十大开源语音识别项目
发布时间:2024年06月06日
Automatic Speech Recognition(ASR)是一项自动语音识别技术,其目标是通过计算机自动将人类口头语音转录为文本。这项技术在多个领域有着广泛的应用,包括但不限于语音助手、语音搜索、自动转写以及语音命令识别。
本文将为您介绍十个相关的开源项目(以github上星标数排名),其中大多数都支持中文。这些项目不仅在语音技术领域具有重要意义,而且为语音识别应用的发展提供了有力的支持。
Whisper
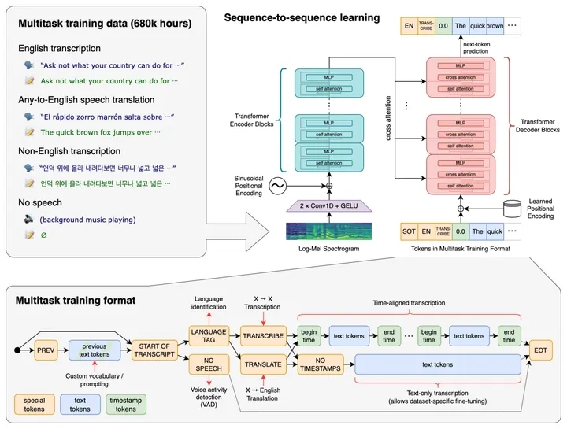
Whisper 是一个通用的语音识别模型。它在大量多样化的音频数据集上进行训练,作为一个多任务模型,可以执行多语言语音识别、语音翻译和口语识别。
支持语言:中文、法语、德语、意大利语、日语、韩语、西班牙语等等。
· 项目地址:https://github.com/openai/whisper
· 论文地址:https://arxiv.org/abs/2212.04356
· 中文介绍:https://zhuanlan.zhihu.com/p/634462613
star:48.6k
Massively Multilingual Speech
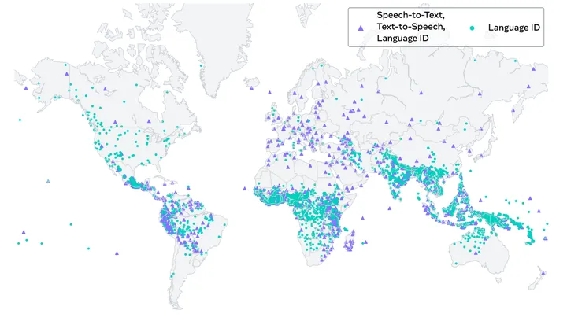
Massively Multilingual Speech(MMS,大规模多语种语音)是 Meta 开源的一款全新的 AI 语言模型,可以识别 4000 多种口头语言并生成 1100 多种语音(文本到语音),可谓是“语音巴别塔”。
支持语言:1000+。
· 论文地址:https://research.facebook.com/publications/scaling-speech-technology-to-1000-languages/
· 项目链接:https://github.com/facebookresearch/fairseq/blob/main/examples/mms/README.md
· 参考信息:https://ai.meta.com/blog/multilingual-model-speech-recognition/
star:28k
DeepSpeech
DeepSpeech 是一个开源的嵌入式(离线、设备上)语音到文本引擎,可以在从 Raspberry Pi 4 到高性能 GPU 服务器等各种设备上实时运行。
支持语言:中文。
· 项目地址:https://github.com/mozilla/DeepSpeech
· 使用文档:https://deepspeech.readthedocs.io/en/r0.9/
· 中文介绍:https://linux.cn/article-14233-1.html
star:23.3k
PaddleSpeech
PaddleSpeech 是一个开源、易用、多合一的语音处理工具包,包含语音识别、语音翻译(英-中)、文本-语音、标点恢复功能。
PaddleSpeech 荣获 NAACL2022 最佳演示奖。
支持语言:中文、英文。
· 项目地址:https://github.com/PaddlePaddle/PaddleSpeech
star:9k

ESPnet
ESPnet 是一个端到端的语音处理工具包,功能包含文本转语音、语音翻译、语音增强、说话者二值化、口语理解等等。
支持语言:中文。
· 项目地址:https://github.com/espnet/espnet
star:7.3k

ASRT
ASRT 是一个基于深度学习的中文语音识别系统,在训练中使用了大量中文语音数据,将声音转录为中文拼音,并通过语言模型,将拼音序列转换为中文文本。
· 项目地址:https://github.com/nl8590687/ASRT_SpeechRecognition
star:7.1k

广告
现在注册领取168元算力金,赶快参与吧!
SpeechBrain
SpeechBrain 是一个基于 PyTorch 的开源、全能的对话人工智能工具包,可用于开发最先进的语音技术,包括语音识别系统,说话人识别、鉴定和记录,语音增强,语音分离,语言识别,语言翻译等。
支持语言:中文。
· 项目地址:https://github.com/speechbrain/speechbrain
· 中文介绍:https://blog.csdn.net/lzx159951/article/details/118304731
star:6.8k

WeNet
WeNet 是一款面向工业落地应用的端到端语音识别工具包,现已更新到 WeNet 2.0,在各种语料库上的相对识别性能比原始 WeNet 提高了 10%。WeNet正在积极开发 3.0版本,更关注无监督自学习、设备端模型探索和优化,以及生产级 ASR 的其他特性。
支持语言:中文。
· 项目链接:https://github.com/wenet-e2e/wenet
· 论文地址:https://arxiv.org/abs/2203.15455
star:3.4k

MASR
MASR 是一个基于端到端的深度神经网络的中文普通话语音识别项目,同时兼容在线和离线识别。
支持语言:中文。
· 项目地址:https://github.com/nobody132/masr
· 中文介绍:https://blog.csdn.net/HELLOWORLD2424/article/details/123667877
star:1.8k
FunASR
FunASR 是一个开源语音识别工具包,有望在语音识别方面建立学术研究和工业应用之间的桥梁。通过支持在 ModelScope 上发布的工业级语音识别模型的训练和微调,研究人员和开发人员可以更方便地进行语音识别模型的研究和生产,并促进语音识别生态系统的发展。
支持语言:中文、英文。
· 论文地址:https://arxiv.org/abs/2305.11013
· 项目地址:https://github.com/alibaba-damo-academy/FunASR
star:1.2k

趋动云助力ASR科研
趋动云作为领先的算力服务商,在多媒体领域为研究者和开发者提供卓越支持,具有多种优势。
首先,其算力使用灵活,成本可控。用户可按需使用 GPU 算力,避免昂贵的设备采购费用,实现更经济高效的计算资源管理,提升研究的成本效益。
其次,趋动云提供可扩展的存储方案。在处理庞大多媒体数据的模型训练和测试时,扩展性存储方案可以使用户能够根据实际需求自由存储和获取数据,为研究提供更大的灵活性和便利性。
另外,平台内置了丰富的数据集和 AI 模型资源,覆盖多个领域。用户可以方便地选择适用于其研究的数据集和模型,从而节省大量研究时间。例如,zhvoice 语料库和 THCHS-30 汉语语音识别数据,即可用于多种语言相关任务。
总而言之,趋动云在提供强大计算资源和全面支持的同时,通过其安全可靠的多样化软件配置和强大的GPU计算资源,为研究者提供了一个安心、高效的研究环境。这使得研究者能够更专注于 ASR 技术的研究和优化,推动该领域的发展。
出自:https://zhuanlan.zhihu.com/p/670229705
Resemble.ai的AI语音生成器是一个完整的生成式语音AI工具包,允许您在几秒钟内创建类似人类的声音。