网易有道强力开源中英双语语音克隆
发布时间:2024年06月06日
项目地址(基于PromptTTS):
https://github.com/netease-youdao/EmotiVoice
EmotiVoice
Docker镜像
尝试EmotiVoice最简单的方法是运行docker镜像。你需要一台带有NVidia GPU的机器。先按照Linux和Windows WSL2平台的说明安装NVidia容器工具包。然后可以直接运行EmotiVoice镜像:
docker run -dp 127.0.0.1:8501:8501 syq163/emoti-voice:latest
现在打开浏览器,导航到http://localhost:8501,就可以体验EmotiVoice强大的TTS功能。
完整安装
conda create -n EmotiVoice python=3.8 -y
conda activate EmotiVoice
pip install torch torchaudio
pip install numpy numba scipy transformers==4.26.1 soundfile yacs g2p_en jieba pypinyin
准备模型文件
git lfs install
git lfs clone https://huggingface.co/WangZeJun/simbert-base-chinese WangZeJun/simbert-base-chinese
推理
1. 下载预训练模型, 然后运行:
mkdir -p outputs/style_encoder/ckpt
mkdir -p
outputs/prompt_tts_open_source_joint/ckpt
2.
将g_*, do_*文件放到outputs/
prompt_tts_open_source_joint/ ckpt
将checkpoint_*放到outputs/中
style_encoder/ ckpt
3. 推理输入文本格式是:
<speaker>|<style_prompt/emotion_prompt/content>|<phoneme>|<content>.
例如: Maria_Kasper|非常开心|<sos/eos> uo3 sp1 l ai2 sp0 d ao4 sp1 b ei3 sp0 j ing1 sp3 q.
ing1 sp0 h ua2 sp0 d a4 sp0 x ve2 <sos/eos>|我来到北京,清华大学
4. 其中的音素(phonemes)可以这样得到:
python.
frontend.py data/my_text.txt > data/my_text_for_tts.txt
5. 然后运行:
TEXT=data/inference/text
python inference_am_vocoder_joint.py \
--logdir prompt_tts_open_source_joint \
--config_folder config/joint \
--checkpoint g_00140000 \
--test_file $TEXT
合成的语音结果在:
outputs/prompt_tts_open_source_joint/test_audio.
6. 或者你可以直接使用交互的网页界面:
pip install streamlit
streamlit run demo_page.py
训练
待推出。
未来工作
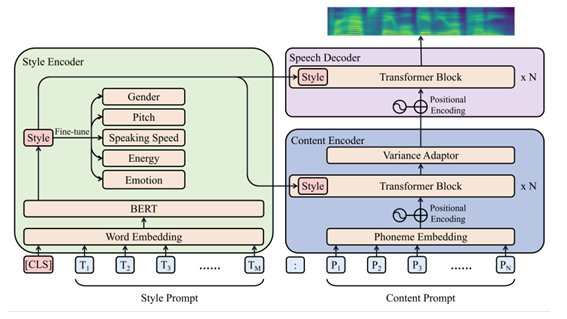
当前的实现侧重于通过提示控制情绪/风格。它只使用音高、速度、能量和情感作为风格因素,而不使用性别。但是将其更改为样式、音色控制并不复杂,类似于PromptTTS的原始闭源实现。
致谢
PromptTTS. PromptTTS论文是本工作的重要基础。
LibriTTS. 训练使用了LibriTTS开放数据集。
HiFiTTS. 训练使用了HiFi TTS开放数据集。
ESPnet.
WeTTS
HiFi-GAN
Transformers
tacotron
KAN-TTS
StyleTTS
Simbert
许可
EmotiVoice是根据Apache-2.0许可证提供的 - 有关详细信息,请参阅许可证文件。
交互的网页是根据用户协议提供的。
出自:https://mp.weixin.qq.com/s/ufejXZQkGy_6URg7Eb55YA
一个免费的 AI 驱动的艺术生成器,可让您从文本描述或照片中创建独特的艺术品。它利用 Stable Diffusion 和 SDXL 人工智能,提供了一个多功能平台,用于生成各种风格的艺术作品。