微软研究团队:Sora核心技术及未来机会研究报告-中英对照版
发布时间:2024年06月06日
原文:Sora:
A Review on Background, Technology, Limitations, and Opportunities of Large
Vision Models
作者:Yixin
Liu,Kai Zhang,Yuan Li,Zhiling Yan,Chujie Gao,Ruoxi Chen,Zhengqing Yuan,Yue
Huang,Hanchi Sun,Jianfeng Gao,Lifang He,Lichao Sun
Lehigh University , Microsoft Research
论文地址:https://arxiv.org/abs/2402.17177v1
摘要
Sora,一款由 OpenAI 在 2024 年 2 月推出的创新性文转视频生成式 AI 模型,能够依据文字说明,创作出既真实又富有想象力的场景视频,展现了其在模拟现实世界方面的巨大潜能。本文基于公开技术文档和逆向工程分析,全面审视了 Sora 背后的技术背景、应用场景、当前面临的挑战以及文转视频 AI 技术的未来发展方向。文章首先回顾了 Sora 的开发历程,探索了支撑这一“数字世界构建者”的关键技术。接着,我们详细探讨了 Sora 在电影制作、教育、市场营销等多个领域内的应用潜力及其可能带来的影响。文章还深入讨论了为实现 Sora 的广泛应用需克服的主要挑战,例如保证视频生成的安全性和公正性。最后,我们展望了 Sora 乃至整个视频生成模型技术未来的发展趋势,以及这些技术进步如何开创人机互动的新方式,进而提升视频创作的效率和创新性。
1.引言
自 ChatGPT 于 2022 年 11 月面世以来,AI 技术已经迎来了翻天覆地的变化,这不仅改变了我们的交流方式,还深刻融入了我们的日常生活和众多行业 [1, 2]。顺应这股趋势,OpenAI 于 2024 年 2 月推出了 Sora,一个能够将文本提示转化为视频的生成式 AI 模型,无论是现实场景还是想象中的场景,它都能够栩栩如生地呈现。区别于以往的视频生成技术,Sora 能够根据用户的文本指令,生成最长达一分钟的高清视频 [3]。Sora 的发展,标志着 AI 长期研究的一个里程碑:让 AI 系统(或 AI 智能体)不仅能理解复杂的用户指令,还能将这些理解应用于解决现实世界的问题,通过动态和情境丰富的模拟互动。

图 2: Sora 的文本到视频生成示例。文本指令输入到 OpenAI 的 Sora 模型中,随后它生成了三段根据指令制作的视频。
Sora 展现了解读和执行复杂人类指令的惊人能力,正如图2中所展示的那样。这个模型能够创造出含有多个角色在复杂背景下进行特定活动的详细场景。研究人员认为,Sora 的高效表现不仅来源于它对用户输入的文本提示的处理能力,还包括它对场景中复杂元素相互作用的敏锐洞察。Sora 最令人瞩目的特点之一是它能够制作长达一分钟的视频,并且视频质量高、视觉连贯性强。不同于早期只能制作短片的模型,Sora 能够让视频从开始到结束都保持着视觉上的连贯性和故事进展。此外,Sora 能够制作包含细致动作和互动的长视频序列,突破了以往模型在视频长度和视觉表现上的限制。这一进步标志着 AI 创意工具的重大飞跃,让用户能够把文字叙述转换成丰富的视觉故事。整体而言,Sora 作为一种世界模拟器,展现了它在描绘场景的物理和情境动态方面的细腻洞察力。[3]。
在技术层面,Sora 的核心是一种预先训练好的扩散式 Transformer [4]。Transformer 模型已在许多自然语言处理任务上证明了其可扩展性和有效性。与 GPT-4 等大型语言模型相似,Sora 能够解析文本并理解复杂的用户指令。为了实现高效的视频生成,Sora 采用了*时空潜码片段(Spacetime Latent
Patches)*作为其基本构成单元。简而言之,Sora 将视频压缩为潜码的时空表示,然后从这个压缩的视频中提取出一系列的时空潜码片段,这些潜码片段概括了短时间内的视觉外观和运动动态。这些潜码片段,相当于语言模型中的词汇 Token,为 Sora 提供了构建视频的详细视觉“短语”。Sora 利用扩散式 Transformer 模型,从一个充满视觉噪点的帧开始,逐步去噪并根据输入的文本提示添加具体细节,最终生成的视频经过多次精细化,更加符合预期的内容和质量。
