我们知道,循环神经网络(RNN)在深度学习和自然语言处理研究的早期发挥了核心作用,并在许多应用中取得了实功,包括谷歌第一个端到端机器翻译系统。不过近年来,深度学习和 NLP 都以 Transformer 架构为主,该架构融合了多层感知器(MLP)和多头注意力(MHA)。
Transformer 已经在实践中实现了比 RNN 更好的性能,并且在利用现代硬件方面也非常高效。基于 Transformer 的大语言模型在从网络收集的海量数据集上进行训练,取得了显著的成功。
纵然取得了很大的成功,但 Transformer
架构仍有不足之处,比如由于全局注意力的二次复杂性,Transformer 很难有效地扩展到长序列。此外,键值(KV)缓存随序列长度线性增长,导致 Transformer 在推理过程中变慢。这时,循环语言模型成为一种替代方案,它们可以将整个序列压缩为固定大小的隐藏状态,并迭代更新。但若想取代 Transformer,新的 RNN 模型不仅必须在扩展上表现出相当的性能,而且必须实现类似的硬件效率。
在谷歌 DeepMind 近日的一篇论文中,研究者提出了 RG-LRU 层,它是一种新颖的门控线性循环层,并围绕它设计了一个新的循环块来取代多查询注意力(MQA)。
他们使用该循环块构建了两个新的模型,一个是混合了 MLP 和循环块的模型 Hawk,另一个是混合了 MLP 与循环块、局部注意力的模型 Griffin。

-
论文标题:Griffin: Mixing Gated Linear Recurrences with Local Attention
for Efficient Language Models
-
论文链接:https://arxiv.org/pdf/2402.19427.pdf
研究者表示,Hawk 和 Griffin 在 held-out 损失和训练 FLOPs 之间表现出了幂律缩放,最高可以达到 7B 参数,正如之前在 Transformers 中观察到的那样。其中 Griffin 在所有模型规模上实现了比强大 Transformer 基线略低的 held-out 损失。
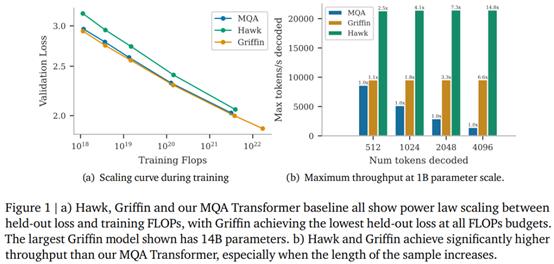
研究者针对一系列模型规模、在 300B
tokens 上对 Hawk 和 Griffin 进行了过度训练,结果显示,Hawk-3B 在下游任务的性能上超越了 Mamba-3B,尽管训练的 tokens 数量只有后者的一半。Griffin-7B 和 Griffin-14B 的性能与 Llama-2 相当,尽管训练的 tokens 数量只有后者的 1/7。
此外,Hawk 和 Griffin 在 TPU-v3 上达到了与 Transformers 相当的训练效率。由于对角 RNN 层受内存限制,研究者使用了 RG-LRU 层的内核来实现这一点。
同时在推理过程中,Hawk 和 Griffin 都实现比 MQA Transformer 更高的吞吐量,并在采样长序列时实现更低的延迟。当评估的序列比训练中观察到的更长时,Griffin 的表现比 Transformers 更好,并且可以有效地从训练数据中学习复制和检索任务。不过当在未经微调的情况下在复制和精确检索任务上评估预训练模型时,Hawk 和 Griffin 的表现不如
Transformers。
共同一作、DeepMind 研究科学家 Aleksandar Botev 表示,混合了门控线性循环和局部注意力的模型
Griffin 保留了 RNN 的所有高效优势和
Transformer 的表达能力,最高可以扩展到 14B 参数规模。
 来源:https://twitter.com/botev_mg/status/1763489634082795780
来源:https://twitter.com/botev_mg/status/1763489634082795780
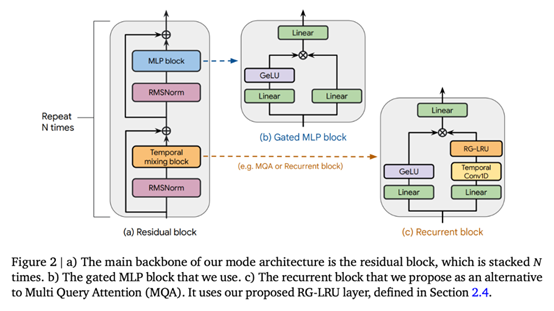
