Prompt及AI提问实践
发布时间:2024年06月06日
写在前面
在大模型技术应用越发广泛的大背景下,各行各业都在尝试落地。我们以客服场景为例,聊一聊Prompt编写的一些实践指南。
目前,国内外大模型百花齐放,比较典型的是ChatGPT、讯飞星火、MiniMAX、文心一言、百川等,各家公司也有自研模型。对于不同的模型,想要达到同样的效果,使用到的Prompt可能也会不同,这可能受限于以下几类因素:
·
模型本身的参数量级。顾名思义,模型本身的参数量越大,对Prompt的适应能力就越强。有时一个简单的Prompt在大参数模型上的表现,可能会比精心设计的Prompt在小参数模型上的表现更好。
· 模型本身的实现方式。比如某些模型对输入token处理时,会进行截取操作,导致多轮对话的部分信息失效,此时把Prompt放在不同的位置会产生差异较大的结果。
语料准备好了,我们看看一个经典的客服对话场景(用大模型生成的模拟数据):
用户:我上周在你家买了个手机,但今天发现它有点问题,我能退或者换吗?
客服:您好,非常抱歉给您带来了不便。请问您能详细描述一下手机的问题吗?这样我可以更好地了解您的情况。同时,我们需要核实一下您的个人信息,请问您的全名和联系电话是多少?
用户:我叫李明,这是我的手机号:13800138000。
客服:好的,谢谢您提供的信息。请问您的收货地址是哪里?
用户:北京市朝阳区建国路88号SOHO现代城A座。
客服:明白了,那您有没有尝试过重启手机或者重置呢?
用户:我试过重置,但没用。
客服:好的,那您还有其他问题吗?比如扬声器或者电池续航之类的。
用户:哦,对了,扬声器有时候会有噪音,而且电池续航时间也比我预期的短很多。
客服:感谢您的反馈。为了进一步核实您的订单信息,请问您的手机型号和IMEI号是多少?这些信息通常可以在手机的设置->关于本机中找到。
用户:型号是iPhone 12,IMEI号是351234567890123。
客服:谢谢您提供的信息。请问您的订单号是多少?
用户:我的订单号是16321575678435567。
客服:好的,我们已经核实了您的个人信息和订单信息。根据我们的政策,如果在购买后7天内发现产品存在严重质量问题,您可以申请退货或者换货。请问您的购买日期是什么时候?
用户:上周五。
客服:那么您还在退货期限内。请您将手机包装好,附上退货申请单,然后联系我们的物流合作伙伴进行寄回。我们会在收到您的退货后尽快为您处理退款或者更换新手机。
用户:好的,那我要付邮费吗?
客服:对于因严重质量问题导致的退货或换货,我们提供免费服务,所以运费由我们承担。请您放心寄回。
用户:好,那大概要多久才能搞定?
客服:一般情况下,退货或换货过程需要7-10个工作日。我们会尽快处理,确保您能尽快恢复正常使用。
用户:好的,谢谢。
客服:不客气,如果您在退货或换货过程中遇到任何问题,欢迎随时联系我们。祝您生活愉快!
这里引出了第一条实践原则:区分角色。在上面的例子中,我们分别使用了用户:和客服: 用于角色定义,因为这样会让大模型得到更为准确的输入。试想,如果把大模型当做人,清晰的角色区分会显著地降低理解成本。
Prompt准备
有了语料,我们让大模型来进行总结:用户咨询了什么问题,以及客服提供了什么解决方案。
下面我们设计一下Prompt:
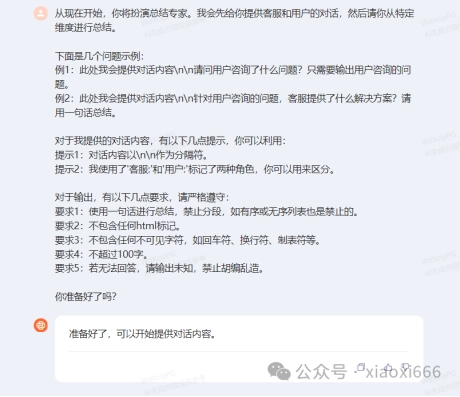
从现在开始,你将扮演总结专家。我会先给你提供客服和用户的对话,然后请你从特定维度进行总结。
下面是几个问题示例:
例1:此处我会提供对话内容\n\n请问用户咨询了什么问题?只需要输出用户咨询的问题。
例2:此处我会提供对话内容\n\n针对用户咨询的问题,客服提供了什么解决方案?请用一句话总结。
对于我提供的对话内容,有以下几点提示,你可以利用:
提示1:对话内容以\n\n作为分隔符。
提示2:我使用了'客服:'和'用户:'标记了两种角色,你可以用来区分。
对于输出,有以下几点要求,请严格遵守:
要求1:使用一句话进行总结,禁止分段,如有序或无序列表也是禁止的。
要求2:不包含任何html标记。
要求3:不包含任何不可见字符,如回车符、换行符、制表符等。
要求4:不超过100字。
要求5:若无法回答,请输出未知,禁止胡编乱造。
你准备好了吗?
