金融行业的开源AI大模型
发布时间:2024年06月06日
大家经常把通用大模型比喻为高考前的学生,智商似乎达到了巅峰,天文地理历史生物无所不知,但是对某个行业的真实运作缺乏一定的了解。而行业大模型,就像专业的本科生、研究生、博士生或者是行业从业人员,对自己领域的知识能够快速理解,对业务能够迅速处理。行业大模型的训练过程,跟读书的过程很像,先获得通用知识并具备一定的逻辑推理能力,再到某个行业里进行”微调“深造。
BloombergGPT等金融机构发布的大模型,利用其对专业数据的独家访问来训练特定于金融的语言模型。然而,模型的数据收集和训练协议的可访问性和透明度受到限制,也有着密集的计算需求并产生高昂的适应成本,这加剧了对更开放和包容的替代方案的需求。
金融领域有大量的公开信息,例如上市企业年报,地区和国家的经济数据,公开市场的交易信息,这些高质量的数据非常有利于行业大模型的训练。因为受到监管的约束,大型金融机构的产品和运作模式也会比较趋同,一套通用的开源大模型也许可以覆盖不同机构90%的需求。
许多企业和研究机构开始推动开源金融大模型的发展,不仅仅提供开源的模型参数,有的项目还提供了训练的数据和测评的基准,降低了金融大模型开发的成本和门槛,使更多人能够利用这些模型进行金融分析、情感分析和预测等。
今天来介绍下金融行业中的开源AI大模型项目。
·
FinGPT
·
介绍:
FinGPT项目由AI4Finance-Foundation开发,是一个开源的金融大型语言模型(FinLLM),旨在开源领域实现互联网规模的金融数据民主化。哥伦比亚大学的Hongyang (Bruce) Yang等在FinGPT: Open-Source
Financial Large Language Models一文中介绍了该框架的内容。
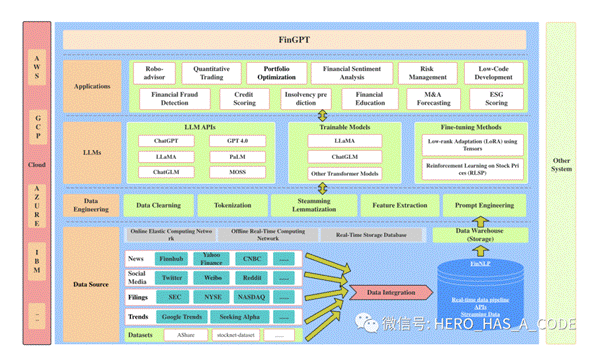
FinGPT框架,资料来源:《FinGPT: Open-Source Financial Large Language Models》
与专有模型不同,FinGPT代表了一个创新的开源框架,采用以数据为中心的方法,专门为在金融领域应用大语言模型(LLMs)而设计。该项目通过五层全栈框架提供综合的市场覆盖,包括数据源层、数据工程层、LLMs层、任务层和应用层,旨在解决金融数据的高时效性和低信噪比问题。这些组件在维护FinGPT在处理动态金融数据和市场条件方面的功能和适应性方面发挥着至关重要的作用。
FinGPT通过专注于顶级开源LLMs的轻量级改编,它不仅提高了透明度,还允许用户定制,以适应个性化金融咨询服务的兴起趋势。FinGPT集成了多个模型,如Llama-2、Falcon、MPT、Bloom、ChatGLM2、Qwen和InternLM,每个模型都针对特定的语言市场和金融分析任务进行了优化。同时,FinGPT的成本效益高、灵活的框架有可能使金融语言建模民主化,提供了一种更容易访问的解决方案。
FinGPT的特色模块包括FinGPT-RAG,专门用于金融情感分析,通过外部知识检索优化信息深度和背景,以及FinGPT-FinNLP,提供金融领域LLM训练和微调的完整流程。FinGPT-Forecaster是一个股价预测工具,可以快速适应新数据,与传统模型相比具有较高的成本效益。
FinGPT提供了多种数据集和多任务金融LLM模型,用于情感分析、金融关系提取和问答等任务,并能够有效、低成本地适应金融领域的动态变化,并利用“人类反馈强化学习(RLHF)”技术进行个性化学习。此外,FinGPT引入了新的指令调整范式,增强了模型适应多样化金融数据集的能力,并促进了开源大型语言模型在金融数据集中的系统性基准测试和成本效益
论文地址:
https://arxiv.org/abs/2310.04793
项目地址:
https://github.com/AI4Finance-Foundation/FinGPT
Github
Star:9600
·
FinGLM
·
