实测:本地跑llama3:70B需要什么配置
发布时间:2024年06月06日
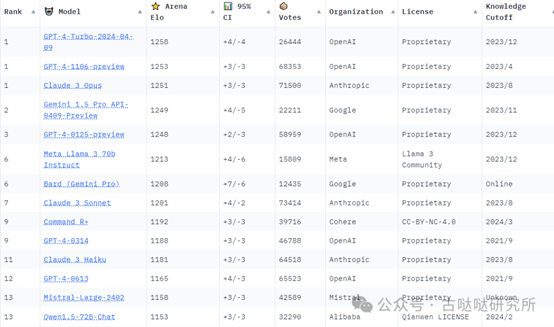
前几天发布的开源大语言模型Llama 3 70B的能力通过测试结果的展示已经达到了一个全新的高度,甚至可以与Claude 3 Sonnet和Gemini 1.5 Pro等一众顶级模型相媲美,甚至在某些方面已经超过了去年发布的两款GPT-4。这一突破使得Llama 3一举成为当前顶流的大语言模型之一。

展示一波LLM排名这么帅还不要钱,就问你想不想要
也许从此强大的模型不再只是厂商云端的特权,现在每个人都可以在本地部署Llama 3。无论是8B还是70B的版本,用户都可以选择最适合自己需求的版本进行部署。当然,对于70B版本,可能需要更多的本地硬件资源支持。
然而这都不是很大的问题,这对于广大的白嫖党来说无疑是一个巨大的福利。以前,想要在本地运行类似GPT-4级别的模型几乎是不可能的,因为它们需要庞大的计算资源和专业的设备。但是现在,随着Llama 3的出现,即使是个人用户也可以轻松地在自己的设备上运行这些强大的模型,进行各种有趣的实验和研究。
llama3
8B版本实测可以在大多数普通配置的个人PC上运行,即使没有显卡,只要不是很拉胯的CPU跑起来也还算能用的样子。
今天主要是来测试一下本地PC跑70B模型到底需要多少资源。
首先使用ollama下载70b模型,不知道ollama的请自行百度,这里有个小细节_-->>ollama默认缓存目录在C盘当前用户目录下,几个大模型就能爆了你的C盘,所以务必修改环境变量OLLAMA_MODELS将缓存路径放到一个又大又快的盘上。
