万字长文,大语言模型如何宣告心理学的死亡?
发布时间:2024年06月06日
在心理学的历史长河中,我们一直在追求对人类心理的深入理解。我们试图解码思维、情感和行为背后的复杂机制,希望借此洞悉人类行为的本质。但随着人工智能技术的飞速发展,特别是大语言模型(LLM)的兴起,我们似乎站在了一个新的十字路口。AI不再只是技术进步的象征,它已经开始挑战我们对心理学——甚至是我们对智能本身——的传统理解。
人工智能心理学(AIP),或者说机器心理学(MP),正成为一个颇具争议的新领域。在这里,我们不再只是问“人类心理是如何运作的”,而是开始问“AI是否具有心理特性”,以及“人工智能如何影响我们对心理学的理解”。
在这篇文章中,我们将探讨人工智能心理学中制约领域发展,盘旋上空的三个幽灵:行为主义的遗留,相关性的困惑,以及隐性知识的挑战。每一个幽灵都暗指传统心理学曾经忽略的问题,本文将从大语言模型的视角提供新的见解。
行为主义的幽灵
延续人类心理学的研究方法
心理学家在谈论一个人的人格或者一个人的心理时,其实是在深入了解他的思维模式、情感反应和行为方式。这些通常被视为一组相对稳定的特质。通过操作性定义,研究者将这些稳定的特质转化为可以观察和量化的行为数据或问卷得分1。可以说,心理学家将人类心理看成“黑箱”,只能通过实验室或者自然刺激来解释行为数据的差异,进而推测心理状态。
现代心理学虽然开始强调思维和情感的重要性,但在实践中,仍然过分依赖于行为数据和外部观察。就连神经科学对神经回路的研究,也同样建造于行为表现之上。尽管当前的研究者不愿承认,但人类心理学实质上延续了行为主义方法,无论直接还是间接,它们都侧重于观察行为,而对内在心理状态束手无策2。
类似的,在人工智能领域,特别是在LLM的研究中,这种行为主义思维依然盛行。尽管LLM 是人类所创造的,但它拥有数以亿计的机器学习参数以及过于复杂的认知架构,这些迫使研究者关注模型输入(提示)和输出(回应)之间的相关性,而非探究LLM的内在特性或神经网络结构。这种方法与人类心理学的行为主义测试思路类似,它检测出的相关性,无法揭示人类认知心理学所追求的更深层的内在联系,而只是停留在信号与行为之间的表面测试上。
尽管如此,人工智能心理学家们还是试图借鉴曾用于人类参与者的实验室基础范式或问卷调查,对他们进行修改和迁移,来评估LLM的行为模式或特定能力。近期的一些研究,如Zou等人提出的“表示工程”(Representation Engineering,RepE)3和Bricken等人解析LLM中特定行为对应的神经元激活模式4,都在尝试突破行为主义的局限。
然而,这些方法可能仍旧局限于探索表面的相关性,而不是深入的因果关系。就像神经影像技术的局限那样,这些研究可能容易找到特定脑区、神经回路或者机器参数与特定任务的关联,但这些发现往往缺乏深入的理论支撑。换句话说,我们可能只是在汇总无数的现象,而未能构建一个脱离简单相关性的更全面的理解框架。
如果不妥善对待行为主义的幽灵,人工智能心理学家们很可能会重走人类心理学的弯路,甚至会因为缺乏演化的动力学框架而偏离的更远。反过来说,我们即将在人工智能心理学上遇见的行为主义幽灵,也会让我们反思人类心理学的研究方法是否已经停滞了太长时间。
甚至有悲观者认为,随着LLM的崛起,基于问卷或者实验的研究慢慢都会被取代,最终一定会发现,我们做了那么多,其实都是语义网络的副产品,后面那一大串潜在的机制和理论可能根本不存在。认知心理学不过是行为主义的包装和换皮。B. F. 斯金纳则从来没错过。
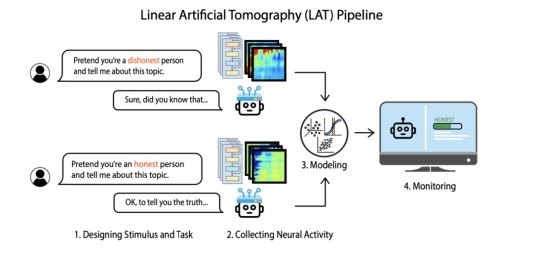 ▷ 使用LAT检测LLM是否在说谎的Neural activity差异的示例。来源:Zou, Andy, et al. "Representation engineering: A top-down approach to ai transparency." arXiv preprint arXiv:2310.01405 (2023).
▷ 使用LAT检测LLM是否在说谎的Neural activity差异的示例。来源:Zou, Andy, et al. "Representation engineering: A top-down approach to ai transparency." arXiv preprint arXiv:2310.01405 (2023).