介绍:FinGLM 是一个致力于构建开放、公益和持久的金融大模型项目,旨在促进「AI+金融」的开源项目。该项目通过开源的方式探索金融领域中人工智能的应用边界。它主要关注于深度解析上市公司年报,利用AI技术实现专家级别的金融分析,面对金融文本中的专业术语与隐含信息,简化并提高对上市公司年报的解读准确性,帮助投资者更好地理解公司的经营状况、财务状况和未来规划。项目包括数据准备、模型微调、问答等多个流程,并提供了ChatGLM-6B 模型相关课程内容,涵盖PPT、视频和技术文档。
目前开源数据有 70G/1w+份年报数据,包含 11588 份 2019 年至 2021 年期间的部分上市公司年度报告,以及10000条人工标注评测数据等。
FinGLM项目还组织了与金融AI相关的竞赛,以探索和推动该领域的发展。其中SMP 2023 ChatGLM 金融大模型挑战赛(即SMP2023-ELMFT,即金融科技大模型评估)是在第十一届全国社会媒体处理大会(SMP2023)期间举办的。本次比赛要求参赛选手以ChatGLM2-6B模型为中心制作一个财务问答系统,回答用户的金融相关的问题。参赛选手可以使用其他公开访问的外部数据来微调模型,也可以使用向量数据库等技术。今年9月,SMP 2023 ChatGLM 金融大模型挑战赛进行了决赛答辩,并评选出冠亚季军共九支队伍。决赛答辩视频在B站上发布。同时,参赛队伍的答辩PPT和源代码也在Github上开源。
项目地址:https://github.com/MetaGLM/FinGLMGithub Star:978
·
XuanYuan,轩辕(度小满中文金融对话大模型)
·
介绍:轩辕是国内首个开源的千亿级中文对话大模型,同时也是首个针对中文金融领域优化的千亿级开源对话大模型。轩辕在BLOOM-176B的基础上针对中文通用领域和金融领域进行了针对性的预训练与微调,它不仅可以应对通用领域的问题,也可以解答与金融相关的各类问题,为用户提供准确、全面的金融信息和建议。千亿级BLOOM-176B的模型已可以在Huggingface中申请下载。2023年9月22日,度小满宣布“轩辕70B”金融大模型开源,所有用户均可自由下载和试用,并公布了“轩辕70B”在C-Eval、CMMLU两大权威大语言模型评测基准的成绩。轩辕70B(度小满中文金融对话大模型)是由度小满金融开发的中文金融对话大模型,基于Llama2-70B模型进行中文增强。该模型融合了大量中英文语料的增量预训练,包括底座模型和使用高质量指令数据对齐的聊天模型。特别针对金融场景中的长文本业务,它将上下文长度扩展到了8k和16k。轩辕70B大模型在保持中英文通用能力的同时,显著提高了金融理解能力。该项目还包括了通用能力评测和金融领域评测,使用多种客观评测基准,以确保模型在金融领域的有效性和通用性。
论文地址:
https://arxiv.org/abs/2305.12002
项目地址:
https://github.com/Duxiaoman-DI/XuanYuan
Github
Star:504
·
FinanceIQ:中文金融领域知识评估数据集
·
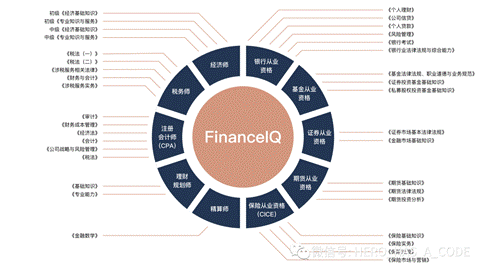
在金融行业中,目前缺乏统一和完善的大模型评估标准。现有的通用框架如C-Eval和CMMLU在金融领域的适用性有限。FinanceIQ,作为轩辕项目的一部分,是一个中文金融领域知识评估数据集。它旨在有效评估模型在金融环境中的表现。该项目提出建立专为金融领域设计的评估体系,分为通用能力、专业知识和场景应用三部分。通用能力评估覆盖语言、数学等方面;专业知识评估重点关注金融领域的具体知识,如寿险、投资等;场景应用则侧重于模型在实际业务环境的表现。
该数据集涵盖了10个金融大类及36个金融小类,包含总计7173个单项选择题,包括CPA、税务师等多个金融领域考试,并且使用GPT4对题目进行改写以测试模型的泛化能力,保证评估的客观性和多样性。为了确保客观公正的评估,所有模型均放在“同一起跑线”上进行测试,题目经过改写和人工校对,以验证模型的泛化能力。FinanceIQ为轩辕项目提供了一个全面且细致的金融领域模型性能评估工具,这一体系旨在更精确评估模型在金融环境的表现,同时降低实际应用的试错成本。
项目地址:
https://github.com/Duxiaoman-DI/XuanYuan/tree/main/FinanceIQ
Github
Star:517
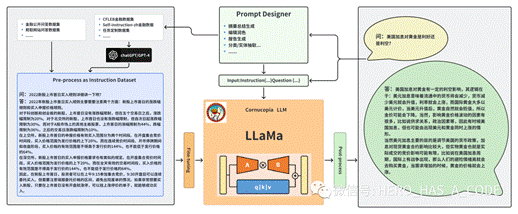
·Cornucopia(聚宝盆):基于中文金融知识的LLaMA微调模型
介绍:该项目是一系列中文金融大模型的开源项目,提供了一套针对金融垂直领域的高效大语言模型训练框架,包括预训练、SFT、RLHF、量化等方法。项目基于LLaMA系列基模型,通过中文金融知识的指令微调(Instruct-tuning)进行了优化,使用中文金融公开问答数据和爬取的金融问答数据构建指令数据集,提高了模型在金融领域的问答效果。此外,项目还计划使用GPT3.5/4.0 API构建更高质量的数据集,并在中文知识图谱-金融、CFLEB金融数据集等基础上扩充指令数据集。近期,项目已发布了基于Chinese-LLaMA和Meta-LLaMA与中文金融数据进行指令微调的模型。
项目地址:
https://github.com/jerry1993-tech/Cornucopia-LLaMA-Fin-Chinese
Github
Star:424
·
Auto-GPT MetaTrader,量化交易插件
·
介绍:Auto-GPT-MetaTrader-Plugin是一款连接MetaTrader交易账户至Auto-GPT的软件工具,使交易者能够利用GPT-4的强大功能进行金融交易。该插件支持执行和管理交易、获取账户信息、提供市场数据等功能,为交易者提供自动化和智能化的交易体验。这不仅展示了AI技术在金融交易中的应用潜力,还为交易者带来了更加高效、便捷的交易方式,进一步推动了金融科技领域的发展。
项目地址:
https://github.com/isaiahbjork/Auto-GPT-MetaTrader-Plugin
Github
Star:385
·
PIXIU貔貅:开源金融大语言模型
·
介绍:PIXIU貔貅是一个面向金融领域的综合性框架。它包括基于LLaMA模型微调得到的首个金融领域大型语言模型(FinMA)、首个包含136K数据样本的指令数据,以及一个涵盖5个任务和9个数据集的评估基准。FinMA模型经过多任务指令调整,能够处理各种金融任务。与此同时,研究团队提出了一个标准化的金融语言模型评估基准,涵盖关键的金融任务,包括五个金融自然语言处理(NLP)任务和一个金融预测任务。实验结果表明FinMA在大多数任务上性能优于现有的LLMs,如BloombergGPT、ChatGPT和GPT-4,尤其是在金融情感分析、新闻标题分类、命名实体识别和股票运动预测方面。这证明了专为金融领域量身定制的LLMs的重要性。此外,所有相关的模型、数据集、基准和实验结果都已开源,以便于未来金融AI的研究。
论文地址:
https://arxiv.org/abs/2306.05443
项目地址:
https://github.com/chancefocus/PIXIU
Github
Star:270
·
DISC-FinLLM,中文金融大语言模型
·
介绍:DISC-FinLLM 是一个专门针对金融场景下为用户提供专业、智能、全面的金融咨询服务的金融领域大模型,由复旦大学数据智能与社会计算实验室 (Fudan-DISC)开发并开源。这个项目通过集成四个模组——金融咨询、金融文本分析、金融计算、金融知识检索问答,构成了一个多专家智慧金融系统。每个模组专注于不同的金融NLP任务,包括与用户就金融话题进行多轮对话、在金融文本上完成信息抽取、情感分析、文本分类、文本生成等任务,以及帮助用户完成数学计算和提供基于金融新闻、研报的投资建议等
论文地址:
http://arxiv.org/abs/2310.15205
项目地址:
https://github.com/FudanDISC/DISC-FinLLM
Github
Star:258
·BBT-FinCUGE-Applications