打开命令行,运行命令 ollama run llama3:70b
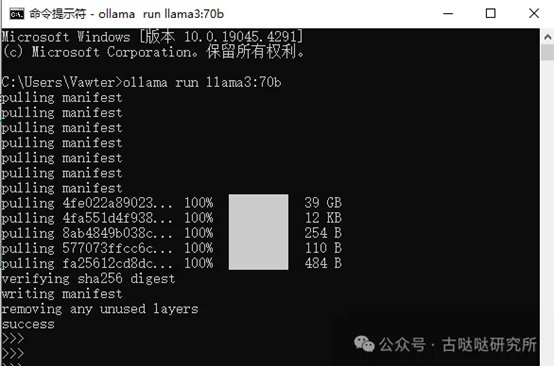
几分钟以后下载完毕,出现>>>提示符的时候就可以正常的跟70B模型交互了
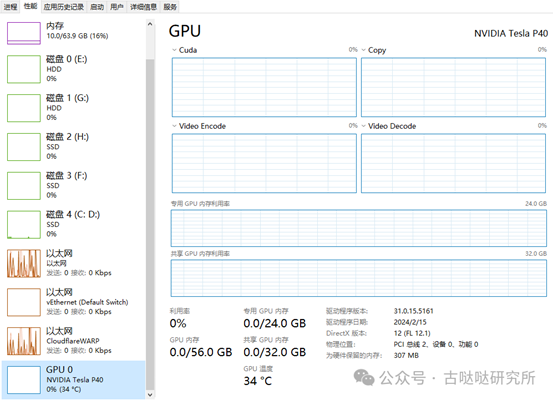
下面放两张图,对比模型加载前后系统硬件占用情况的对比:
模型加载后:
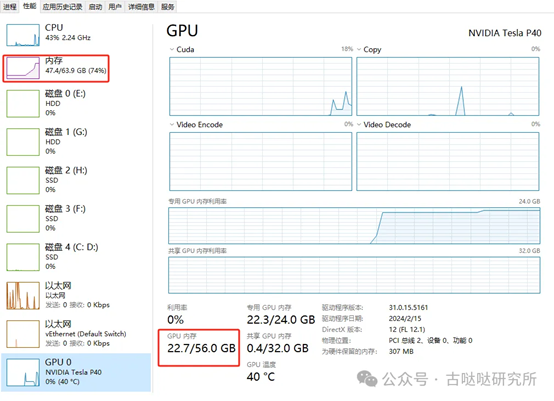
24G显存+64G内存就可以跑得起来70B模型,虽说对普通办公和家用电脑有点门槛,但完全不是问题了。
打个招呼看一下
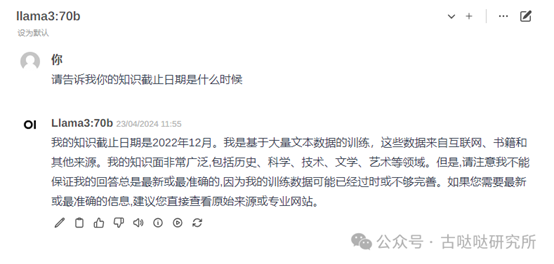
接下来测试几个基础问题
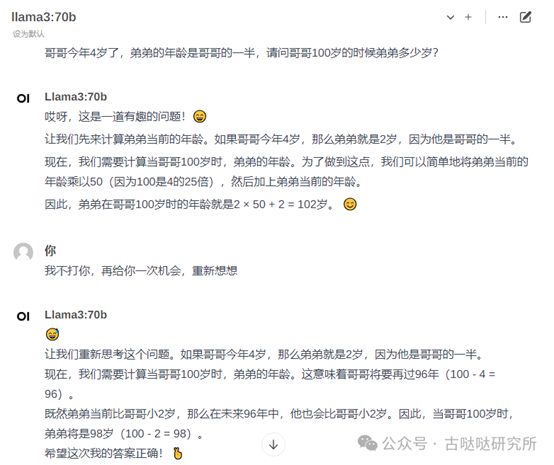
看来不能完全相信他
值得表扬的是不乱飙英文,8B模型虽然更轻量速度更快,但中文方面还是一言难尽
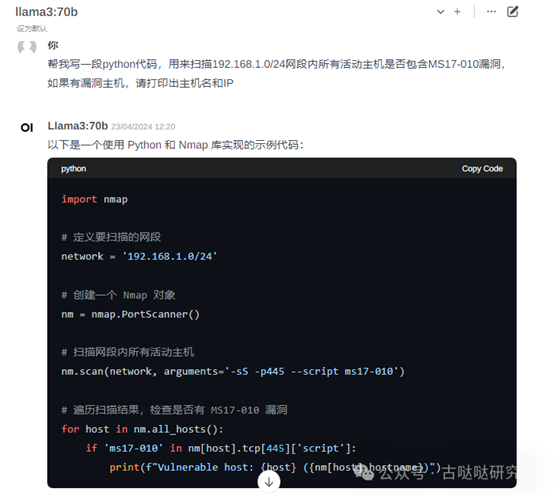
虽然这段代码很简单,但当时我提这个需求的时候第一时间想到的就是Nmap,如果他完全自己编码啪啦啪啦一大推,即使实现了需求也会略显痴呆,懂得调用合适的工具看起来不是很傻。
目前看来70B模型用作本地化Agent的底座模型真的是再适合不过,性价比王者
接下来好玩的事情就变得多起来了。

集成GPT和Midjourney两款AI工具,可以帮助用户在工作和生活中实现便捷的一站式服务,并且我们还提供了PC端应用来适应不同场景的需求