Stablediffusion3论文下载-确定了Stablediffusion3与Sora的架构是一致的
发布时间:2024年06月06日
Stable_diffusion_3官方论文发布,确定了,Stablediffusion3与Sora的架构是一致的。
原始英文版论文和中文翻译版论文的下载在本文右侧下载区,请自取。


2月16日伴随着OpenAI世界大模型Sora的发布,stability_ai也发布了其最新的模型Stablediffusion3,如果说一个是音视频方向,一个是图像生成方向,那么两者没有必然的联系,但Sora和Stablediffusion3的架构是出奇的一致,核心部分都是采用了Difusion Transformer的方式(在Stablediffusion3中称之为DiT)。

今天,我们将发表研究论文,深入探讨为《稳定扩散 3》提供动力的底层技术。
根据人类偏好评估,Stable Diffusion 3 在排版和及时性方面优于 DALL-E 3、Midjourney v6 和 Ideogram v1 等最先进的文本到图像生成系统。
我们新的多模态扩散变换器(MMDiT)架构为图像和语言表示使用了单独的权重集,与 SD3 以前的版本相比,提高了文本理解和拼写能力。


我们将稳定扩散 3 的输出图像与其他各种开放模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及封闭源代码系统(如 DALL-E 3、Midjourney v6 和 Ideogram v1)进行了比较,以便根据人类反馈来评估性能。在这些测试中,人类评估员从每个模型中获得输出示例,并要求他们根据模型输出在多大程度上紧跟所给提示的上下文("紧跟提示")、在多大程度上根据提示渲染文本("排版")以及哪幅图像具有更高的美学质量("视觉美学")来选择最佳结果。

Prompt: A surreal and humorous scene in a
classroom with thewords 'GPUs go brrrrrr' written in
white chalk on a blackboard. IInfront of the blackboard, a group of students are
celebrating. Theese students are uniquely
depicted as avocados, complete withlittle
arms and legs, and
faces showing expressions of joy and excitement. The scene captures a playful and
imaginativeatmosphere, blending the concept of a traditional classroom witth the whimsical portrayal of avocado students
翻译:教室里的一个超现实幽默的场景,黑板上用白色粉笔写着“GPUs go brrrrr”。IIn
在黑板前,一群学生正在庆祝。这些学生被独特地描绘成鳄梨
小胳膊小腿,脸上流露出喜悦和兴奋的表情。这个场景捕捉到了一个有趣而富有想象力的
氛围,融合了传统课堂的概念和鳄梨学生的异想天开的形象
根据测试结果,我们发现
Stable Diffusion 3 在上述所有方面都与目前最先进的文本到图像生成系统相当,甚至更胜一筹。
在消费级硬件上进行的早期未优化推理测试中,我们最大的 8B 参数 SD3 模型适合 RTX
4090 的 24GB VRAM,使用 50 个采样步骤生成分辨率为 1024x1024 的图像需要 34 秒。此外,在最初发布时,稳定扩散 3 将有多种变化,从 800m 到
8B 参数模型不等,以进一步消除硬件障碍。
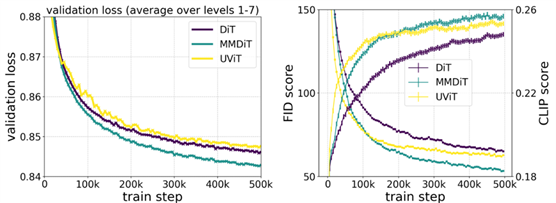
在训练过程中测量视觉保真度和文本对齐度时,我们新颖的 MMDiT 架构优于 UViT(Hoogeboom 等人,2023
年)和 DiT(Peebles 和 Xie,2023 年)等成熟的文本到图像骨干。

得益于《稳定扩散 3》改进的提示跟踪功能,我们的模型有能力制作出聚焦于各种不同主题和质量的图像,同时还能高度灵活地处理图像本身的风格。

Prompt: Translucent pig, inside is a smaller pig.半透明的猪,里面是一个较小的猪。
Prompt: A massive alien space ship that is shaped like a pretzel.一艘巨大的外星飞船,形状像椒盐卷饼。

