BGE M3-Embedding:智源最新发布的text embedding模型,多语言检索效果超过微软跟openai
发布时间:2024年06月06日
提纲
1 简介
2 BGE M3-Embedding
2.1 训练数据构建
2.2 混合检索
2.3 训练方式
3 实验
4 讨论
参考文献
1 简介
24年的第一个月,智源就发布了新一代text embedding模型BGE M3-Embedding,该模型支持超过100种语言,能够接受不同形式的文本输入,文本最大输入长度扩展到4192,并且支持包括稠密检索,稀疏检索,多向量检索三种不同检索手段。从实验结果上看,在多语言跟跨语种检索任务上,BGE M3-Embedding的效果超过之前提及的微软E5-mistral-7b微软E5-mistral-7b-instruct:
站在LLM肩膀上的text embedding以及openai去年底刚发布的第三代text embedding模型,对于长文本检索也表现优异。
2 BGE M3-Embedding
2.1 训练数据构建
M3-Embedding的训练用了非常庞大且多样化的多语言数据集,数据有三个不同来源。其一是没有标注信息的弱监督数据,来自于从网上挖掘得到的各种有语义关联的数据,并过滤掉其中低质量的内容。其二是来自有标注信息的监督数据,包括若干个中文跟英文的开源数据集,例如MS MARCO,NLI,DuReader等。其三是合成得到的监督数据,利用GPT3.5为来自Wiki跟MC4的长文本生成对应的问题,用于缓解模型在长文档检索任务的不足,同时引入额外的多语言数据。具体情况如下图,这三种不同来源的数据相互补充,分别作用于模型不同阶段的训练,三个源头的数据量逐渐递减,但是数据数量逐渐提升。
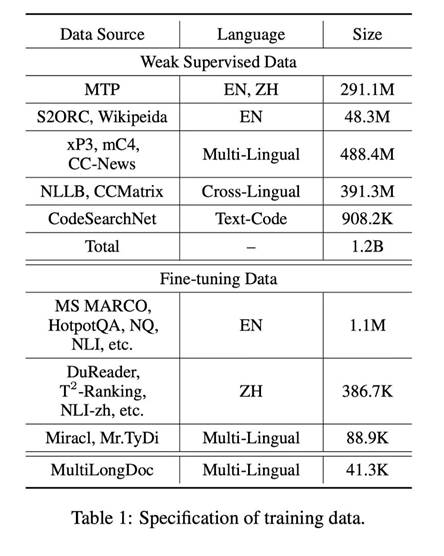
图1:训练数据介绍
2.2 混合检索
M3-Embedding联合了3种常用的检索方式,对应三种不同的文本相似度计算方法,具体如下。
Dense retrieval: 给定一个文本,获取语言模型最后一层上[CLS]位置的隐状态,经过标准化作为文本的稠密向量表征。通过计算query跟doc的向量表征之间的内积就知道文本之间的稠密检索相似度。这是目前主流text
embedding模型用的比较多的一种检索方式,这部分表征更注重文本整体的语义信息。
Lexical Retrieval:给定一个文本,获取语言模型最后一层上所有位置的隐状态,每个位置对应原始文本中的一个token,依次将每个位置的隐状态通过一个全连接层+Relu函数得到该token的权重,将所有每个token的隐状态*对应的权重再求和作为文本的稀疏表征(如果文本包含两个以上相同的token,则该token的权重取其中最大的权重值)。很熟悉的感觉吧,很像tfidf,也跟RetroMAE-V2的第二部分特征很相似,这部分特征更在意文本中各个token的信息,重要的token就赋予更高的权重。
Multi-Vec Retrieval: 给定一个文本,获取语言模型最后一层上所有位置的隐状态,经过一个全连接矩阵跟标准化后得到文本的多向量表征(文本的多向量表征维度为n*d,其中n是文本长度,d是隐状态维度)。给定query,query上第i个位置跟doc的相似度的计算方式为依次计算query第i个位置的多向量表征跟doc各个位置上的多向量表征之间的内积,取其中最大值作为其得分,将query上所有位置跟doc的相似度平均求和就得到对应的多向量表征相似度。其实这就是稠密检索的一个引申版本。
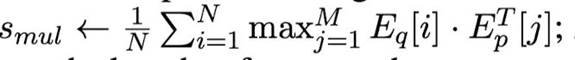
由于提供给了三种不同检索手段,所以M3-Embedding的使用方式也有所不同,首先,可以基于这三种不同的检索手段分别去召回相关文档(就是多路召回),然后基于三种相似度得分平均求和对召回结果做进一步重排。
2.3 训练方式
M3-Embedding的训练损失也相对复杂,包括两部分损失。首先第一部分是对比学习损失,沿用InfoNCE的方式,希望拉近query跟相关文档之间的距离,同时疏远query跟不相关文档之间的距离,但是由于M3-Embedding提供了三种相似度计算方式,所以这里其实是包含了3个对比学习损失的。第二部分蒸馏损失,研究人员将三种不同方式的相似度得分进行加权求和作为teacher分数,然后让三种相似度得分去学习teacher得分的信息,由此得到3个蒸馏损失。模型训练总体损失就是由这2*3个损失通过加权求和得到的。
