将任意文本转换为知识图谱
发布时间:2024年06月06日
项目简介
知识图谱,也称为语义网络,表示现实世界实体的网络,即物体、事件、情况或概念——并说明它们之间的关系。这些信息通常存储在图形数据库中并可视化为图形结构,从而产生了知识“图形”一词。
如何从大量工作中创建一个简单的知识图谱?
00001. 清理文本语料库(作品主体)。
00002. 从工作主体中提取概念和实体。
00003. 提取实体之间的关系。
00004. 转换图形模式。
00005. 填充节点(概念)和边(关系)。
00006. 可视化和查询。
第 6 步纯粹是可选的,但它具有一定的艺术满足感。网络图是美丽的对象(只要看看上面的横幅图片,是不是很漂亮?)。幸运的是,有大量的 Python 库可用于生成图形可视化。
为什么要绘制图表?
一旦知识图(KG)构建完成,我们就可以将它用于多种目的。我们可以运行图算法并计算任何节点的中心性,以了解概念(节点)对于这项工作的重要性。我们可以计算社区,将概念组合在一起,以便更好地分析文本。我们可以理解看似互不相关的概念之间的联系。
最重要的是,我们可以实现图检索增强生成(GRAG),并使用图作为检索器以更深刻的方式与我们的文本聊天。这是检索增强生成(RAG)的新改进版本,我们使用矢量数据库作为检索器来与我们的文档聊天。
在这里,我从 PDF 文档创建了一个简单的知识图。我在这里遵循的过程与上面几节中概述的过程非常相似,但有一些简化。
流程
首先,我将整个文本分成块。然后我使用LLM提取每个块中提到的概念。请注意,我在这里没有使用 NER 模型提取实体。概念和实体之间存在差异。例如,“班加罗尔”是一个实体,“班加罗尔宜人的天气”是一个概念。根据我的经验,概念比实体更有意义。
我认为相邻提到的概念是相关的。因此,知识图谱中的每条边都是一个文本块,其中提到了两个相连的概念。
一旦计算出节点(概念)和边(文本块),就可以使用此处提到的库轻松创建它们的图形。我在这里使用的所有组件都是在本地设置的,因此该项目可以在个人计算机上非常轻松地运行。我在这里采用了无 GPT 方法来保持经济性。我正在使用出色的 Mistral 7B openorca 指令,它完美地粉碎了这个用例。该模型可以使用 Ollama 在本地设置,因此生成 KG 基本上是免费的(无需调用 GPT)。
要生成笔记本的图表,您必须进行调整。
extract_graph.ipynb
笔记本实现以下流程图中概述的方法。
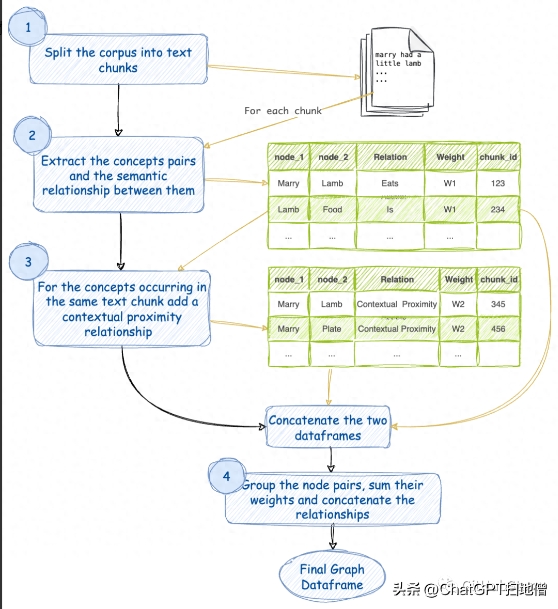
00001. 将文本语料库分割成块。为每个块分配一个 chunk_id。
00002. 对于每个文本块,使用LLM提取概念及其语义关系。让我们为这个关系分配一个权重 W1。同一对概念之间可以存在多种关系。每一个这样的关系都是一对概念之间的边缘。
00003. 考虑到同一文本块中出现的概念也通过它们的上下文邻近性而相关。让我们为这个关系分配一个权重 W2。请注意,同一对概念可能出现在多个块中。
00004. 对相似的对进行分组,对它们的权重进行求和,并连接它们的关系。所以现在我们在任何不同的概念对之间都只有一条边。边具有一定的权重和关系列表,如其名称所示。
另外,它还计算每个节点的度数和节点的社区,以分别调整图中节点的大小和着色。
项目链接
https://github.com/rahulnyk/knowledge_graph
出自:
https://www.toutiao.com/article/7313822852544430618/?app=news_article×tamp=1703032587&use_new_style=1&req_id=202312200836274061CA63C616B0444141&group_id=7313822852544430618&share_token=41CDDFEF-4578-412E-AA96-0AAF30E77AFC&tt_from=weixin&utm_source=weixin&utm_medium=toutiao_ios&utm_campaign=client_share&wxshare_count=2&source=m_redirect
燕雀智造Logo是一款智能在线LOGO设计工具,同时还提供了丰富的LOGO设计模板和工具。