性能对比
我们将稳定扩散 3 的输出图像与其他各种开放模型(包括 SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α)以及封闭源代码系统(如 DALL-E 3、Midjourney v6 和 Ideogram v1)进行了比较,以便根据人类反馈来评估性能。在这些测试中,人类评估员从每个模型中获得输出示例,并要求他们根据模型输出在多大程度上紧跟所给提示的上下文("紧跟提示")、在多大程度上根据提示渲染文本("排版")以及哪幅图像具有更高的美学质量("视觉美学")来选择最佳结果。
根据测试结果,我们发现 Stable Diffusion 3 在上述所有方面都与目前最先进的文本到图像生成系统相当,甚至更胜一筹。
在消费级硬件上进行的早期未优化推理测试中,我们最大的 8B 参数 SD3 模型适合 RTX
4090 的 24GB VRAM,使用 50 个采样步骤生成分辨率为 1024x1024 的图像需要 34 秒。此外,在最初发布时,稳定扩散 3 将有多种变体,从 800m 到
8B 参数模型不等,以进一步消除硬件障碍。
架构细节
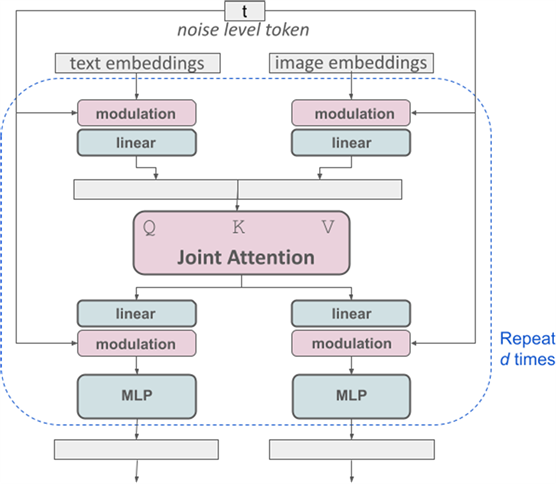
对于文本到图像的生成,我们的模型必须同时考虑文本和图像两种模式。因此,我们称这种新架构为 MMDiT,意指其处理多种模式的能力。与之前版本的稳定扩散一样,我们使用预训练模型来推导合适的文本和图像表征。具体来说,我们使用三种不同的文本嵌入模型--两种 CLIP 模型和 T5--来编码文本表征,并使用改进的自动编码模型来编码图像标记。
SD3 架构基于扩散变换器("DiT",Peebles & Xie,2023 年)。由于文本嵌入和图像嵌入在概念上有很大不同,因此我们对两种模式使用两套不同的权重。如上图所示,这相当于为每种模态设置了两个独立的变换器,但将两种模态的序列结合起来进行注意力操作,从而使两种表征都能在各自的空间内工作,同时也将另一种空间考虑在内。
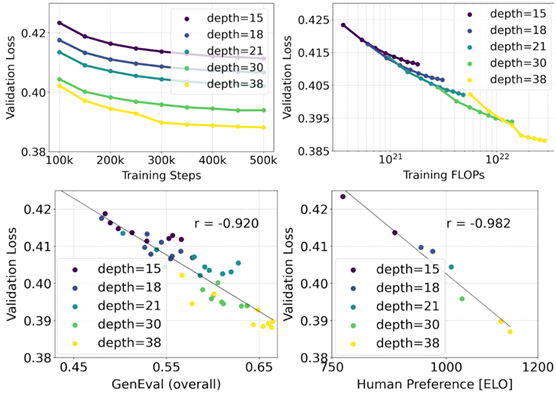
我们利用重新加权的整流公式和 MMDiT 骨干网对文本到图像的合成进行了扩展研究。我们训练的模型从带有 450M 个参数的 15 个图块到带有 8B 个参数的
38 个图块不等,并观察到验证损失随着模型大小和训练步骤的增加而平稳减少(上排)。为了检验这是否转化为模型输出的有意义改进,我们还评估了自动图像配准指标(GenEval)和人类偏好分数(ELO)(下行)。我们的结果表明,这些指标与验证损失之间存在很强的相关性,这表明后者可以很好地预测模型的整体性能。此外,缩放趋势没有显示出饱和的迹象,这让我们对未来继续提高模型性能持乐观态度。
由于原始论文过大,我借助Kimi帮我总结了论文。
这篇论文的标题是《Scaling Rectified Flow Transformers for High-Resolution Image
Synthesis》,作者是来自Stability AI的多位研究人员。论文主要研究了如何通过改进现有的噪声采样技术来训练Rectified Flow模型,以便在高分辨率图像合成中取得更好的性能。以下是对论文内容的概述:
摘要(Abstract):
- 扩散模型通过逆转数据向噪声的正向路径来创建数据,已成为一种强大的生成建模技术,适用于高维、感知数据如图像和视频。
- Rectified
Flow是一种新型的生成模型,它以直线方式连接数据和噪声。尽管理论上更优越,但在实践中尚未成为标准做法。 - 本研究通过偏向感知相关尺度的噪声采样技术来改进训练Rectified Flow模型的方法,并展示了这种方法在高分辨率文本到图像合成中的优越性能。
- 作者提出了一种基于Transformer的新型架构,用于文本到图像的生成,该架构为两种模态(图像和文本)使用独立的权重,并在图像和文本标记之间实现双向信息流,提高了文本理解、排版和人类偏好评分。
- 通过大规模研究,作者证明了这种架构遵循可预测的缩放趋势,并且较低的验证损失与通过各种指标和人类评估测量的改进的文本到图像合成性能密切相关。
引言(Introduction):
- 扩散模型通过训练来逆转数据向随机噪声的正向路径,与神经网络的近似和泛化特性结合,可以生成新的数据点。
- 扩散模型已成为从自然语言输入生成高分辨率图像和视频的事实上的方法。
- 为了提高这些模型的训练效率和/或加快采样速度,研究者们对更有效的训练公式进行了研究。
无模拟训练的流(Simulation-Free Training of Flows):
- 作者考虑了定义从噪声分布到数据分布的映射的生成模型,这些映射以常微分方程(ODE)的形式表示。
- 为了提高效率,作者提出了直接回归一个向量场,该向量场在p0和p1之间生成概率路径。
Rectified Flow的流轨迹(Flow Trajectories):
- 作者考虑了不同的流轨迹变体,包括Rectified Flow、EDM、Cosine和(LDM-)Linear。
文本到图像架构(Text-to-Image Architecture):
- 为了处理文本条件图像采样,模型需要考虑文本和图像两种模态。作者使用了预训练模型来获取合适的表示,并描述了扩散骨干的架构。
实验(Experiments):
- 作者进行了大规模研究,比较了不同的扩散模型和Rectified Flow公式,并展示了新公式的好处。
- 通过改进的自动编码器、改进的标题和改进的文本到图像骨干,作者提高了模型的性能。
结论(Conclusion):
- 本研究展示了Rectified Flow模型在文本到图像合成中的潜力,并提出了一种新的时步采样方法,提高了性能。
- 作者还展示了Transformer基础的MM-DiT架构的优势,并进行了模型缩放研究,证明了验证损失的改进与模型性能的提高密切相关。
这篇论文的核心贡献包括:
- 对不同扩散模型和Rectified Flow公式进行了大规模、系统的研究,以确定最佳设置。
- 设计了一种新的、可扩展的文本到图像合成架构,允许在网络内双向混合文本和图像标记流。
- 对模型进行了缩放研究,并展示了可预测的缩放趋势。