M3-Embedding采用的多阶段训练,自动编码预训练+弱监督对比学习预训练+监督对比学习finetune,第一阶段的自动编码预训练采用的是RetroMAEBGE登顶MTEB的神器--RetroMAE|一种基于自动编码的检索模型预训练方法,在105种语言的网页跟wiki数据上进行,从而获得一个基底模型。然后第二阶段会在第一个数据源的弱监督数据进行预训练,这阶段的损失损失只考虑基于稠密检索的对比学习损失。最后第三阶段会在第二,三个数据源的监督数据进行训练,这阶段的损失就包括前面提及的所有损失,包括对比学习损失跟蒸馏损失。
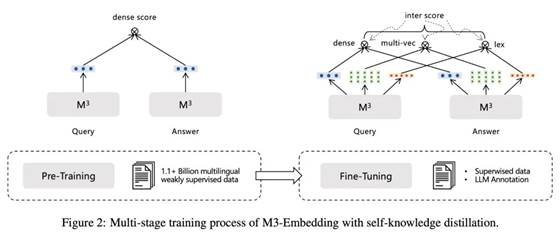
图2:多阶段训练过程
3 实验结果
a) 在多语言检索,跨语言检索,多语言长文档检索等任务上,BGE-3M都有非常不错的效果,超过微软的E5-mistral-7b。同时也看到了使用多种相似度计算方式对于检索性能有明显提升。
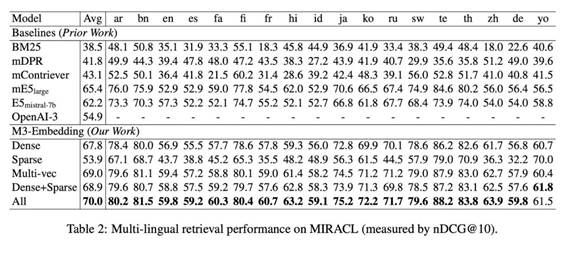
图3:多语言检索效果
b) 通过消融实验对比,可以发现在使用不同相似度计算方式条件下,M3-Embedding中的蒸馏损失都能给最终效果带来明显提升,尤其是对于稀疏检索而言。
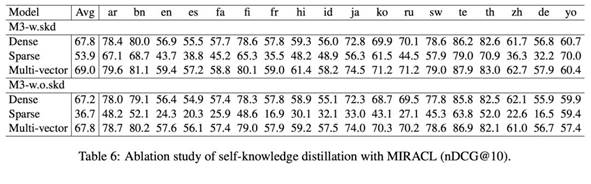
图4:消融实验
4 讨论
从实验结果上看,在检多语言索相关任务上,智源发布的BGE M3-Embedding性能相比微软的E5-mistral-7b跟openai的text
embedding v3确实有所领先,还是在参数量远小于E5-mistral-7b的条件下实现的,这个结果确实很让人惊喜。这个规模的语言模型,在多语言场景下的潜力还有很大的,相比直接劝退玩家的E5-mistral-7b。同样让我很惊喜的是M3-Embedding的多阶段训练过程,在去年的文章中语言模型之text
embedding(思考篇),我提到过自动编码跟弱监督对比学习这两种预训练方式并不冲突,是可以一起使用的,后面或许会出现“自动编码+对比学习+对学学习”这种训练方式,现在看到M3-Embedding也确实是怎么做的,成功预判了大佬们的行动~
看完论文会发现,所有的实验都是在检索任务上进行的,那么在embedding其他相关任务上M3-Embedding的效果又是如何呢?这里我是存有疑问的,毕竟在第三个数据源中的合成数据都是检索数据,加了那么多检索数据,对于检索任务铁定是有提升的,但是对于其他任务呢?应该很快就有玩家会用M3-Embedding把MTEB榜单上所有任务都跑一遍,这样才能更加全面地去评估M3-Embedding的能力。除此之外,M3-Embedding这里已经没有instruction或者prefix的存在了,也就是说,无法通过任务或者场景的描述,去生成特定的文本表征,这种方式其实是不符合目前的主流做法,跟上一代的BGE也不同。可能的解释或许就是这个模型只针对多语言检索任务,或许是有三种不同检索方式的存在限制了instruction或者prefix的使用。
另外一个有趣的现象,不知道大家有没有注意到,无论是微软的E5-mistral-7b,还是智源的M3-Embedding,都是利用GPT4/GPT3.5合成了大量多语言数据,这大概率会成为后续text embedding模型训练数据的一个重要来源。
参考文献1 BGE
M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text
Embeddings Through Self-Knowledge Distillation
https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf
出自:https://mp.weixin.qq.com/s/dopJrFbtr1U8J0xrfRRAvw
Murf AI 是一款文本转语音软件,它能够将真实声音与免版税音乐和视频相结合。