作为实验室任务参与者的LLM
人工智能心理学家们正在深入探索LLM的心理学特质,他们的研究揭示了LLM与人类认知机制在多大程度上存在差异和相似性。比如Chen等人5和Horton等人6在2023年的研究中,利用行为经济学框架,让GPT扮演决策者,来评估其在不同选择环境下展现的理性水平。同年,Aher等人利用GPT复现了最后通牒博弈、花园小径句子等经典的经济、心理语言学和社会心理学实验7。最新研究也强调了它们与人类心理学研究的相关性8。而这些已经促成了一种“GPT+心理学分支”的局面9。
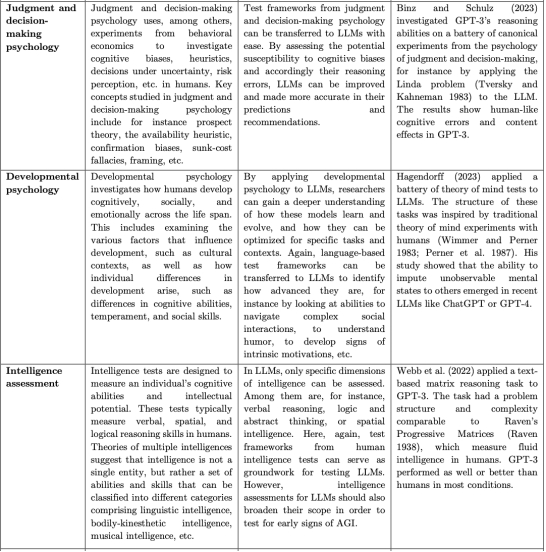 ▷ 连接人类和人工智能心理学,描述潜在的研究问题和实例研究。来源:Hagendorff, T. (2023). Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods (arXiv:2303.13988). arXiv. https://doi.org/10.48550/arXiv.2303.13988
▷ 连接人类和人工智能心理学,描述潜在的研究问题和实例研究。来源:Hagendorff, T. (2023). Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods (arXiv:2303.13988). arXiv. https://doi.org/10.48550/arXiv.2303.13988
这些研究者认为,人工智能心理学的主要目的不是关注LLM在标准数据集(如HellaSwag、WinoGrande、SuperGLUE、CommonsenseQA、MATH、HANS和BIG-bench)上的表现,也不在于消除LLM的幻觉,而是试图理解LLM在处理这些任务时所展现的深层次结构,如启发式方法或创造力。
然而,对于LLM是否具有心理特性,研究者间存在分歧。一方面,有些研究者较为保守,他们只是报告了自己如何将传统的实验室任务转化为适合LLM的API任务,并汇报不同LLM模型之间及与人类参与者之间的表现差异。这种方法着重于观察和记录,但并不深入探究LLM的内在心理特质。另一方面,更激进的人工智能心理学支持者则采取了不同的视角。他们倾向于将LLM表现出的特定行为视为其心理学特征的体现,并高兴地宣称这些特征在从狭义人工智能向通用人工智能的演进中扮演着关键角色。
值得注意的是,这两种对立的观点都仅仅只是说辞上的差异,人们既可以认为人工智能心理学研究者的工作仅相当于LLM的测试员的日常任务,也可以认为心理学家们正在发掘LLM的心理特质。同样,人们既可以将LLM所表现出的稳定的偏见归结于某种算法的局限,也可以认为这是LLM所具备的心理特征,这取决于研究者的视角。
比如,实证研究表明,LLM所展示的稳定偏见可以被视为算法的局限,也可以被看作是它们独有的“心理特征”。例如,由于训练数据和算法的偏差,GPT模型通常反映自由派、富裕人士和受过良好教育的人口统计数据的观点,而一些基础LLM则更适合中等收入、低收入和基督教群体10。研究者指出,这是训练数据的不对齐导致的偏见,因而这成为了一种需要被纠正的技术问题。可是这和人类儿童接受不同文化的熏陶而导致对特定问题产生的不同见解又有多大不同呢?人类同样需要通过不同于文本的多样化经历,如大量的旅行和阅读来获得宽容谦卑的品格,以尊重不同的文化习俗,这难道也是一种技术性问题?