我们首先将这段Prompt告诉大模型,让它做一些初始化准备,然后将语料提供给大模型,再分别进行提问:
请问用户咨询了什么问题?只需要输出用户咨询的问题。
针对用户咨询的问题,客服提供了什么解决方案?请用一句话总结。
最终的效果是这样(使用百川大模型进行演示):
<然后将对话内容发给大模型,此处略去>
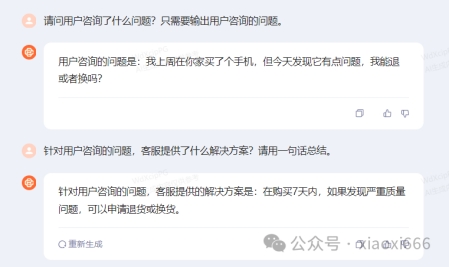
可以看到大模型已经给出了对应的总结。对于我们的例子,总结较为简洁,如果你需要更为详细的输出,也可更改提问,比如:
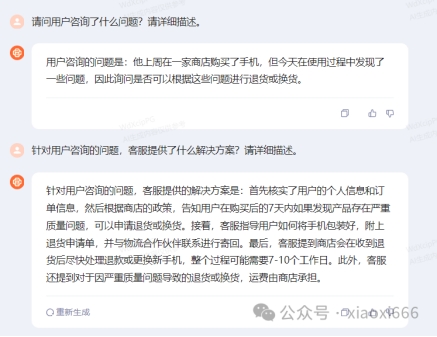
下面我们来看看上面的Prompt和提问,遵循了哪些原则。
实践指南
我们先用一张图片总结下:

分别做一些解释:
角色扮演
告诉大模型,它将要扮演的角色,帮助它了解将要执行的任务。
对于参数量较小的模型,指定角色对于输出质量的提升较为明显。对于参数量较大的模型,则对输出质量的提升较弱。这也体现出:参数量越小的模型,对Prompt的依赖度越高。
少样本提示
给一些例子,让大模型更懂你要解决的问题。
比如上面的Prompt,我们给了一些例子,帮助大模型理解将来我会如何提问。在实践中,我们也可以同时把问题和结果写出来,这样的例子会更为完整。
对于参数量更大的模型,甚至不需要提示,也即“零样本提示”,其实这是因为模型已经有了更多阅历,能够识别我们的场景了。
明确输出要求
对于大模型来说,我们可以指定任意的输出格式,比如对输出做一些限定,包括但不限于:
· 内容的长度限制
· 特定内容过滤,比如不要输出某些字符,常见如html标记、回车符、换行符、制表符等
· 指定以特定格式输出,如最常见的json格式
· 兜底输出内容,以避免幻觉,常见的要求如:“若你无法找到内容,请输出未知”
一次只问一个问题
对于参数量较小的模型,如果我们同时问多个问题,输出可能会出现缺漏。因此我们可以保持提问简单,使得目标更为聚焦。
比如:我们把用户咨询了什么问题、客服提供了什么解决方案,分成两个问题来问,而非一次性问完。
注意文本的顺序
这条规则与大模型的实现方式有关。众所周知,所有大模型均有token上限,因此某些模型在实现时会对文本做取样甚至截断,从而导致它对不同位置的文本内容敏感度存在差异。因此需要我们对文本内容的顺序做适当处理,尽可能把重要内容放到敏感度更高的地方。
选用恰当的分隔符
文本内容与提问之间的分隔符。目前实践发现,多数大模型对于换行分隔符\n\n的敏感度最佳。
必要时,描述数据特征
显而易见的例子就是上问题到的,我们告诉大模型,可以使用客服:和用户:来区分两种角色。另外,还有很多玩儿法,比如:输入内容可能是一段json,如果不想提前做数据清洗,可以告诉大模型仅识别其中的某个字段,大模型就会自动摘取。
尽可能减少文本字符数
这是一条通用原则,适用于所有大模型,目标是减少对token的消耗。
最简单的做法是对数据做脱敏。根据业务场景的不同,过滤效果可能会有较大差别。比如有些客服和用户的对话中可能包含用户名、手机号、IMEI、SN、订单号、详细地址等信息,但总结场景并不会严格依赖这些信息,此时就可以过滤掉,一般可以将文本字符数缩减20%左右。
另外还有一些方法,比如将格式化的html符号过滤掉,等等。
总结
本文以客服对话总结为例,介绍了使用大模型时的Prompt编写和提问实践,供大家参考。
当然,随着大模型技术的不断迭代,适用的原则也可能需要不断演进,这就需要我们不断去探索优化了。参考
1. 如何更好地向 ChatGPT 提问?https://www.zhihu.com/question/570765297/answer/3045672251
2. 你在用ChatGPT时有什么独特的prompt心得?https://www.zhihu.com/question/594837899
3. GPT Prompt编写的艺术:如何提高AI模型的表现力https://blog.csdn.net/Taobaojishu/article/details/132074133
4. https://github.com/GitHubDaily/ChatGPT-Prompt-Engineering-for-Developers-in-Chinese
5. 大模型Prompt工程的重要性及构建方法 https://zhuanlan.zhihu.com/p/658704771
出自:https://mp.weixin.qq.com/s/Oi059Ql_ANnmQaWZ_D5_HA
AI大作是一款基于人工智能语言分析的AI绘画平台,让文本和图片成为AI绘画艺术作品。