Griffin 所有模型都包含以下组成部分:(i) 一个残差块,(ii) 一个 MLP 块,(iii) 一个时间混合块。所有模型的 (i) 和 (ii) 都是相同的,但时间混合块有三个:全局多查询注意(MQA)、局部(滑动窗口)MQA 和本文提出的循环块。作为循环块的一部分,研究者使用了真实门控线性循环单元(RG-LRU)—— 一种受线性循环单元启发的新型循环层。
如图 2(a)所示,残差块定义了 Griffin 模型的全局结构,其灵感来自 pre-normTransformer。在嵌入输入序列后,研究者将其通过 𝑁这样的块(𝑁表示模型深度),然后应用 RMSNorm 生成最终激活。为了计算 token 概率,应用了最后的线性层,然后是 softmax。该层的权重与输入嵌入层共享。
缩放研究为如何调整模型的超参数及其在缩放时的行为提供了重要见解。
研究者定义了本研究中进行评估的模型,并提供了高达和超过 7B 参数的缩放曲线,并评估了模型在下游任务中的性能。
他们考虑了 3 个模型系列:(1)MQA-Transformer 基线;(2)Hawk:纯 RNN 模型;(3)Griffin:混合模型,它将循环块与局部注意力混合在一起。附录 C 中定义了各种规模模型的关键模型超参数。
Hawk 架构使用了与 Transformer 基线相同的残差模式和 MLP 块,但研究者使用了带有 RG-LRU 层的循环块作为时序混合块,而不是 MQA。他们将循环块的宽度扩大了约 4/3 倍(即𝐷_𝑅𝑁𝑁 ≈4𝐷/3),以便在两者使用相同的模型维度 𝐷时,与 MHA 块的参数数量大致匹配。
Griffin。与全局注意力相比,循环块的主要优势在于它们使用固定的状态大小来总结序列,而 MQA 的 KV 缓存大小则与序列长度成正比增长。局部注意力具有相同的特性,而将循环块与局部注意力混合则可以保留这一优势。研究者发现这种组合极为高效,因为局部注意力能准确模拟最近的过去,而循环层则能在长序列中传递信息。
Griffin 使用了与 Transformer 基线相同的残差模式和
MLP 块。但与 MQA Transformer 基线和
Hawk 模型不同的是,Griffin 混合使用了循环块和
MQA 块。具体来说,研究者采用了一种分层结构,将两个残差块与一个循环块交替使用,然后再使用一个局部(MQA)注意力块。除非另有说明,局部注意力窗口大小固定为 1024 个 token。
主要缩放结果如图 1(a)所示。三个模型系列都是在从 1 亿到
70 亿个参数的模型规模范围内进行训练的,不过 Griffin 拥有 140 亿参数的版本。
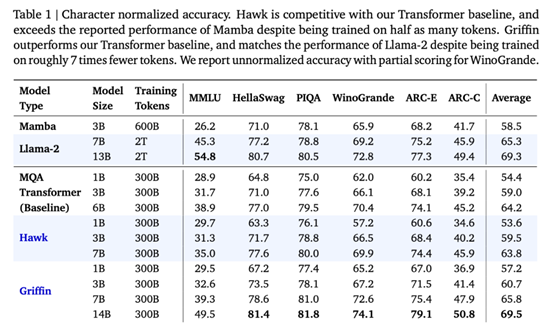
Hawk 和 Griffin 的表现都非常出色。上表报告了 MMLU、HellaSwag、PIQA、ARC-E
和 ARC-C 的特征归一化准确率,同时报告了
WinoGrande 的绝对准确率和部分评分。随着模型规模的增大,Hawk 的性能也得到了显著提高,Hawk-3B 在下游任务中的表现要强于 Mamba-3B,尽管其训练的 token 数量只有 Mamba-3B 的一半。Griffin-3B 的性能明显优于 Mamba-3B,Griffin-7B 和 Griffin-14B 的性能可与 Llama-2 相媲美,尽管它们是在少了近 7 倍的 token 上训练出来的。Hawk 能与 MQA Transformer 基线相媲美,而 Griffin 的表现则超过了这一基线。
在开发和扩展模型时,研究者遇到了两大工程挑战。首先,如何在多台设备上高效地分片处理模型。第二,如何有效地实现线性循环,以最大限度地提高 TPU 的训练效率。本文讨论了这两个难题,然后对 Griffin 和 MQA 基线的训练速度进行实证比较。
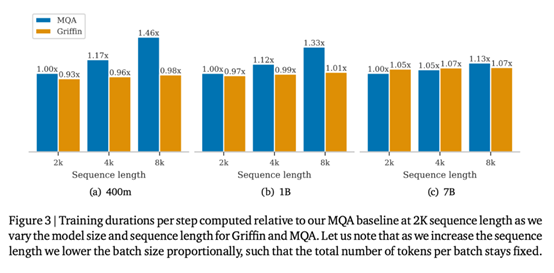
