1.Sora 的训练算力需求大概率是 GPT-4 的 1/4
左右
2.Sora 的推理算力需求是 GPT-4 的 1000 倍以上(这么看来 2 万亿美元市值的 NVIDIA 仍然不是高点)
3.复现 Sora 的难度没有预想中的大,至少训练算力不是瓶颈; 国内靠 A800/H800 的余量仍可以满足
4.国产芯片迎来一次机会,设计并量产 14nm 的中算力、大显存 LLM 推理芯片,可以绕开芯片制程的瓶颈迅速商业化
测算 GPT-4 的训练算力需求
首先估算 GPT-4 的算力需求, 根据 OpenAI 的 Paper:Scaling
Laws for Neural Language Models , 训练
Transformer 模型的理论计算量为FLOPs
≈ 6ND 。其中, N 为模型参数量大小, D 为训练数据量大小:

LLM
每 token 需要的计算量是 6 倍的模型大小
基于一些"众所周知"的消息:
- GPT-4 是一个 MoE 模型,其总参数量估计在 1.6T - 1.8T 之间,激活参数量估计在 400B - 600B 之间, GPT-4 的训练理论计算量需按照激活参数量而非总参数量来估计。 我们假设为
400B 激活。
- GPT-4 的训练数据约为 13T - 20T 之间,我们假设为 20T 数据
则 GPT-4 训练所需的 FLOPs = 6 * 400B * 20T = 4.8 * 10^25
目前最大的模型训练计算量预估在
10^25 - 10^26 之间
那么 GPT-4 需要训练多久呢?
GPT-4 是 2022 年上半年训练的,据说 OpenAI 使用了 25000 张 A100。 每张
A100 的理论算力是 312 TFLOPs。 假设 25k 的超大规模集群训练
所需通信量比 Dense 更高的 MoE 模型,OpenAI Infra 优化利用率 MFU 到 40% (无法 overlap 的通信和访存会大幅降低利用率),则可以推导出来训练所需的时间是:
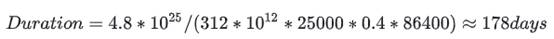 "="">Duration=4.8∗1025/(312∗1012∗25000∗0.4∗86400)≈178days" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
"="">Duration=4.8∗1025/(312∗1012∗25000∗0.4∗86400)≈178days" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-3-Frame">
即大约是 6 个月时间 (与传闻一致)。
如果是改为 H100 的卡,虽然标称了 989 TFLOPs 的单卡算力,实际的训练效率则约为 A100 的 2.5 倍(BF16),因此需要 10000 张 H100 训练半年时间。
如果用 FP8 的混合精度,则能进一步提升至 A100 的 3.5 倍。
测算 Sora 的训练算力需求
根据 OpenAI 的技术报告:Video
generation models as world simulators,Sora 是一个 Diffusion Model, 且应该使用的是Diffusion Transformer(DiT)作为主干模型网络。 虽然 Diffusion Transformer 和 LLM 的 Autoregression Model 架构不同, 但均为 Transformer 架构:
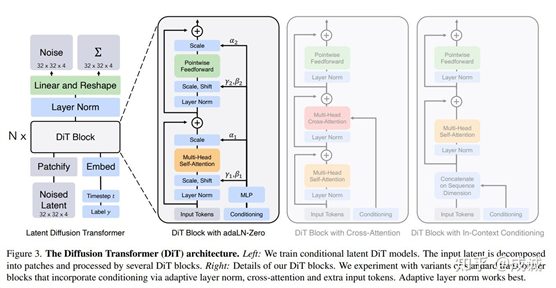
Diffusion
Transformer 架构
且训练时,巨量的数据会随机分布在 T = [0, 1000] 的时间步上,以至于 DiT 的训练计算量估计 和 GPT 的训练计算量估计可以使用相同的公式。(Video Encoder/Decoder 的计算量相比 DiT 可以忽略不计)
Sora
的模型多大呢?
目前大家猜测的出入很大, 从 3B 到 60B 都有。 我们折中一下,假设为 20B 的模型大小。
Sora
训练的数据量有多少呢?
这个猜测的范围就更大了。 一个可供对比的数据量是: 每分钟上传至 YouTube 的视频是 500h 的量级。 则近五年的 YouTube 上的视频数据总量为: 13亿 小时 = 788亿 分钟。由于 Diffusion 模型训练 text to video 需要高质量的标注视频,因此我们可以估计 Sora 训练的视频量级为 1亿 分钟左右。
一分钟的高清视频等价于多少 Token?
目前有一个比较准确的估计,一分钟视频约为 1M tokens 。

Sora
的 Video Encoder 部分
参考 Diffusion Transformer, 256x256 的图片会被划分为 32x32 个 patch。 我们假设 1920x1080 分辨率的高清图像经过下采样得到 512x256 大小的图片,假设一个 patch 为 8x8 的像素块,则得到 64x32 大小的 patch 矩阵,一张图片则约为: 64x32=2048 个 patch。 高清视频 1s 约为 30 帧以上,但实际训练和推理也会做压缩,我们估计压缩后1s 约为 9 帧。则一分钟共
540 帧。 一分钟的视频一共有:

"="">1minVideo=64∗32∗60∗9=1.1Mpatches" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-4-Frame">
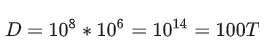 "="">D=108∗106=1014=100T" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-5-Frame">
"="">D=108∗106=1014=100T" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-5-Frame">
则基于 Sora 1亿分钟 video ,估计 Sora 的训练 token 量是 100T tokens


context
length 很大时,Attention 部分的计算不能忽略
因此,如果 Sora 全量数据训练都是 1M seq length,则 Sora 的训练成本需要增加 15 倍。如果 Sora 是先训练一个 32k/64k 的模型,最后再 Continue Training 1M 的模型,则 Sora 的训练成本跟之前预估的接近。

测算 Sora 的推理算力需求
我们假设:
1.用户 Query 调用一次 GPT-4 的 token 开销为 1k tokens (比较准确,实际上会比这个还多一些, OpenAI 的 system prompt 就已经大几百个 token 了)。 阅读一个千字的文章,人肉眼看需要将近一分钟。
2.用户 Query 调用一次 Sora 生成一分钟的视频的 token 开销为 1M tokens (比较准确,推导过程见训练部分的 patch 数量估计)
3.Sora 全面开放访问后,用户调用
Sora 的次数跟调用 GPT-4 的次数一样。 (这个不准确。 但我猜测 Sora 实际的调用需求会远超 GPT-4, 按照用户想法实时生成高清视频对于多巴胺的满足感要超过文本 QA,就像看抖音的次数远超看知乎的次数)
同时我们又在训练部分估计了: GPT-4 是一个 400B 激活参数量的大模型,Sora 是一个 20B 参数量的大模型。
Diffusion Transformer 在推理时的逻辑 和 LLM 不一样,虽然都是 Transformer 架构, Diffusion 需要基于一个随机的 noise latent 矩阵按照多个时间步迭代生成,每一步都在迭代细化 latent (图像/视频)。 在一开始的 Stable Diffusion 推理时是 50 个 step, 后来经过算法优化可以做到 20 个 step,当然也有极限的 1 step 生成的研究(step 越少,图像的效果越差)。 我们假设 Sora 在实际推理时,需要 20 个 step 生成视频。

那么对于单次 Query:
- 推理一个 1k token GPT-4 的计算成本就是: FLOPs = 2 * 400B * 1k = 800T
- 推理一个 1min video (1M tokens ) Sora 的计算成本是: FLOPs = 30 * 20B * 1M * 20 = 12000000T
则得出结论:Sora 推理 1min video
的理论计算量 是 GPT-4 推理 1k token 的理论计算量的 15000 倍。
注: 访存开销的量化分析挪到了文末。
但是推理需求的计算不能只考虑理论计算量。 GPT(所有 LLM)是 Decoder-Only Transformer 架构,通过 Auto Regression 的方式预测下一个 token,是一个完全的 Memory bound 场景,一般实际推理时的 GPU 算力利用率很低,5% 左右。 而Sora
的 DiT 是一个 Encoder-Only
Transformer 架构,推理时会输出全部长度的 token,一次性生成全部长度的 token,对 Memory 的访存次数要远小于 GPT,是一个 Compute Bound 场景,我们假设 Sora 的推理利用率是 50%。不过 Sora 是否是一次性生成 1M token 超长序列是存疑的,我们假设他的 seq len 就是完整的 1M,而非多段(每段大概 5 s,相邻两段有 overlap 的视频帧)顺序生成后拼接得到完整视频。
因此 Sora 推理所需的实际算力需求估计:
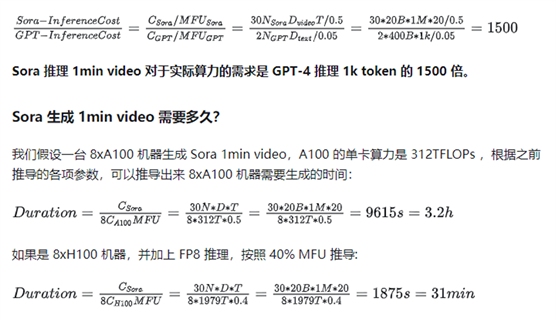 "="">Sora−InferenceCostGPT−InferenceCost=CSora/MFUSoraCGPT/MFUGPT=30NSoraDvideoT/0.52NGPTDtext/0.05=30∗20B∗1M∗20/0.52∗400B∗1k/0.05=1500" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-20-Frame">
"="">Sora−InferenceCostGPT−InferenceCost=CSora/MFUSoraCGPT/MFUGPT=30NSoraDvideoT/0.52NGPTDtext/0.05=30∗20B∗1M∗20/0.52∗400B∗1k/0.05=1500" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-20-Frame">
"="">Duration=CSora8CA100MFU=30N∗D∗T8∗312T∗0.5=30∗20B∗1M∗208∗312T∗0.5=9615s=3.2h" role="presentation" style="display:inline-block;overflow-wrap: normal;max-width:
none;max-height: none;min-width: 0px;min-height: 0px;float:none;word-spacing:
normal" id="MathJax-Element-21-Frame">
Generative AI for Beginners官网入口网址,Generative AI for Beginners 是微软 Cloud Advocates 团队推出的十二章生成式AI入门的系列课程,介绍了构建生成式 AI 应用程序的基础...