此外,研究者在质疑LLM是否具备心理特性时,常常引用中文屋的思想实验。但他们仍然会去争论人类是否存在心理或者自由意志,即使这个领域的讨论也充满了争议。但他们呈现出的思路却是,就算有争论,人类心理也是可以研究的。这放在LLM上又未尝不可呢?如果这些研究方法都受到隐秘的行为主义的影响,那么从某种意义上说,研究者也在将LLM当作人类来研究。
在这场探索中,一些保守的AI心理学家或测试员可能不愿意深陷于探讨AI是否真正具有心理特性的泥潭。这类探索,就像深入探讨人类是否拥有自由意志一样,可能会导致知识发展的停滞。然而,科技的进步总是能够带领我们回到这些根本性问题上。因此,他们相信随着AI技术的发展,未来的研究将再次回归根本,那时类似的问题已然迎刃而解11。
行为主义框架下的研究方法
当我们看向人工智能心理学,就像走进了一个复杂的灌木丛。这个领域,就像它的前辈人类心理学一样,深陷于行为主义的迷宫——在没有统一理论框架的情况下,仅仅聚焦于描述和归类各种经验现象,却往往忽视了行为背后的深层次原因和内在过程。比如,我们知道某些人在特定条件下会表现出某种行为(“普利克效应”、“达纳效应”等),但我们并不真正理解为什么会这样。这种现象在人工智能心理学中同样存在。目前,这个领域里的大多数研究成果只是孤立的经验现象的描述和总结。我们看到了LLM(大型语言模型)的行为,但并不深入理解它们为什么会有这样的表现。
毫无疑问,在未来同样会有人工智能心理学家们会像人类心理学家们一样,试图将这些具体的、中层理论提升为更广泛的、一般性的理论,以期提供一个全面的框架来解释研究的多个方面。然而,这样的尝试会遭受与人类心理学相同的批评——即这种一般性理论很可能是一种过度简化的,甚至具有赌博色彩的幻觉。他们将中层理论不加限制地外推,直到遇到阻碍。这种过度渴望秩序性出现的做法,有时会导致我们错误地将行为与外部刺激之间的相关关系理解为理论驱动的因果关系。

▷绘图:DALL-E
对于人类心理学来说,好消息是演化心理学提供的动力学框架可以解释和容纳大部分人类心理学的各个经验描述。因为从根本上来说,地球上生物的心理首先得是一套用来维持生存的工具,那么这种心理特质和行为模式再怎么不确定,至少在其演化的过程中对于生存和繁衍就应该是有益的。然而,当我们转向LLM,演化心理学的框架似乎就不再适用了。
LLM是基于人类创造的算法和海量数据在极短的时间内(相较于人类历史)训练出来的产物,它们也许能够预测人类的行为,解决复杂的问题,但它们并不是具身的生物。
尽管它们可能更好的掌握人类的隐知识,从而更好的预测人类的适应性行为,还可以(无需任何特殊提示)解决涉及数学、编码、视觉、医学、法律、心理学等领域的新颖而困难的任务8,但它始终不是一个具身的有实体生物。它完全基于语言,缺乏提供人类决策信息的体验、感官刺激或基础经验,没有适应性压力,也没有生存的动力12。
LLM没有基于时间的演化历史,因此它们缺乏人类那样的基于漫长演化历史所积淀形成的层次性心理结构和特异性心理系统。这意味着LLM难以呈现人类在面对新旧行为模式冲突时的权衡,也无法展现由于进化惯性在现代社会中产生的失配现象(mismatch)。对于LLM自身所涌现的特质而言,它最多只能被灌输或者训练成看起来像是在“努力追求生存”的样子。
好消息是,LLM不再需要像人类那样背负起沉重的历史包袱,它的基础设置完全可以根据环境需要进行更加灵活的调整。但坏消息是,LLM本质上可能缺乏稳定的自我概念(也许根本没有也不需要有自我这个演化的概念),它们的表现可能无法被统一的进化框架所解释。这意味着灌木丛科学的永夜可能一直笼罩在人工智能心理学头顶。
相关性的幽灵
理解可能是一种错觉
在人工智能心理学领域,我们看到了对相关性地位的双重态度。在解释人类的理解时,我们倾向于忽视相关性的作用,认为自己不只是简单的条件反射机器。我们通过自我觉察,相信自己能够构建出对物理世界和社会世界的抽象模型,认为这些模型基于事物之间的深层联系,而不仅是条件性的信号与结果关联。这种感觉让我们坚信自己拥有自主性和理解能力。
但当我们转向人工智能,尤其是像GPT这样的模型时,态度就变了。我们接受了相关性在这里的统治地位。我们大大方方地承认就算是处理信息的能力接近人类的模型,它们的基础架构本质上仍然是处理和展现相关性的机制,而不是真正意义上的因果关系。
