基于Ollama本地部署谷歌开源Gemma大模型!
发布时间:2024年06月06日
在开始使用Gemma开源大语言模型(LLM)前,我们先了解下Gemma以及配套的工具。
基本介绍
Gemma 是由 Google 推出的一系列轻量级、最先进的开放模型。这些模型基于与 Gemini 模型相同的研究和技术构建,由 Google DeepMind 和 Google 内部其他团队共同开发。Gemma 的名字来源于拉丁语 "gemma",意为“珍贵的石头”,象征着其在 AI 领域的重要价值。
这次发布的Gemma不仅仅只有2B 和 7B这两种规模,实际上是发布了Gemma系列(经过预训练的变体和指令优化的变体,大大小小50多种),Gemma 模型非常适合各种文本生成任务,包括问答、总结和推理。
同时,还能在Keras3.0(以集成主要框架JAX、PyTorch和TensorFlow)上用于推理和监督微调(SFT)的工具链。以及提供了谷歌Colab和Kaggle笔记本快速部署代码和HuggingFace等第三方AI平台的集成,使用户能快速上手体验。
第三方体验地址我会放在文尾。
基础性能
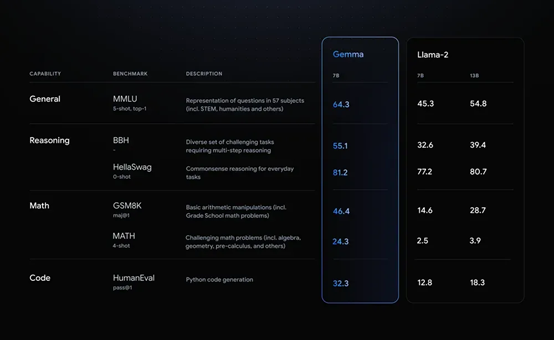
这次开源的Gemma和Gemini用的是同样的技术和基础组件,谷歌自信地认为Gemini是他们目前发布以来最强大、功能做广泛的大语言模型。Gemma7B在基准测试上明显超过了Llama-2 7B和13B,无论是科目问答,推理性能,数学能力还是代码能力都要比Llama-2强太多(这里的数据是基于关键基准上测试的)。
论文内的性能如下图:
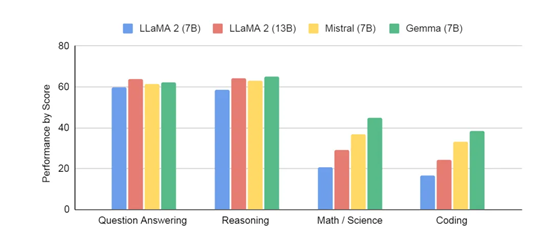
好了,以上就是Gemma的简单介绍,有兴趣的小伙伴可以看下原文:
传送门:https://blog.google/technology/developers/gemma-open-models/
快速上手
在安装前先确定C盘目录大于20G,再根据自己的电脑配置安装不同型号的Gemma,8G显卡跑2b应该问题不大,16G以上的跑7b也没问题。
这次使用Gemma,我们还是用LLM的老朋友开源的Ollama项目。我们先进入Ollama的主页(地址在文尾)。
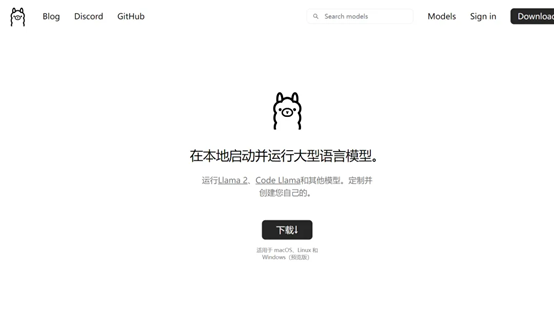
进入主页后,点击下载按钮,进入下载页。
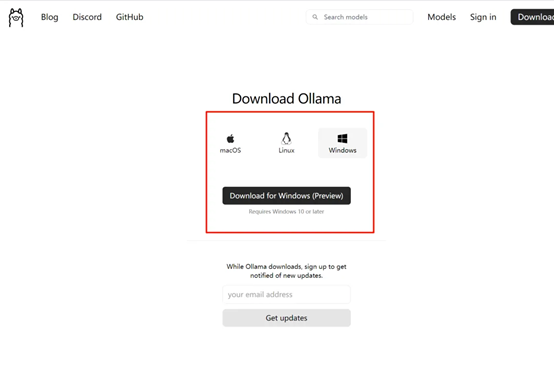
总共有macOS、Linux和Windows三个版本,根据您的系统,选择一个版本下载,这次我们以windows为例。
下载完成后就是这个可爱的羊驼图标,然后我们双击OllamaSetup.exe安装,默认情况下是装在C盘的,直接点install一键安装。
安装完成后,系统任务栏右下角位置会多出一个草泥马的头像,这代表已经完成安装了。接下来,我们打开windows自带的powershell待命(在windows搜索栏搜powershell或者在某个目录点击右键,选择 在终端打开)。
接下来,我们再回到ollama官网的模型页面,在模型列表处找到Gemma,点进去。
进去之后Overview是模型概述,不管它,直接点Tags,茫茫多的型号该怎么选呢。
以下是Gemma的版本和型号参考:
- 2b和7b:表示模型的参数数量,分别是2亿和7亿参数。
- instruct:表示模型是针对特定指令或任务进行训练的。
- text:表示模型专注于处理文本数据。
- fp16:表示模型支持半精度浮点数(16位浮点数),这有助于在保持相对较高精度的同时减少内存使用和提高计算效率。
每个型号后面的q4_0、q4_1等是模型的不同版本,是基于模型性能、训练数据集、优化策略或其他因素的不同迭代。例如,q4_0是第四个迭代的初始版本,而q4_1可能是在q4_0基础上的改进版本。
那么我们选latest这个版本,也就是最新版。
直接在powershell里输入命令ollama run gemma开始下载,下载无需魔法不过可能会花点时间。
下载完成后,在send a message行里就可以直接与gemma对话了。
tips:
1. 运行不同版本的gemma,示例:
ollamarun gemma:2bollama run gemma:7b
2. gemma默认下载在C盘;
3. 按Ctrl+D退出gemma;
4. run ollama gemma启动gemma;
5. ollama list查看模型型号列表.
Ollama项目地址:https://github.com/ollama/ollama
Ollama官网地址:https://ollama.com/
PS:还可以安装通义千问和llama3哦
Ollama run qwen
Ollama run llama3
Vercel开源的搭建AI聊天机器人的开发套件,支持React/Svelte/Vue等框架