腾讯开源混元AI绘画大模型
发布时间:2024年06月06日

最近大厂的大模型竞争激烈,百度的文心一言主打闭源和付费路线,阿里的通义千问主打开源免费路线,而腾讯的混元大模型,则不温不火。
到了初夏的五月,腾讯突然放出了混元大模型的开源版本(文生图模型)。
经常玩Stable Diffusion的都知道,腾讯在AI绘画大模型方面颇有造诣,很多ControlNet的模型都是腾讯出品,主打一个性价比优良。
基于此,腾讯推出AI绘画大模型也就在情理之中。
混元AI绘画大模型有什么特点呢?
一是中文原生,不需要经过转译的过程,大模型可以理解原生中文,这点很重要,要比Stable Diffusion加个翻译插件好得多,尤其是在古文直接生成图方面,有着强大的优势。
因为搭建环境比较繁琐,虽然开源,还没有安装使用,我就用混元大模型来进行展示。

这个画面质量非常强大,对古诗词的理解也很到位。
二是多轮对话。一次生成图片后,可以继续添加其他元素。
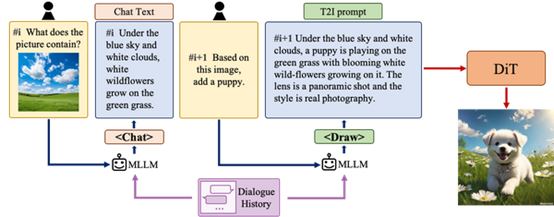
最终创作者可以通过一次次的对话引导至想要生成的图片。
为了全面比较混元大模型的生成能力,团队构建了一个4维测试集,包括文本-图像一致性、排除AI伪影、主体清晰度、美学。超过50名专业评估员进行评估。
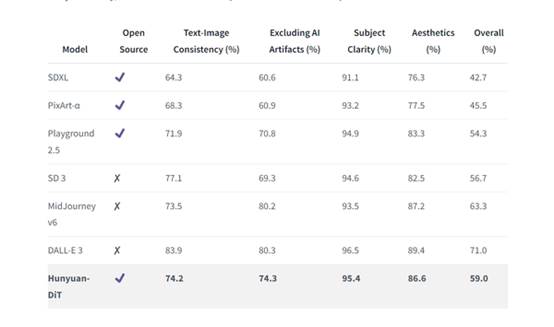
从对比来看,基本超越了MJ v6,遥遥领先SDXL,和SD3基本打平,距离微软的DALL-E3有一点差距。
考虑到这是一款开源产品,发布以后可以被其他创作者们魔改,尤其是在大模型的基础上进行深度训练,必然会远超其他AI绘画大模型(如果这个打分属实的话)。
不过,混元大模型的门槛不低,目前必须是NVIDIA显卡,最低配置是11G显存,推荐32G显存。尤其是推荐显存,这是让大多数玩家仰望的配置。
随着大模型的开源,相信会有更多的创作者参与调优,最终把硬件需求降下来。
具体安装和使用:
依赖关系和安装
首先克隆存储库:
git clone https://github.com/tencent/HunyuanDiT cd HunyuanDiT
我们提供了一个用于设置 Conda 环境的文件。Conda 的安装说明https://docs.anaconda.com/free/miniconda/index.html 获得。environment.yml
# 1. Prepare conda environment conda env create -f environment.yml # 2. Activate the environment conda
activate HunyuanDiT # 3. Install pip dependencies python -m pip install -r
requirements.txt # 4. (Optional) Install flash attention v2 for acceleration (requires CUDA
11.6 or above) python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.1.2.post3
下载预训练模型
要下载模型,请先安装
huggingface-cli。
python -m pip install "huggingface_hub[cli]"
然后使用以下命令下载模型:
# Create a directory named 'ckpts' where the model
will be saved, fulfilling the prerequisites for running the demo. mkdir ckpts # Use the huggingface-cli tool
to download the model. # The download time may vary
from 10 minutes to 1 hour depending on network conditions. huggingface-cli
download Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
注意:如果在下载过程中出现类似错误,您可以忽略该错误,然后通过执行命令重试No such file or directory:
'ckpts/.huggingface/.gitignore.lock'huggingface-cli download
Tencent-Hunyuan/HunyuanDiT --local-dir ./ckpts
所有模型都将自动下载。有关该模型的更多信息(免翻墙):https://hf-mirror.com/Tencent-Hunyuan/HunyuanDiT
|
型 |
#Params |
下载网址 |
|
mT5型 |
1.6乙 |
mT5型 |
|
夹 |
350米 |
夹 |
|
对话生成 |
7.0乙 |
对话生成 |
|
SDXL-VAE-FP16-修复 |
83 分钟 |
SDXL-VAE-FP16-修复 |
|
浑源-DiT |
1.5乙 |
浑源-DiT |
推理
使用 Gradio
在运行以下命令之前,请确保已激活 conda 环境。
# By default, we start a Chinese UI. python app/hydit_app.py # Using
Flash Attention for acceleration. python app/hydit_app.py --infer-mode fa # You
can disable the enhancement model if the GPU memory is insufficient. # The
enhancement will be unavailable until you restart the app without the
`--no-enhance` flag. python app/hydit_app.py --no-enhance # Start with English
UI python app/hydit_app.py --lang en
使用命令行
我们提供 3 种模式来快速启动:
# Prompt Enhancement + Text-to-Image. Torch mode python sample_t2i.py --prompt "渔舟唱晚" # Only Text-to-Image. Torch mode python sample_t2i.py
--prompt "渔舟唱晚" --no-enhance # Only Text-to-Image. Flash Attention mode python
sample_t2i.py --infer-mode fa --prompt "渔舟唱晚" # Generate an image with other image sizes. python
sample_t2i.py --prompt "渔舟唱晚" --image-size
1280 768
更多示例提示可以在 https://hf-mirror.com/Tencent-Hunyuan/HunyuanDiT/blob/main/example_prompts.txt 中找到
更多配置
为了便于使用,我们列出了一些更有用的配置:
|
论点 |
违约 |
描述 |
|
--prompt |
没有 |
用于生成图像的文本提示 |
|
--image-size |
1024 1024 |
生成图像的大小 |
|
--seed |
42 |
用于生成图像的随机种子 |
|
--infer-steps |
100 |
采样的步骤数 |
|
--negative |
- |
图像生成的负面提示 |
|
--infer-mode |
炬 |
推理模式(torch 或 fa) |
|
--sampler |
ddpm的 |
扩散采样器(ddpm、ddim 或 dpmms) |
|
--no-enhance |
假 |
禁用提示增强模型 |
|
--model-root |
CKPTS系列 |
模型检查点的根目录 |
|
--load-key |
均线 |
加载学生模型或 EMA 模型(ema 或模块) |
Bigmp4,使用先进人工智能 AI 模型,能将视频无损高清放大、增强画质、智能补帧使画面丝滑流畅栩栩如生同时支持黑白视频上色和慢动作。