在高分辨率图像合成中,作者提出的Transformer基础的MM-DiT(Multimodal Diffusion Transformer)架构是为了处理文本和图像这两种模态的数据。MM-DiT架构的核心思想是利用Transformer网络来同时处理文本和图像信息,并通过双向信息流来提高文本理解、排版和人类偏好评分。以下是MM-DiT架构的工作原理:
- 预训练模型的使用:
- 为了获取合适的文本和图像表示,作者使用了预训练的模型。对于图像,使用预训练的自编码器将RGB图像映射到一个低维的潜在空间。对于文本,使用预训练的文本模型(如CLIP和T5)来编码文本条件。
- MM-DiT架构构建了一个序列,包含文本和图像的嵌入。具体来说,将文本编码和图像的潜在表示(latent pixel representation)结合起来,通过添加位置编码(positional encodings)和展平(flattening)图像块(patches)来创建一个序列。
- 序列通过一系列的调制注意力(modulated attention)和多层感知器(MLP)模块进行处理。这些模块使用嵌入的时序(timestep)和文本向量(cvec)作为输入,通过调制机制来调整网络对不同模态的响应。
- MM-DiT架构的一个关键特点是它允许文本和图像标记之间的双向信息流。这意味着网络可以在处理图像信息的同时考虑文本信息,反之亦然。这种双向流是通过在注意力操作中连接两种模态的序列来实现的,使得两种表示可以在各自的空间中工作,同时考虑到对方。
- 为了研究模型的可扩展性,作者通过增加模型的深度(即注意力块的数量)和隐藏层的大小来参数化模型的大小。这允许模型在不同的复杂性级别上进行训练和评估。
- 在训练过程中,模型通过最小化验证损失来优化。为了评估模型的性能,作者使用了CLIP分数、FID(Fréchet Inception Distance)和人类偏好评分等指标。
MM-DiT架构通过这种多模态处理和双向信息流,能够更好地理解和生成与文本描述相匹配的高质量图像。这种架构在高分辨率图像合成任务中显示出了优越的性能,尤其是在处理复杂文本提示和生成细节丰富的图像方面。
Aitoolhunt,发现最新的人工智能工具、服务、资源,来帮助你完成工作