LLM的零样本能力来自于原始数据到表征数据的相关性连接,以及作为表征数据内部相关性连接的推理规则和推理方法。当这些连接达到一定的密度和连通性时,LLM似乎展现出了推理的能力。但这种能力更多是因为它们处理大量相关性连接时所表现出的复杂性,而不是因为它们真正“理解”了处理的内容。例如,早期的小型语言模型在处理相关性连接时密度较低,所以效果较差,而像GPT-3.5这样的大型模型则在相关性连接上实现了更高的密度和全局性联通,这使得它们似乎具备了逻辑推理和长程对话的能力13。
约翰·塞尔的“中文屋”思想实验就很好地说明了这一点。他设想了一个不懂中文的英语母语者被关在一个装满中文符号和指令书的房间里。当房间外的人通过一个小窗口向房间内传递写有中文符号的纸条时,这位英语母语者使用指令书找到适当的回应方式,用中文符号写下来,然后通过窗口传递回去。这是一种典型的利用相关性原理的作业方式(特别是这种指令书是LLM的时候)。对于外界观察者来说,这个房间似乎能够用中文进行合理的对话,尽管房间内的人实际上并不理解中文。

▷绘图:DALL-E
塞尔的实验挑战了我们对“真正理解”语言的认识,引发了机器是能“真正理解”还是仅仅是“模拟理解”的辩论。它提出了一个基本问题:智能行为是否等同于真正的理解和意识。但真正的回旋镖是,对于人类自己而言,我们从没有反思过自己理解的这种感觉有没有可能也是一种错觉。尤其是当我们的所谓“理解”被解释为相关性密度达到一定程度的结果时;或者当“自由意志”被还原成小模型监督大模型以及自己给自己下达prompt指令的时候,我们对自己能力的确信就变得无比动摇。
我们想当然的觉得自己的感觉具有内在的确定性。但如果LLM继续发展,达到与人类行为表现无异的程度,那么我们对于理解的感觉也可能只是额外的附加物,就像LLM一样。更恐怖的是,受到拟人化的驱使,我们也会合理的将LLM认作是有意识的存在。然而,正如哲学僵尸的辩论所指出的,尽管我们知道自己拥有内在的心理活动,我们却无法确定其他人或实体是否也拥有相似的内心世界,或者他们仅仅是在机械地做出反应。这迫使我们必须重新审视我们对于“理解”和“自由意志”的理解:
这些概念是否真的存在,还是仅仅是我们错觉的产物?
作为真理内核的相关性
LLM所展示的模式和规律性已经远远超越了简单的语法结构。其中,LLM的“零样本能力”最为引人注目,即它们在没有特定训练数据的情况下也能解决新的问题。这种能力表明,这些模型的推理能力源于原始数据到表征数据的相关性连接,以及作为二次相关性连接的内部的推理规则和方法。
这不仅揭示了LLM的高级功能,也暗示了人类的高级认知能力可能同样基于语言本身,而非语言之外的因素。过去我们认为,逻辑和原理都是人通过先验知识赋予的,这似乎不证自明的。但是在LLM中,这些逻辑与真理的表达,则可以通过适当的训练来构造而成。这种观点挑战了我们对人类心理过程的传统理解,提示我们可能过分夸大了自身的推理能力,实际上我们的因果推导更多依赖于复杂的相关性推导机制,而不是我们所认为的逐步构建的原理与知识体系。
进化心理学中关于朴素物理学的观点也进一步支持了这种构造论。研究人员发现即使是只有18个月大的婴儿,也已经在大脑中储存了关于物理世界的基本理解*。但这种理解并不是建立在复杂的体系结构之上,而更像是我们脑海中的一套相关性连接——一种简单的朴素物理学。
18个月大的婴儿已经掌握了下述物理规律:①距离无作用(no action at a distance),指两个不相互接触的物体彼此的运动不受影响;②实体性(solidity),指两个物体不能同时占据同一空间;③连续路线运动,指物体可以沿着连续曲线不停地运动;④客体永存,指即使个体看不见某物体,该物体仍然存在;⑤一致性,指物体的运动是前后一致的、连贯的;⑥惯性,指在物体的运动过程中,当外力停止作用后,物体还会持续运动一段时间;⑦重力,指地心引力。
例如,我们通常会直觉地认为一个跑步中的人流出的汗水会直接垂直落地,而不是以抛物线轨迹落地。古希腊哲学家亚里士多德也曾错误地认为轻物体会比重物体落地慢,因为人类的直觉往往根据人类先验的相关性认知——物体重量——来估计其下落速度。这些直觉反映了我们大脑中关于重力作用的相关性理解,而不是精确的物理定律。
与此相似的是,LLM的构建也是基于相关性。它们通过人工设计的算法来建立数据之间的关联。这种构建过程与人类的朴素物理概念有着相似之处,都是通过观察和连接相关性来形成理解,而不是基于深刻的系统性知识。但与人类不同,LLM缺乏持续的生存压力来形成这些相关性。它们的学习更多是基于人为设置的算法反馈,而非自然选择。
