stable diffusion最全18种controlnet模型,详细教程讲解。
发布时间:2024年06月06日
目前AIgc领域正在持续关注,等到年底的时候做一个最全面的视频和文字讲解,现在还是在等等,目前AI领域热度确实是在持续降温,但是呢,深入了解AI的人都知道,AI的发展不是想人一样需要很长时间的积累,有时候可能就是一个算法的突破,就能应用到文字,图像声音等。(注意不是说AI没有积累,只是说这种发展会很激进,往往可能一夜之间,就和变天一样)。
之前有人问我,如何真人转二次元,要做的很像。
首先要转二次元得有二次元大模型,其次要反推之前真人照片的提示词,要到图生图里去做,效果好一点。
表达有点问题,重新修改一下。
尺寸要和原图一样。重绘幅度越低,越像原图,越高越不像。
就这一句话精髓。
自己要去多尝试一下。还有可以ipadaper和depth搭配使用。出的图片比原图少了某些元素,可以一次性生成多张图片。用概率去对抗不可控因素。或者用功夫可以呀练个lora.
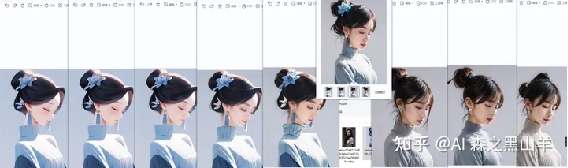
从左到右依次排序,0.1到0.9

这个是根据下面这张图转的真人风格,谁还不会过来打屁股
聊会正题
首先了解一下controlnet能干什么,就是控制,可以用调色来比喻,无论是图片调色还是视频调色都要用到很多工具,白平衡校准,色温,色相饱和度,亮度,蒙版降噪,锐化,视频的工具会多一点蒙版追踪后,人物肤色,抠像等,这个也是一样,不同的预处理器,不同的模型有不同的效果。
每一个预处理器就要搭配一个合适的模型
1,控制人物姿势 openpose,一般选用 dw openposefull,这个比较全面。openpose有6个预处理器,一个openpose ,openpose face姿态和脸部,openpose faceonly仅脸部,openpose full姿态手部 脸部,openpose hand手部。dw opposefull可以简单理解为 openpose full升级版本。
骨骼图自己会找吗,在C站找,你要自己学会从源头开始找东西,而不是别人给的。难不成一直指望别人给吗。

看得出来差别吗,这个是图生图做的,重绘幅度0.35

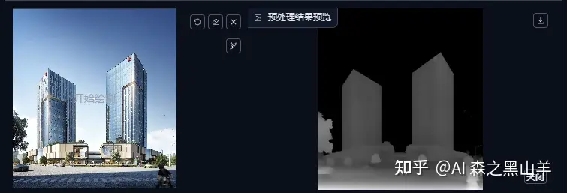
2,depth深度模型,
这个可以很简单的理解为,在二维图片看到三维空间光影关系。depthless++这个模型处理的效果是最好的,当然这个会慢一点。其他的一般,这个广泛应用于三维空间的场景,简单的来说就是人物,建筑,风景等都可以万能的。
在后续出图的时候,我们可以用三个模型,openpose+depth+title等可以自由搭配。


3.canny,细节会更多,用于识别图像的边缘特征,再去输送到新的图片。可以这么理解canny就类似于抠图,通过黑白线稿的方式再去生成类似的图,细节多了也不好,反而会很脏。


一个亮部识别,一个暗部识别。降低这两个会增加识别度
也可以做线稿上色,通过invert处理器,就canny下面那一个,反转一下黑白线条就行。
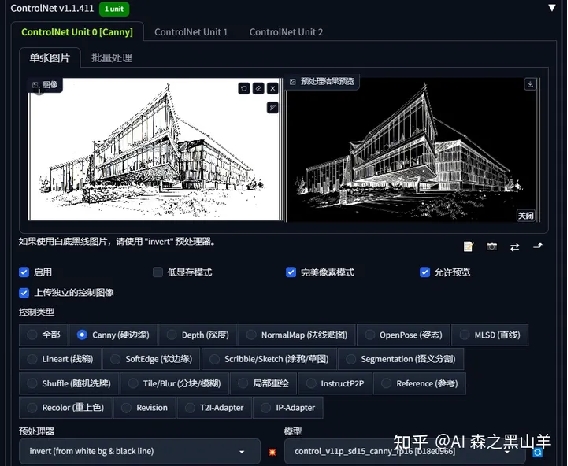
这个用了tile vae,潜空间分块高度不能超过160,

4,线稿上色linert,这个和canny差不多,但目前看效果还不错

5,这个是softedge,软边缘与canny差不多。但是没有那么多细节相对出图会自由一点,可以让AI发挥一点创造性。

像这种

6,法线贴图,就是通过rgb颜色通道表现凹凸图像,很少用
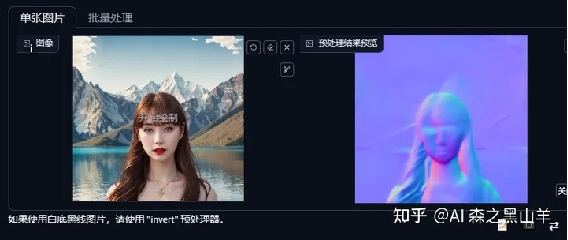




7,涂鸦工具
有两种用法,一种是prompt给普通的图像加点东西,比如科幻赛博朋克等,
第二种,就是到ps画火柴人或者其他的东西,再给提示词。下面那张图,放出来是干嘛,就是让你感觉这个东西很简单,不是很复杂,不要头痛这种东西。我这个主要没想好画啥东西,而且也不是学美术的。