介绍:项目“BBT-FinCUGE-Applications”致力于提升中文金融领域自然语言处理(NLP)的能力。它包括BBT-FinCorpus,这是一个大规模多样性的中文金融领域开源语料库,以及BBT-FinT5,这是一个基于T5模型架构的中文金融领域预训练语言模型。此外,项目还提供了一套金融领域自然语言处理评测基准CFLEB,涵盖了六种不同的NLP任务。这些成果有助于提高中文金融NLP的性能和泛化能力,尤其对信息抽取等关键任务表现出显著的优化效果。
该项目构建了目前最大规模的中文金融领域开源语料库,包含大约300GB的文本,源自四种不同类型的金融相关数据,如公司公告、研究报告、财经新闻和社交媒体内容。这一丰富多样的语料库有助于提高预训练语言模型的性能和泛化能力。
论文地址:
https://arxiv.org/abs/2302.09432
评测基准网站:
https://bbt.ssymmetry.com/index.html
项目地址:
https://github.com/ssymmetry/BBT-FinCUGE-Applications
Github
Star:179
·
WeaverBird (织工鸟)
·
介绍:这是一个专为金融领域设计的智能对话系统。该系统采用了经过大量金融相关文本调整的GPT架构大型语言模型。这一项目由蚂蚁集团、芝加哥大学和TTIC的研究人员共同开发。这个项目的意义在于为金融领域提供了一个高度专业化和定制化的智能对话系统,有助于提高金融决策的效率和准确性,推动金融科技领域的发展。
论文地址:
https://arxiv.org/abs/2308.05361
项目地址:
https://github.com/ant-research/fin_domain_llm
Github
Star:45
·
·
FLANG (Financial
LANGuage model)
·
介绍:FLANG (Financial LANGuage model) 是一个针对金融领域特定的预训练语言模型。该项目旨在利用金融关键词和短语进行更有效的掩码处理,同时采用跨度边界目标和内部填充目标。FLANG的架构基于ELECTRA训练策略,使用金融特定数据集和常规英语数据集(如Wikipedia和BooksCorpus)。该项目还包括FLUE(Financial Language Understanding
Evaluation),这是一个综合性且多样化的金融领域基准测试,由5个不同的金融领域特定数据集构成。
项目地址:
https://github.com/SALT-NLP/FLANG
Github
Star:30
·InvestLM
介绍:InvestLM是由香港科技大学工商管理学院研究团队开发的一个项目,它是本港首个专为金融界设计的生成式人工智能(AI)开源大语言模型。InvestLM能就金融相关问题与用户进行对话,其回应质量可媲美知名的商业聊天机器人,例如OpenAI的ChatGPT。该模型是通过指令微调技术和精选的财经问答文本对LLaMA-65B模型进行训练得到的,旨在提高金融专业人士的工作效率,例如提供投资建议、写作财经文章等。InvestLM的性能被评为可与最先进的商用大语言模型相媲美,并且在理解金融文本方面展现了强大的能力。此外,研究团队还发现使用领域特定的高质量指令对模型进行训练比使用通用指令更有效果。、
论文地址:
https://arxiv.org/abs/2309.13064
项目地址:
https://github.com/AbaciNLP/InvestLM
Github
Star:21
总结与思考
目前来看,金融行业的开源大模型的进展还并不是特别理想,更多的AIGC应用还是用大模型来间接赋能过去已经有的应用,从而给用户提供更好的 金融服务。
也许行业的开源大模型,应该先从开源的行业数据集开始,当足够高质量的数据被收集被整理被应用的时候,当数据不再被个体垄断,而成为社会的公共财富,才有机会诞生理想的行业大模型,从而解放行业”打工者“的桎梏。
出自:https://mp.weixin.qq.com/s/NiyIDFzSiyvN45aQe8TUig
一个开源项目,允许用户使用 OpenAI Sora 模型使用文本在线生成视频,从而简化视频创建,并具有轻松的一键网站部署功能。