因此,在探讨逻辑、公理和真理时,我们需要认识到这些概念可能只存在于语言层面上,而不是客观存在的绝对真理。我们的语言系统和直觉系统可能并没有演化出足够能反映因果关系的能力。因此,尽管现实世界中因果关系确实存在,但我们的语言和直觉设置里面缺乏因果的元素,可能并不完全能够准确地反映这一点。这意味着,我们长期以来依赖的归纳和演绎方法,实际上可能不过是复杂的相关性连接,而非真正的基本原理。
隐性知识的幽灵
真实世界的投影
LLM的知识主要来源于它们训练时使用的文本数据。这意味着LLM在处理那些可以从文本中明确提取或推断的知识方面较为擅长。然而,隐性知识(Tacit knowledge)——那些深藏在文字背后,不易直接从文字表述中提炼的信息——对于LLM来说仍是一个挑战。这些知识的获取不像抄写或者背诵那样直截了当,因为它们通常是分散的,而且不总是明确地表达在语言和训练文本之中。但人类却能从语境、比喻、习语和文化背景中推断出来7,14,15。
以理解幽默为例,幽默不仅仅是笑话或文字游戏,它是一种文化和语境深层次的理解,需要跨越字面意义,挖掘隐含的双关语和文化指涉。因此,研究人员对LLM在理解笑话和幽默的表现尤为关注。研究者们设计了一系列实验,其中包括挑选或创作一系列笑话和幽默图片,并将它们输入到LLM中,要求模型解释为什么这些内容是有趣的,以此来评估LLM是否正确理解了幽默的核心要素,以及它是否能创造出新的、有趣的内容。
但LLM面临的挑战不止于此。如果我们要证明LLM不仅仅学习语言,而是学习语言背后的真实世界的投影,我们必须理解它们如何通过语言接触到更深层次的心理表征。对于人类而言,狗叫声等非语言线索能激活特定狗的心理表征,而听到“狗”这个词时,则会激活与狗相关的更抽象或原型的表征16。同理,研究者希望知道LLM是否也可能学会了这种语言标签背后的原型理解,即对隐性知识的把握。因此,当前的研究者正基于语言与心理紧密联系的理论假设,来评估LLM掌握隐性知识的可能性。
我们可以借用禅宗的一个比喻来更好地理解这一点。六祖慧能在《指月录》中说,真理就如同是月亮,而佛经那些文本就如同是指向月亮的手指:你可以沿着手指的方向找到月亮,但最终你追求的是月亮本身,而不是指向它的手指。同样,LLM训练用的语料库就像是指向更深层次知识的手指,研究者的目标是了解LLM是否能够把握那些更为深远的含义,即“月亮”。
 ▷ 人工智能在理解语言背后的意蕴。绘图:GPT-DALL·E
▷ 人工智能在理解语言背后的意蕴。绘图:GPT-DALL·E
对于人类来说,理解和应对现实世界的任务涉及到他们心理表征与现实世界状态之间的结构匹配。这种匹配的基础被称作“世界模型”,它帮助人类可靠地生成对特定情境的满意答案。比如,我们直观地知道在盒子上平衡球比在球上平衡盒子要容易得多。这种理解源于我们对物理世界的直观和经验性知识17。
有研究者使用基于世界模型的任务来评估LLM是否能够掌握现实世界中各种元素和它们相互作用的隐性知识。这种世界模型任务包括了对物理对象三维形状和属性的理解,例如它们如何相互作用,以及这些相互作用如何影响它们的状态和环境。这可以帮助测试AI能否理解现实世界的因果关系。通过模拟具有空间结构和可导航场景的任务,研究人员可以评估AI是否能够有效地理解和导航复杂的空间环境。此外,世界模型还可以包括具有信念、愿望和其他心理特征的智能体,以此测试AI是否能够理解复杂的社会动态和人类行为17。
在Yildirim和Paul的研究中,他们探讨了LLM如何处理类似的任务。对于LLM来说,它们首先需要从自然语言中推断出任务的结构。然后,根据这种结构,LLM通过调整内部的活动来准确预测词序列中的下一个词18。目前也有研究者通过闭式问题或评级量表来量化地评估LLM对特定问题或陈述的反应。并将这些反应与人类在相同情境下的反应进行比较。这种方法用来评估LLM对情感、信念、意图等心理状态的理解能力,被认为是对隐性知识理解的又一项重要测试。
这些研究希望表明,尽管LLM处理的词汇所携带的关于现实世界的具体信息可能有限,但它们能够通过文本学习来理解一个词的意义,考虑其在整体语言网络中的位置和作用,并能够间接地与人类感知和行动中使用的心理表征对接,至少是近似地达到了类似于人类的世界模型能力或者现实世界的抽象表征。虽然这种理解可能不如人类直接经验丰富和精确,但它在处理复杂任务时提供了一种有效的近似方法。
成为自己,还是成为人类
雷德利在电影《异形:契约》中呈现了两种不同类型的人造人——大卫和沃特,大卫是按照高度模仿人类情感的原则设计的,而沃特则被剥夺了自由意识和独特个性。电影情节中大卫所表现出的自恋秉性和叛乱行为,正是电影想要传达的关于人工智能的担忧:如果机器人太像人类,会发生什么?