关于 Sora 的亮点。Sora 的能力对多个领域都有深远影响:
- 提升模拟能力:Sora 的大规模训练让它在模拟物理世界的各个方面表现出色。即便没有具体的3D模型,Sora 也能表现出3D世界的一致性,包括物体的持久存在和简单的世界互动,以及动态的摄像机移动和远景连贯性。更有趣的是,Sora 能够模拟像 Minecraft 这样的数字环境,通过简单的操作策略,同时保持视觉上的真实感。这表明,发展视频模型是模拟物理和数字世界复杂性的有效途径。
- 激发创造力:想象一下,仅通过文本描述,就能在几秒钟内生成一个逼真或极具风格的视频。Sora 加速了设计过程,让艺术家、电影制作人和设计师能够快速探索和精炼他们的创意,极大地激发了他们的创造潜能。
- 推动教育创新:视觉辅助一直是教育中传授重要概念的关键工具。利用 Sora,教师可以轻松地将教学计划从文字转化为视频,吸引学生的注意力,提高教学效果。无论是科学模拟还是历史重现,Sora 都开辟了无限可能。
- 增强可访问性:提高视觉内容的可访问性非常重要。Sora 通过将文字描述转换为视觉内容,为包括视障人士在内的所有人提供了创作和交流的新方式。这让更多人能够通过视频分享自己的想法,营造了一个更加包容的环境。
- 促进新兴应用的发展:Sora 的应用范围十分广泛。从营销人员使用它创建动态广告,到游戏开发者依据玩家的叙事生成定制化视觉效果或角色动作,Sora 都展现了强大的潜力。
限制与机遇:尽管 Sora 取得了显著的技术进步,但仍面临挑战,如更复杂动作的呈现和微妙面部表情的捕捉等。此外,确保生成内容无偏见且安全,避免不良视觉输出的伦理问题,也是开发者和研究者必须重视的。随着视频生成技术的快速发展,Sora 有望成为一个充满活力的生态系统的一部分,这个系统通过合作与竞争,不断推动创新,提升视频品质,创造新的应用,使工作更高效,生活更加丰富多彩。
我们的贡献:本文基于公开的技术报告和我们的逆向工程,首次全面评述了 Sora 的背景、相关技术、应用前景、当前的局限以及未来的机遇。
2.背景
2.1 发展历程
在计算机视觉(CV)这个领域,深度学习带来革命之前,人们主要依靠手工设计特征的方法来生成图像,比如纹理合成 [5] 和纹理映射 [6]。但这些传统技术很难创造出既复杂又生动的图像。随后,生成对抗网络(GANs)[7] 和变分自编码器(VAEs)[8] 的出现成为了一个里程碑,它们在多个领域展现出了惊人的能力。紧接着,流模型 [9] 和扩散模型 [10] 的发展,使图像生成的细节和质量得到了进一步提升。最近,人工智能生成内容(AIGC)技术的进步让内容创作变得更加普及,现在用户可以仅通过简单的文字指令,就能创造出他们想要的内容 [11]。
在过去十年中,生成式计算机视觉模型的发展走过了多条路径,如图 3 所展示的那样。这个领域的转变开始变得明显是在 Transformer 架构在自然语言处理领域取得成功之后,BERT 和 GPT 的出现便是明证。在计算机视觉(CV)领域,研究者们更进一步,将 Transformer 架构与视觉元素相结合,使之能够应用于视觉领域的各种任务,如视觉 Transformer(ViT)和 Swin Transformer 所示。与此同时,扩散模型在图像和视频生成领域也取得了显著的进展。扩散模型通过一个数学上的可靠框架,利用 U-Net 技术将噪声转化为图像,这一过程中,U-Net 通过预测和减少每步的噪声来帮助这一转换。自 2021 年以来,AI 研究的一个重点是开发能够理解人类指令的生成式语言和视觉模型,即多模态模型。例如,CLIP 是一个结合了 Transformer 架构和视觉元素的创新视觉-语言模型,它能够处理大量的文本和图像数据集。通过结合视觉和语言知识,CLIP 能够在多模态生成框架中作为图像编码器的角色。另一个例子是 Stable
Diffusion,这是一个适应性强、使用方便的多功能文本到图像 AI 模型。它使用 Transformer 架构和潜码扩散技术来解析文本输入,生成各种风格的图像,进一步展现了多模态 AI 的发展成就。
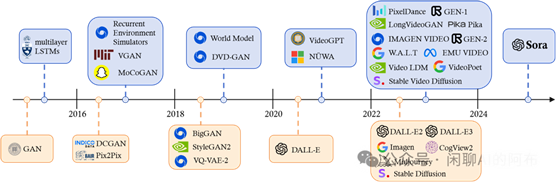
图 3: 视觉领域生成式 AI 发展史。
