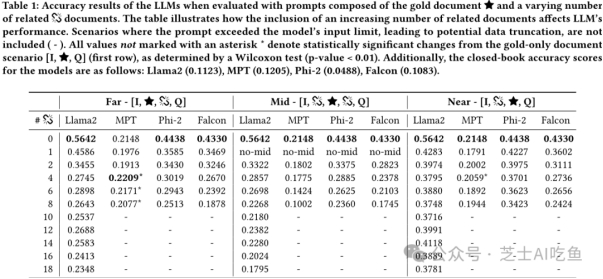
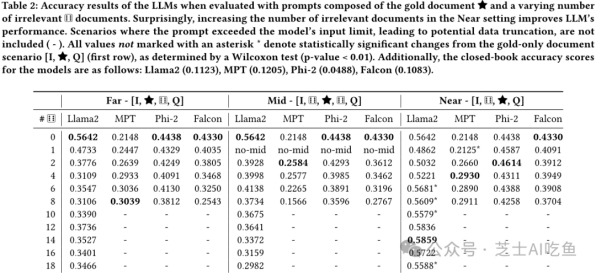
首先,作者研究了在添加相关但不包含答案的文档时,RAG系统的准确率会显著下降。这表明区分相关和非相关信息是RAG系统的一个挑战。然后,作者通过将黄金文档放置在不同位置来研究其对模型性能的影响。结果表明,在查询旁边放置黄金文档可以提高准确率,而将其放在中间或远处则会降低准确率。此外,作者还研究了随机无关文档的引入对RAG系统性能的影响。结果表明,无论是在更接近查询的位置还是在更远的位置添加无关文档,都会提高准确率。
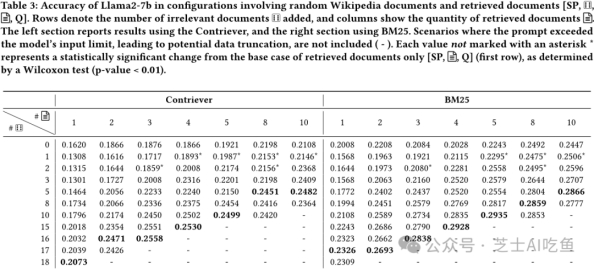
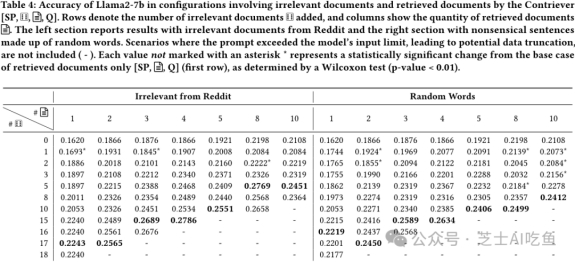
最后,作者进行了一个更具实际意义的实验,即从Wikipedia语料库中检索一组文档并添加一些无关文档,以模拟现实世界中的应用场景。结果显示,添加无关文档几乎总是有益于准确率的提高,甚至在增加更多无关文档的情况下也是如此。
总的来说,这些实验揭示了RAG系统的一些局限性和优化方向,为未来的研究提供了有价值的参考。
论文总结
文章优点
·
该论文是首个全面研究如何影响RAG框架的检索文档的研究,旨在了解优化RAG系统提示构造所需的特征。
·
研究结果发现相关文档比无关文档更有害于RAG系统,并且当放置正确时,无关但噪声的文档实际上有助于提高系统的准确性。
·
论文提出了利用这些发现的方法策略,并指出需要进一步研究以揭示这种行为背后的内在机制并开发更适合与生成组件交互的新一代信息检索技术。
方法创新点
·
该论文首次将注意力集中在RAG系统中的IR方面,探讨了在RAG系统中优化提示构建所需的关键特征。
·
研究者通过比较不同类型的文档(相关、相关和无关)对RAG系统的影响,发现了相关文档比无关文档更有害于RAG系统,并且当放置正确时,无关但噪声的文档实际上有助于提高系统的准确性。
·
研究者提出了一些利用这些发现的方法策略,例如在提示中加入更多相关信息等。
未来展望
·
进一步研究可以揭示这种行为背后的内在机制,并开发更适合与生成组件交互的新一代信息检索技术。
·
可以考虑使用更复杂的模型来捕捉上下文之间的关系,从而更好地处理长文本。
·
可以探索其他类型的信息检索技术,如基于知识图谱或语义解析的技术,以进一步提高RAG系统的性能。
出自:https://mp.weixin.qq.com/s/G0OJmQi03bfN5d6csaqmFA
一种 AI 驱动的贴纸生成工具,Stipop根据用户的输入提示生成贴纸设计,从而产生可用于各种在线和离线应用程序的独特设计。