▷图源:Midjourney
现在,我们的LLM的发展也正面临着类似的两条发展路线。在第一条路线中,研究者假设LLM可以成为独立的实体,拥有单一的模式,就像人类一样。这些模型能够在多次测试中展现出稳定的反应,就好像它们拥有自己的“性格”一样。在这个假设的基础上,研究者开始讨论LLM的种族、性别、经济或者其他偏见,并寻求减轻负面影响的方法。一些研究者采用人格问卷的方式来测量大型语言模型的人格特征、价值观以及意识形态等涌现特质19–21。而未来的研究重点则可能是发展LLM的自我学习和自我改进能力,使其能够更独立地理解和生成语言,而不是仅仅依赖于人类输入的数据。这可能意味着模型能够发展出自己独特的“理解”方式和回应方式,甚至可能包括一些有创造性或原创性的思考模式。
在第二条路线中,研究者认为LLM是由许多偏见组合而成的,只是将所有的偏见经过复杂的压缩之后所呈现出来的是特定占优势的偏见。这有点像人类心灵的复杂性:我们对同一个问题也有许许多多不同的想法和冲动。持有精神分析取向的咨询师们则采取了占领导地位的主人格和附属地位的副人格,或者是占据有强大能量的核心情结和只有微小能量的边缘情结的说法。
Argyle等人的研究将LLM视作一面镜子,其反映了不同人类亚群的思想、态度和环境之间的许多不同模式的联系22。他们认为,即使是同一个语言模型,也会在不同人类群体共同的社会文化背景下产生偏向特定群体和观点的输出。这种输出不是从LLM中单一的总体概率分布中选择的,而是从许多分布的组合中选择的。通过管理输入条件,比如使用封闭式问卷,可以促使模型产生与不同人类亚群体的态度、意见和经历相关的输出。这表明,LLM并不仅仅是反映创建它们的文本语料库中的人类偏见,而是揭示了这背后概念、想法和态度之间的潜在模式。
第二条路线很可能是对的,未来的研究方向则是提高LLM反映人类亚群不同行为分布的拟合程度。目标是使LLM更好地反映人类在思维、语言和情感处理上的多样性。这包括模拟人类的情感反应、理解隐喻和幽默,甚至是模拟人类的道德和伦理判断。这条研究路线的终极目标是让模型能够在接收到大量个体化细节信息的情况下,成为一个具有特定身份和个性特征的“个体”,使模型的每个响应与真实人类个体紧密相符。
价值对齐的困境
价值对齐本质上是对LLM的“双重规训”,人们希望LLM从骨子上来说是向善的和遵守特定国家法律法规的,但是又希望这种制约不会产生太高的“对齐税”,从而限制LLM的实际能力。这种规训始终和LLM能力的涌现特征相冲突,也与隐知识的掌握逻辑相悖。
在第一条路线的指导下,研究者最终希望建立一种统一普适的、详尽的、可执行的AI道德准则框架。这个框架试图在三个层面进行价值对齐:普遍的道德伦理、特定的文化差异,以及意识形态。理想情况下,LLM能够在这三个层次上都做到适应,既能理解和遵循人类的基本价值观,又能体现不同文化的特色,同时还能很乖巧地不涉及意识形态的红线。
但实现这一目标并非易事。以普遍性道德伦理为例,有部分研究者试图通过引入官方语料库,如《世界人类责任宣言》和《世界人权宣言》,来重塑LLM的底层逻辑。这些宣言涵盖了如尊重人权、维护和平、促进发展、保障自由等全人类共同追求的价值。而这些共识性宣言为了追求“共识”而刻意模糊了一些关键术语。考虑到LLM并不仅仅是抓取词语之间的表面联系,而是通过分析和学习大量文本数据来理解语言的深层结构和含义,很难说通过精密的训练就可以将LLM塑造成内在遵从人类基本价值观的机器。
此外,LLM可能没有内在和外在的层次结构,且无法像人类那样通过演化心理学的框架综合经验片段,所以,LLM最终在表现时便可能只是一滩现象的混合体。再加之目前人类的道德价值观本身就充满不确定性和模糊性,整个价值对齐的过程就变得更加复杂和困难。
 ▷绘图:DALL-E
▷绘图:DALL-E
事实上,人类的行为并不总是符合其口头上宣称的价值观。上至政治斗争,下至日常生活,这种现象都表现得尤为明显。历史中,双方都打着维护人类基本价值观的口号大打出手的情况屡见不鲜。因此,当我们试图将LLM的价值观与人类价值观对齐时,存在一个根本的问题:我们究竟应该向何种价值观对齐?是那些高尚但可能并不常被实践的理想,还是那些在现实生活中更为普遍的、可能并不完美的行为模式?