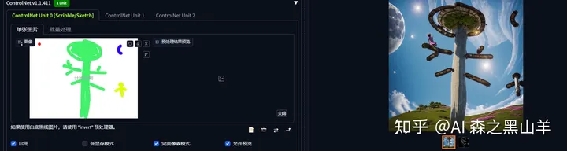

像这样极度抽象的画面,好像也能看一下
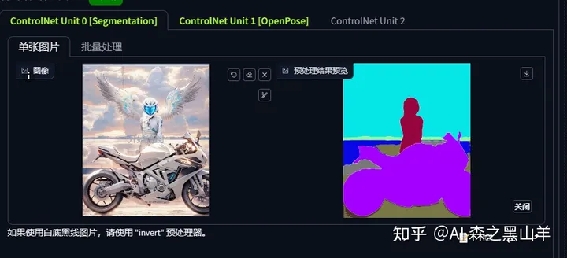
8.颜色分割,就是用颜色分割同类像,这个很强大,这个色彩也不是乱给的,有专门的色彩表,可以画多人图,和涂鸦工具也差不多。
ADE20K颜色表:https://pan.baidu.com/s/1rh40-s5pc9vVqqso9TTyig?pwd=n353 提取码: n353。这个是大江户的,在这个表里,找到相应的色彩画上去,或者加Openpose能做出非常好的效果。根据右边这张图,去画,你想要什么东西你就根据相应的色彩画,然后融进去,就有用。单纯的颜色分割加openpose没什么用的。我现在是1点40多写的文章,那个还要打开ps,有点麻烦我就没搞了。
9.shuffle, reference, t2ia,ipadaper,revison都差不多
shuffle也叫重组模型,就是将图片原有的色彩打撒,重新进行排列组合,真人写实风格不太好,可能也和分辨率有关,二次元的

权重开到2了

这个是参考图片

这个是控制1的,好像还可以
10,reference,可以控制人物一致性,可以控制人物五官和头发,服装颜色,只能抓取个大概的。强调一下,一般像这种采样器,预处理器,字越多带加号的一般是最好的,因为是在原有基础上加强的。

还可以我用的是二次元模型
11,revision,这个出图还行,融图挺好的,


这两张图也是随便出的,其实还能优化很多细节

12,t2ia有三个预处理器,这个就不放图了
t2ia_color_grid,用于图像色彩增强的算法,土要适用于增强qcse鲜艳的图像。
t2ia_sketch_pidi,针对手绘索描的算法,适用于将手绘索描转换成真实照片。
t2ia style_clipvision.风格化图像处理算法,适用于将图像转换成指定的特定风格
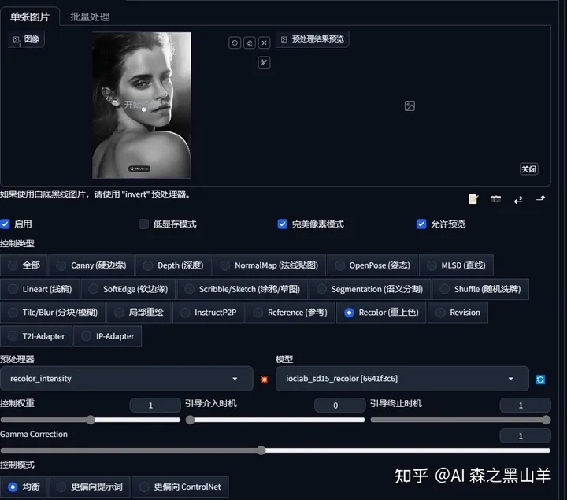
13,recolor 重上色,一般选用luminance,这个最好加个cutoff插件
一般两个作用,1,就是黑白变彩照。
2,换衣服,眼睛,服装等颜色

14,MLSD直线,一般用于建筑室内,注意这个要下载相应的模型。



15.tile插件,最好的点,在于不会那么随意的改变主体,固定人物形象。可以将模糊图变有细节,生成分辨率高的图片。一般就是 tile加tiled diffusion,tiled vae,做高清放大,显存低的也能用,我很早之前,想做个6k图片,加了三个controlnet,和其他插件要一个半小时,我电脑3060.12g显卡。这个没什么讲的。对于显存低的,还挺好用的这个插件。
16,局部重绘,有好多插件能代替,这个一般
17,instructp2p,这个东西连预处理都没有,没啥用,感觉是淘汰品,也没人升级

奇奇怪怪的
18.ipadapter,就是个迁移风格模型。

这个是原图

这个是迁移的风格
1大多数人只是使用而已,说实话压根就不需要学的太复杂,只需要最简单又能讲清楚明白大概原理的教程,
2,给你举一些你熟悉的例子,让你更理解这个工具,
3,如果要深入学习,肯定是一边练图,一边解决问题,这样你在学习的过程中是在思考的,怎么解决问题,然后这个知识就会进脑子里。复杂原理,有机会的话讲讲这方面的论文,。
如果要做的很像,肯定要多个控制模型。
总结一下,18个里面最常用的,canny,softedge,openpose,depth,涂鸦,语义分割,tile,线稿上色,ipadapter,
出自:https://zhuanlan.zhihu.com/p/662586461
通义万相,一个不断进化的人工智能艺术创作大模型,擅长将奇思妙想转化为图画。