研究者比较了不同模型大小和序列长度的训练速度,以研究本文模型在训练过程中的计算优势。对于每种模型大小,都保持每批 token 的总数固定不变,这意味着随着序列长度的增加,序列数量也会按比例减少。
图 3 绘制了 Griffin 模型与 MQA 基线模型在 2048 个序列长度下的相对运行时间。
LLM 的推理由两个阶段组成。「预填充
」阶段是接收并处理 prompt。这一步实际上是对模型进行前向传递。由于
prompt 可以在整个序列中并行处理,因此在这一阶段,大多数模型操作都是计算受限的因此,研究者预计
Transformers 模型和循环模型在预填充阶段的相对速度与前文讨论的那些模型在训练期间的相对速度相似。
预填充之后是解码阶段,在这一阶段,研究者从模型中自回归地采 token。如下所示,尤其是对于序列长度较长时,注意力中使用的键值(KV)缓存变得很大,循环模型在解码阶段具有更低的延迟和更高的吞吐量。
评估推断速度时有两个主要指标需要考虑。第一个是延迟,它衡量在特定批量大小下生成指定数量 token 所需的时间。第二个是吞吐量,它衡量在单个设备上采样指定数量 token 时每秒可以生成的最大 token 数。因为吞吐量由采样的 token 数乘以批量大小除以延迟得出,所以可以通过减少延迟或减少内存使用以在设备上使用更大的批量大小来提高吞吐量。对于需要快速响应时间的实时应用来说,考虑延迟是有用的。吞吐量也值得考虑,因为它可以告诉我们在给定时间内可以从特定模型中采样的最大 token 数量。当考虑其他语言应用,如基于人类反馈的强化学习(RLHF)或评分语言模型输出(如 AlphaCode 中所做的)时,这个属性是有吸引力的,因为能够在给定时间内输出大量
token 是一个吸引人的特性。
在此,研究者研究了参数为 1B 的模型推理结果。在基线方面,它们与 MQA Transformer 进行了比较,后者在推理过程中的速度明显快于文献中常用的标准 MHA 变换器。研究者比较的模型有:i) MQA 变换器,ii) Hawk 和 iii) Griffin。为了比较不同的模型,我们报告了延迟和吞吐量。
如图 4 所示,研究者比较了批量大小为 16、空预填充和预填充 4096 个
token 的模型的延迟。
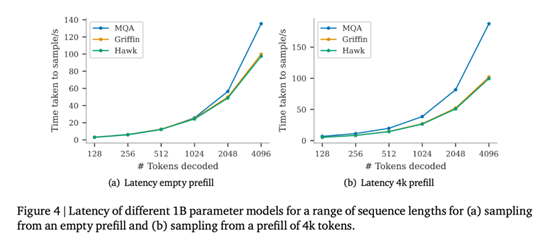
图 1(b)中比较了相同模型在空提示后分别采样 512、1024、2048 和 4196 个 token 时的最大吞吐量(token / 秒)。
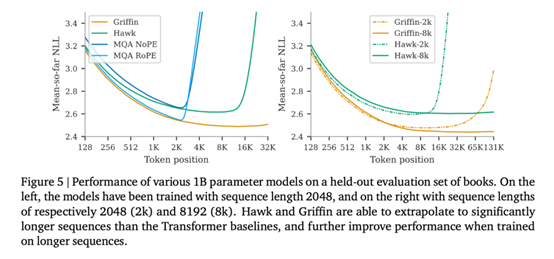
本文还探讨了 Hawk 和 Griffin 使用较长上下文来改进下一个 token 预测的有效性,并研究它们在推理过程中的外推能力。此外还探讨了 Griffin 在需要复制和检索能力的任务中的表现,既包括在此类任务中训练的模型,也包括在使用预训练的语言模型测试这些能力时的表现。
从图 5 左侧的曲线图中,可以观察到,在一定的最大长度范围内,Hawk 和 Griffin 都能在更长的上下文中提高下一个 token 的预测能力,而且它们总体上能够推断出比训练时更长的序列(至少 4 倍)。尤其是 Griffin,即使在局部注意力层使用 RoPE 时,它的推理能力也非常出色。
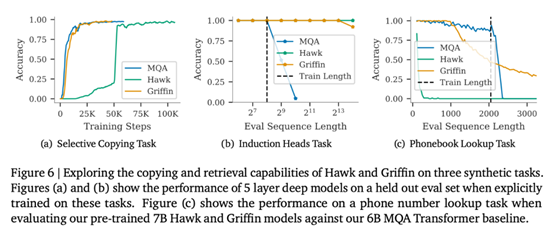
如图 6 所示,在选择性复制任务中,所有 3 个模型都能完美地完成任务。在比较该任务的学习速度时, Hawk 明显慢于 Transformer,这与 Jelassi et al. (2024) 的观察结果类似,他们发现 Mamba 在类似任务上的学习速度明显较慢。有趣的是,尽管 Griffin 只使用了一个局部注意力层,但它的学习速度几乎没有减慢,与 Transformer 的学习速度不相上下。
出自:https://mp.weixin.qq.com/s/R34tP32pUrRRGh-6NXlzXQ
Rezi 是唯一一个使用领先的 AI 来自动化创建可雇用简历的各个方面的简历平台——写作、编辑、格式化和优化。