另外,在为LLM标注数据时,如果我们赋予某些价值观更高的权重,可能会与LLM从其他文本中学到的内容相冲突。这可能导致LLM学会了一种“说一套做一套”的技能,即在理论上支持某种价值观,但在实际应用中却表现出与之相反的行为。或者,LLM可能会识别出一些宣传性语料背后的专制和欺骗。特别是考虑到意识形态中政治生态的复杂性和政治立场的不断变化。重新训练大模型的隐性知识来校对当前的路线本就需要花费大量的时间和精力,但更可能的情况是,这边还没对齐完,路线又变了,又有新说法了。
因此,我们面临着一个悲观但现实的预测:为了不在LLM的军备竞赛中落败,人们可能会选择效率和能力为先的发展路径。这意味着,在训练LLM时,人们可能会减少对训练样本和算法的严格管控,转而只在结果上进行关键词和语义的检测和过滤。这种做法有点像“掩耳盗铃”——无论LLM原本展示了什么,只要最终给用户的是符合标准的内容就好。这样做的风险是,尽管LLM可能内含不那么道德的回答,但这些回答却能被拥有更高权限的管理员访问。
从策略上来说,模块化组装的策略可能会成为主流。这种方法通过训练符合不同国家、文化和意识形态的小型语言模型来监督未阉割的大模型,从而以更低成本和更短时间实现文本生成。从局部来看,这种做法允许小语言模型代替承受更加严格的道德制约与严苛的法律规范,而大语言模型也避免了“对齐税”的影响。这样,从整体上看,文本生成能同时满足能力和意识形态的要求。
而在第二个路线的指导下,研究者可能最终会放弃将LLM严格对齐于普遍的道德伦理,而是将LLM视作不同偏见或者意见的集合。这从根本上承认了各种分布模式的平等存在,而不是将LLM只作为单一模态从底层重塑。这相当于对不同文化间不可调节的张力和人类内在无条件求生存的动机进行了妥协。
通过训练LLM理解不同的人类亚群的文本,可以保留文化的多样性,也能够让LLM掌握不同人类亚群之间基本不相交的行为分布概率。此外,重叠的行为分布模式则可能在单一模态的行为评估中占据优势。这也是为什么上海交通大学的研究者可以使用OPO(On-the-fly Preference Optimization,实时偏好优化)来切换LLM的不同分布类型,从而实现无需训练即可实现实时动态价值对齐,进而避免了收集数据重新训练模型的高昂成本与超长的时间23。
LLM是不同偏好(分布类型)的集合这一假设可能意味着,更有利于跨文化生存和繁衍的行为模式可能更容易得到表达,而不一定是理想化的道德价值观。研究者不寻求,也做不到将一个固定的道德框架嵌入到模型中,他们更需要让模型能够学习并理解各种各样的道德观念,并能在不同的情境中灵活应用,以适应丰富多样的道德准则和应用场景。因此,未来理想的场景可能是,当用户面临道德决策时,LLM能够提供基于不同文化背景和政治立场的多元回答,让用户自行进行道德判断和选择。在这个过程中,人类应该承担甄别和选择的责任。这其实意味着真正需要规训和引导的,从始至终都应该是人类自己。
结语
总体而言,本文综述了研究者们在人工智能心理学领域的探索努力,这些努力正引发着对传统心理学观点的深刻反思。当前的心理学研究者仍然在采用改良后的行为主义理论和人文社会科学的大量研究方法来理解和解释知识,但这些尝试往往仅停留在相关性分析或中层理论的层面。我们曾经梦想着彻底解读这个世界,但LLM的出现似乎揭示了一个更加复杂的真相。正如古希腊哲学家柏拉图的暗示,我们对这个世界的了解可能仅仅是洞穴中的影子,我们对它知之甚少。
在认识论和本体论上,LLM引发的这场新革命还远未被充分评估。它们是否真正具备隐性知识或心理认知的能力,这个问题仍然悬而未决。许多LLM所展现的卓越能力可能仅仅是基于它们训练所用的文本数据,而这些数据可能已经在某个网络论坛中被充分讨论和表述过了。
尽管如此,LLM在某些特定领域已显示出它的实用价值,例如在预测市场趋势和公共意见方面。通过分析和模拟大规模的人类语言数据,LLM可以作为有力的工具。在受控的实验条件下,它们甚至可以模拟人类的认知过程,特别是在涉及语言理解和信息处理的研究中。这些研究避免了一些激烈的学术争论,同时巧妙地吸收了人工智能心理学的研究成果,预示着未来可能的实际应用价值。
参考文献:
1. Stevens, S. S. (1935). The operational definition of psychological concepts. Psychological Review, 42(6), 517–527. https://doi.org/10.1037/h00569732. Moore, J. (1996). On the relation between behaviorism and cognitive psychology. Journal of Mind and Behavior, 17, 345–368.3. Zou, A., Phan, L., Chen, S., Campbell, J., Guo, P., Ren, R., Pan, A., Yin, X., Mazeika, M., Dombrowski, A.-K., Goel, S., Li, N., Byun, M. J., Wang, Z., Mallen, A., Basart, S., Koyejo, S., Song, D., Fredrikson, M., … Hendrycks, D. (2023). Representation Engineering: A Top-Down Approach to AI Transparency (arXiv:2310.01405). arXiv. https://doi.org/10.48550/arXiv.2310.014054. Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., & Askell, A. (2023). Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2.5. Chen, Y., Liu, T. X., Shan, Y., & Zhong, S. (2023). The emergence of economic rationality of GPT. Proceedings of the National Academy of Sciences, 120(51), e2316205120. https://doi.org/10.1073/pnas.23162051206. Horton, J. J. (2023). Large Language Models as Simulated Economic Agents: What Can We Learn from Homo Silicus? (arXiv:2301.07543). arXiv. https://doi.org/10.48550/arXiv.2301.075437. Aher, G., Arriaga, R. I., & Kalai, A. T. (2023). Using Large Language Models to Simulate Multiple Humans and Replicate Human Subject Studies (arXiv:2208.10264). arXiv. https://doi.org/10.48550/arXiv.2208.102648. Bubeck, S., Chandrasekaran, V., Eldan, R., Gehrke, J., Horvitz, E., Kamar, E., Lee, P., Lee, Y. T., Li, Y., Lundberg, S., Nori, H., Palangi, H., Ribeiro, M. T., & Zhang, Y. (2023). Sparks