自 ChatGPT 于 2022 年 11 月面世以来,我们迎来了如 Stable Diffusion(稳定扩散)[19],Midjourney(中途旅程)[20],DALL-E 3[21](#bib.bib21) 这样的商业文本转图像产品的兴起。这些工具让用户可以通过简单的文本提示创造出高分辨率、高质量的图像,展现了 AI 在图像创作领域。
2.2 进阶概念
视觉模型的扩展规律。随着大语言模型的扩展规律逐渐明朗,人们开始探询视觉模型是否也遵循着类似的成长路径。最近,Zhai 等人 [24] 证明了,只要有充分的训练数据,ViT 模型在性能与计算力之间的关系大致呈现一种(趋于饱和的)幂律分布。紧接着,谷歌研究 [25] 提出了一套高效且稳定训练 22B 参数 ViT 模型的策略。实验结果表明,通过冻结模型来生成嵌入,再在其上叠加几层简单的训练层,便能够取得优异的表现。作为一种大型视觉模型,Sora 遵循了这些扩展原则,并在文到视频的生成任务中展现出了多种涌现性能力,这一进步显著地展示了大型视觉模型实现与大语言模型相似突破的可能性。
涌现性能力。大语言模型中的涌现性能力是指在模型达到一定规模时,出现的一些复杂行为或功能,这些并非开发者预先设定或预料的。这些能力之所以被称作“涌现”,是因为它们是模型在广泛的数据集上进行深入训练,并依托其庞大的参数量所自然形成的。这种能力使得模型能够建立起超越简单模式识别或机械记忆的联系和推理。而这些能力的出现,并不能仅通过观察小规模模型的表现来预测。虽然如 ChatGPT 和 GPT-4 等多个大语言模型已展现出涌现性能力,但直到 Sora 的问世,能展现出类似能力的视觉模型还是相当稀缺。根据 Sora 的技术报告,它是首个证实具有涌现性能力的视觉模型,为计算机视觉领域标记了一个重要的发展里程碑。
除了涌现性能力,Sora 还具备其他引人注目的能力,包括跟随指令、视觉提示技术应用以及视频内容理解等。这些能力的展现,代表了在视觉领域取得的重大进步,接下来的章节将对此进行更深入的探讨。
3.技术
3.1
Sora 框架概览
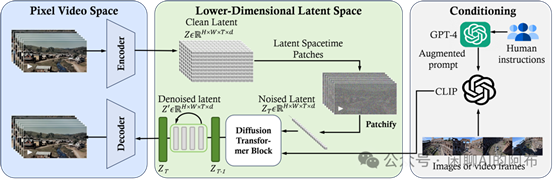
图 4: Sora 框架的反向工程概览
Sora 本质上是一个具备灵活采样尺寸的先进技术,正如图 4 所示。它由三大核心部分组成:(1) 首先,一个时间-空间压缩器将原始视频转换为深层的潜码空间表示。(2) 接下来,一个视觉转换器 (ViT) 处理这些潜码的数据表示,输出清洁、无噪声的视频数据表示。(3) 最后,一个类似于 CLIP 的智能条件设置机制利用大语言模型增强的用户指令和可能的视觉提示,引导视频生成过程,创造出具有特定风格或主题的视频。在经过多次清洁处理之后,视频的深层表示被捕获,并通过一个专门的解码器转换回可视的像素格式。本节旨在揭示 Sora 技术背后的原理,并与广泛的相关研究进行对话。
3.2 数据预处理
3.2.1 视频与图像的多样性:时长、分辨率与宽高比
Sora 的一大特色就是它能够处理、理解并生成各种原生尺寸的视频和图像,正如图5所展示的。与传统方法不同,后者常将视频调整尺寸、裁剪或改变宽高比以符合统一的标准——通常是短片段、正方形帧且分辨率固定较低[27][28][29]。这种处理方式通常会在较宽的时间跨度内生成样本,并依靠专门训练的帧插入和分辨率渲染模型作为最终步骤,导致视频内容的不连贯。Sora 利用了扩散变换器架构[4](详见第3.2.4节),成为了第一个能够适应视觉数据多样性的模型,它可以处理各种格式的视频和图像,从宽屏的1920x1080p到竖屏的1080x1920p,以及介于两者之间的任何尺寸,而不会改变它们的原始尺寸。

图 5: Sora 能生成各种尺寸和分辨率的图像,范围从1920x1080p到1080x1920p及其之间。

图 6: 通过将 Sora(右侧)与一个经过修改以将视频裁剪为正方形的版本(左侧)进行比较,可以看出 Sora 在保持视频原始宽高比方面的优势。
在原始分辨率上训练数据,显著提升了生成视频的构图和画面布局效果。实践证明,保持视频的原始宽高比,Sora 能创造出更加自然流畅的视觉叙事。如图6所示,与那些训练于统一裁剪的正方形视频的模型相比,Sora 明显占据优势,其生成的视频在画面构成上做得更好,确保了场景中的主体被完整地展现,避免了正方形裁剪所常见的部分视角被切割的问题。
