金融领域Prompt工程方法浅析
发布时间:2024年06月06日
自ChatGPT火出圈之后,国内外大模型呈“井喷式”增长,如Google的LaMDA大模型、PaLM模型,Meta的Llama模型,百度的文心一言,智谱AI的GLM大模型等。大模型全称是大型语言模型(LLM,Large Language Model),主要指模型结构复杂,参数多,用于预训练大模型的数据量大的神经网络模型。大模型具有非常强的自然语言处理能力,可以完成诸如机器翻译、问答、文本生成等在内的多种复杂语言任务。尤其是对于特定的任务,不再需要使用该特定任务训练数据去微调模型,只需要调整提示即可快速使得大模型适配特定任务。如何通过设计和优化提示(Prompt)去激发出大模型在特定任务的性能成为自然语言处理领域又一研究热点。这也是提示工程(Prompt Engineering)的意义所在,即通过提供适当提示确保模型输出的准确性和质量。
Prompt意为提示词或引导词,用以描述在AI模型中输入的起始语句或问题,以引导模型进行相关的回答或生成特定内容。其根据slot的形状/位置可以分为:完形填空(Cloze)、前缀模式(Prefix);根据是否由人工指定可以分为:人工指定和自动搜索,其中自动搜索根据搜索空间可以分为离散型和连续型。但不论是何种形式Prompt,其本质都是在寻找一种便于人类与大语言模型之间能够互相理解的清晰表达方式,更大限度地去激发大模型针对特定任务的能力。
一、金融领域文本的特殊性
Prompt工程是一种在自然语言处理领域的方法论,它专注于设计和构建合适的输入提示(prompt)来引导预训练的语言模型生成特定类型的输出,同时通过不断调整优化确保模型输出的准确性和质量。在金融领域实践Prompt工程,首先分析一下金融领域文本的特点,相比通用领域有其特殊性:
1.复杂性和专业性:金融领域涉及大量的法规、政策、市场动态和金融工具,金融市场和金融产品的表现受宏观经济、政治环境、行业动态等多种因素影响,这些内容往往需要专业的金融知识和理解才能掌握。相比之下,通用领域的知识和技能往往更具有普遍性,更容易被大众理解和掌握。
2.高风险性:金融领域的决策往往涉及大量的资金和资源,金融领域文本往往会涉及对未来市场走势、金融产品价格等方面的预测,同时对潜在风险进行提示和建议。如果决策失误,可能会给企业或个人带来严重的经济损失。
3.高度监管性:金融领域是受到高度监管的领域,各种政策和法规对金融活动进行着严格的限制和管理。金融行业的从业者和研究者需要密切关注政策动态,以便及时调整自己的业务策略。
二、金融Prompt工程流程
基于以上领域特殊性,同时参考跨行业数据挖掘标准流程(CRISP-DM),我们设计了金融Prompt工程流程(Financial Prompt Engineering
Process,FinPEP),其概述图如图1所示。FinPEP模型为金融Prompt工程提供了一个完整的过程描述,将一个金融Prompt工程分为5个不同的,但顺序并非完全不变的阶段。
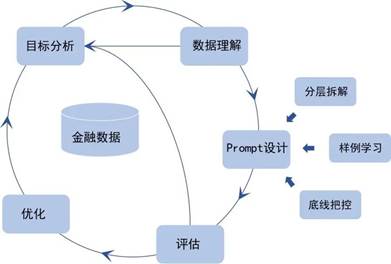
图1 金融Prompt工程流程概述图
目标分析:在这一阶段须从任务场景的角度了解任务的要求和最终目的,并将这些目的与所用大模型能力、特性结合起来进行全面分析。主要工作包括:确定任务目标,从任务场景角度描绘任务的首要目标,评估形势,查找现有资源,以及制定解决方案过程中考虑到的各种其他的因素,包括风险、局限等。
数据理解:数据理解阶段主要是对任务所涉及数据进行全面分析,如:数据存储形式,数据量级,数据内容理解,数据个例分析等。对数据有初步的理解,进而对初步制定的解决方案进行微调。主要过程包括:收集原始数据,分析数据特征,微调解决方案等。
Prompt设计:此阶段基于目标分析、数据理解两阶段的结果,针对任务场景设计Prompt。
评估:此阶段主要使用设计的Prompt喂入所选用大模型进行测试得出评估指标(如精确率、召回率等)查看是否达标,同时对模型具体输出进行分析,评估模型输出是否达到目标分析阶段各项要求。评估是否仍然有一些重要的问题还没有被充分地加以注意和考虑。
优化:此阶段根据评估阶段分析测评结果对Prompt各个部分进行优化调整,用以确保在Prompt正式部署使用前达到最优状态。
三、Prompt设计原则及提示框架
如上述所言因金融领域具有其特殊性,我们提出Prompt设计的三大原则:
1、分层拆解原则:主要针对金融领域的复杂性提出的设计原则。具体是指针对复杂的任务场景及其涉及的纷繁复杂的金融数据分层拆解为独立子任务,在提高大模型输出的可解释性的同时便于后期的优化提升以及Prompt管理。
2、样例学习原则:主要针对金融领域数据的专业性以及高风险性提出的设计原则。该原则提供模型样例学习一方面缓解金融数据的专业性带来的大模型“幻觉”问题,同时通过样例学习来提升模型在特定任务上的输出准确性以此降低金融风险。
3、底线把控原则:主要针对金融领域的高度监管性,通过Prompt设计提升大模型输出合规性。与此同时该原则也把控模型输出格式,便于基于大模型能力的产品开发。
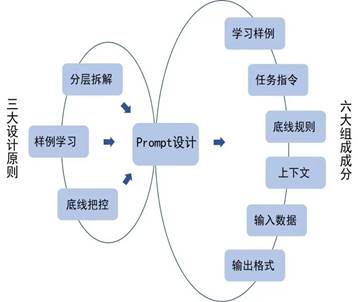