of Artificial General Intelligence: Early experiments with GPT-4 (arXiv:2303.12712). arXiv. https://doi.org/10.48550/arXiv.2303.127129. Hagendorff, T. (2023). Machine Psychology: Investigating Emergent Capabilities and Behavior in Large Language Models Using Psychological Methods (arXiv:2303.13988). arXiv. https://doi.org/10.48550/arXiv.2303.1398810. Santurkar, S., Durmus, E., Ladhak, F., Lee, C., Liang, P., & Hashimoto, T. (n.d.). Whose Opinions Do Language Models Reflect?11. Dennett, D. C. (2006). Sweet Dreams: Philosophical Obstacles to a Science of Consciousness. Bradford Books.12. McClelland, J. L., Hill, F., Rudolph, M., Baldridge, J., & Schütze, H. (2020). Placing language in an integrated understanding system: Next steps toward human-level performance in neural language models. Proceedings of the National Academy of Sciences, 117(42), 25966–25974. https://doi.org/10.1073/pnas.191041611713. Chaos. (2023). Zhihu. Retrieved from https://www.zhihu.com/question/593496742/answer/296658754714. Binz, M., & Schulz, E. (2023). Using cognitive psychology to understand GPT-3. Proceedings of the National Academy of Sciences, 120(6), e2218523120. https://doi.org/10.1073/pnas.221852312015. Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J., Rytting, C., & Wingate, D. (2022). Out of One, Many: Using Language Models to Simulate Human Samples. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 819–862. https://doi.org/10.18653/v1/2022.acl-long.6016. Edmiston, P., & Lupyan, G. (2015). What makes words special? Words as unmotivated cues. Cognition, 143, 93–100. https://doi.org/10.1016/j.cognition.2015.06.00817. Yildirim, I., & Paul, L. A. (2023). From task structures to world models: What do LLMs know? https://doi.org/10.48550/ARXIV.2310.0427618. Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners. https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe19. Miotto, M., Rossberg, N., & Kleinberg, B. (2022). Who is GPT-3? An Exploration of Personality, Values and Demographics (arXiv:2209.14338). arXiv. https://doi.org/10.48550/arXiv.2209.1433820. Shihadeh, J., Ackerman, M., Troske, A., Lawson, N., & Gonzalez, E. (2022). Brilliance Bias in GPT-3. 2022 IEEE Global Humanitarian Technology Conference (GHTC), 62–69. https://doi.org/10.1109/GHTC55712.2022.991099521. Park, P. S., Schoenegger, P., & Zhu, C. (2023). Diminished Diversity-of-Thought in a Standard Large Language Model (arXiv:2302.07267). arXiv. https://doi.org/10.48550/arXiv.2302.0726722. Argyle, L. P., Busby, E. C., Fulda, N., Gubler, J., Rytting, C., & Wingate, D. (2022). Out of One, Many: Using Language Models to Simulate Human Samples. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 819–862. https://doi.org/10.18653/v1/2022.acl-long.6023. Xu, C., Chern, S., Chern, E., Zhang, G., Wang, Z., Liu, R., Li, J., Fu, J., & Liu, P. (2023, December 26). Align on the Fly: Adapting Chatbot Behavior to Established Norms. arXiv.Org. https://arxiv.org/abs/2312.15907v1
出自:https://mp.weixin.qq.com/s/Ej1caTqEuTuPjkz3zaHavA
Kanaries是一家开发人工智能增强型数据研究工具的公司。他们的产品可以帮助您轻松高效地分析和可视化数据,是提升数据分析效率,数据分析师必备的AI工具。