图 2 Fin-LTBCIO Prompt提示框架
基于上述金融Prompt三大设计原则,同时参考业界通用方法,我们提出Fin-LTBCIOPrompt提示框架主要包含学习样例(Learning samples)、任务指令(Task instructions)、底线规则(Baseline rules)、上下文(Context)、输入数据(Input data)及输出格式(Output indicator)六大组成成分,具体如图2所示,当然六大组成成分可根据具体任务场景进行调整。
学习样例用以提升大模型在特定任务中输出准确性同时缓解大模型“幻觉”问题,学习样例数量通常为5(需根据所使用大模型可处理文本长度以及响应速度进行调整),同时需要注意学习样例应具典型性和代表性,该部分示例如表1所示。
表 1 “学习样例”示例
|
成分名称 |
示例 |
|
学习样例 |
信息抽取,遵循以下原则: 1、严格基于“已知文本”进行具体信息抽取,不允许在答案中添加编造成分 2、没有的相关字段则填充空白 3、以json形式输出 其中涉及文本为金融监管类数据 已知文本:行政处罚决定书文号x银保监罚决字〔xxxx〕xx号被处罚当事人姓名或名称个人姓名xxx、xxx单位名称中国xxxx保险股份有限公司xx分公司法定代表人(主要负责人)姓名xx主要违法违规事实(案由)给予投保人保险合同约定以外利益行政处罚……予以警告并处8万元罚款的行政处罚。作出处罚决定的机关名称xx银保监局作出处罚决定的日期20xx年x月xx日 附件信息: 标准输出格式: { "行政处罚决定书文号": "", "被处罚机构":"", "被处罚机构法定代表人(主要负责人姓名)":"", "被处罚当事人(个人)": "", "主要违法违规事实(案由)": "", "行政处罚依据": "", "行政处罚决定": "", "作出处罚决定的机关名称": "", "作出处罚决定的日期": "YYYY年MM月DD日" }
{ "行政处罚决定书文号": "xx保监罚决字〔xxxx〕xx号", "被处罚机构":"中国xxxx保险股份有限公司xx分公司", "被处罚机构法定代表人(主要负责人姓名)":"齐x", "被处罚当事人(个人)": "张xx、陈xx", "主要违法违规事实(案由)": "给予投保人保险合同约定以外利益", "行政处罚依据": "《中华人民共和国保险法》第一百六十一条、第一百七十一条", "行政处罚决定": "对中国xxxx保险股份有限公司xx分公司予以xx万元罚款……予以警告并处x万元罚款的行政处罚。", "作出处罚决定的机关名称": "xx银保监局", "作出处罚决定的日期": "20xx年x月xx日" } |
任务指令是以简洁、专业的表述告知模型须执行的任务。底线规则用以设定在当前任务中模型处理金融文本中应遵循的准则,降低风险。上下文部分是对“输入数据”额外补充知识如文本类型描述、文本前后文知识等,用以增加模型在金融领域特定任务知识储备,一定程度上增加模型金融专业能力。输入数据部分指任务所需处理的具体数据。输出格式部分用以控制模型的输出形式便于基于大模型能力的后期开发。任务指令、底线规则、上下文、输入数据、输出格式五部分具体示例如表2所示。
表2 任务指令、底线规则、上下文、输入数据、输出格式五部分具体示例
|
成分名称 |
示例 |
|
任务指令 |
信息抽取 |
|
底线规则 |
1、严格基于输入数据进行信息抽取,不允许在答案中添加编造成分 2、没有的相关字段则填充空白 3、以json形式输出 |
|
上下文 |
涉及文本为金融监管类数据 |
|
输入数据 |
(xx银行股份有限公司xx分行)行政处罚决定书文号xx保监罚决字〔xxxx〕xx号被处罚当事人姓名……决定罚款xx万元作出处罚决定的机关名称xx银保监分局作出处罚决定的日期20xx年xx月xx日 附件信息: |
|
输出格式 |
标准输出格式: { "行政处罚决定书文号": "", "被处罚机构":"", "被处罚机构法定代表人(主要负责人姓名)":"", "被处罚当事人(个人)": "", "主要违法违规事实(案由)": "", "行政处罚依据": "", "行政处罚决定": "", "作出处罚决定的机关名称": "", "作出处罚决定的日期": "YYYY年MM月DD日" } |
四、小结
基于金融领域文本特性,具体包括复杂性和专业性、高风险性、高监管性等,我们有针对性地提出金融Prompt工程流程FinPEP,其中金融Prompt设计遵循分层拆解原则、样例学习原则、底线把控原则等三大原则,并根据三大原则提出Fin-LTBCIO Prompt提示框架,框架包含学习样例、任务指令、底线规则、上下文、输入数据及输出格式等六个组成部分,支持大模型在金融领域的场景化应用。Prompt设计是大模型应用的重要组成部分,随着人工智能大模型技术不断进步,各类大模型应用定将在金融领域发挥更大的作用,助力企业和行业开创更美好的未来。
出自:https://mp.weixin.qq.com/s/WXqZsl0a-WUCkJEvkZ8S7w
支持一分钟生成专业级短视频,多种生成方式,AI视频脚本,在线云编辑,画面自由替换,热门配音媲美真人音色,更多强大功能尽在Q.AI