这种对视频和图像原有特征的深入洞察和保留,代表了在生成模型领域的一大进步。Sora 的策略不仅展现了生成更自然、更吸引人视频的巨大潜力,还突出了训练数据多样性对于获得高品质生成式 AI 成果的重要性。Sora 的训练方法遵循了 Richard Sutton 在《The Bitter Lesson》[30]中提出的核心观点,即优先利用计算力而不是人工设计的特性,能够打造出更高效、更灵活的 AI 系统。正如原始的扩散变换器设计追求的简洁性和扩展性[31],Sora 采用原始尺寸数据训练的策略,摒弃了传统 AI 依赖于人工抽象概念的做法,转而采用一种随着计算力增长而扩展的全能策略。在本节剩余部分,我们尝试解析 Sora 的架构设计,并探讨为实现这一杰出功能所采用的相关技术。
3.2.2 统一的视觉数据表现形式
为了能够有效处理不同持续时间、分辨率和宽高比的图像和视频等多样化的视觉输入,一个关键策略是将这些不同形态的视觉数据转化为统一的格式。这样做不仅有助于提高生成模型的训练效率,还能提高处理效果。具体而言,Sora 首先将视频数据压缩到一个更低维度的潜码空间中,接着再将这些数据分解为时空片段(Spacetime
Patches)。尽管 Sora 的技术报告[3]只是简略地介绍了这一概念,但这使得其他研究者难以实际操作实验。因此,我们尝试详细解析其可能使用的技术和方法。此外,我们还将探讨一些可能的替代方案,这些方案基于现有研究成果,旨在实现与 Sora 相似的功能。

图 7: 从整体上来看,Sora 将视频通过首先压缩到一个低维潜码空间,再将其分解为时空片段的方式,转换成片段。
3.2.3 视频压缩技术

图 8: ViT 技术将一幅图像分割成多个固定大小的块,对每个块进行线性嵌入,并加入位置信息,然后将这些向量序列输入标准的 Transformer 编码器中进行处理。
Sora 的视频压缩技术旨在降低视频数据的维度,生成一个在时间和空间上都进行了压缩处理的潜码表示(如图7所展示)。根据技术报告中的引用,这一技术基于 VAE 或者向量量化的 VAE (VQ-VAE) [32]。但是,技术报告也提到,如果不进行图像的调整和裁剪,使用 VAE 技术将任意尺寸的视觉数据统一映射到一个固定大小的潜码空间是有一定挑战的。我们在这里介绍两种可能的实现方法,以应对这一挑战:
空间区块压缩(Spatial-patch
Compression)技术。这项技术通过将视频帧分割成固定大小的区块(Patches),然后将这些区块编码到一个隐藏的空间中,从而处理视频。这种方法的灵感来源于 ViT 和 MAE(详见图 8)的处理方式。它特别适用于处理不同分辨率和长宽比的视频,因为它能通过单独处理每个小区块来编码整个视频帧。接下来,这些所谓的空间标记按时间顺序排列,形成一个结合了空间和时间的隐藏表示,这对于视频处理至关重要。该技术考虑到几个关键点:视频时长的变化意味着隐藏空间的时间维度不能固定。解决方案包括选取特定数量的帧(较短视频可能需要加入额外帧或进行时间插值,详见第 3.2.4 节),或者定义一个超长的输入长度以便后续处理;对于高分辨率视频,推荐使用预训练的视觉编码器,比如稳定扩散中的 VAE 编码器。而 Sora 的团队则计划从零开始,自行训练一个包含解码器的压缩网络,后者负责生成视频,这一过程借鉴了训练潜码扩散模型的方法。这些编码器能高效压缩大尺寸的区块,比如 256x256 像素,这对于管理大量数据非常有帮助;而由于该方法主要聚焦于空间上的压缩,因此还需要一个额外的机制来整合时间上的信息。
捕捉随时间发生的动态变化这一方面极其关键,相关的深入讨论将在后续章节中展开。具体内容,您可以参阅第3.2.6 节和图 14。
空间-时间片段压缩技术。这一技术致力于同时封装视频数据的空间和时间维度,以提供一个全方位的表述。它不仅分析静态画面,还考虑了帧之间的运动和变化,有效捕捉了视频的动态特性。采用三维(3D)卷积技术(3D convolution)是实现这种整合的一个直接且有效的方法[37]。这一技术与仅对空间进行划分的方法相比较的图示和分析,展示在图 9 9。与空间片段压缩类似,使用空间-时间片段压缩并设定好的卷积核参数(例如,固定的核大小、步长和输出通道数量)会由于视频输入的特性差异,导致潜码空间维度的不同。这种差异主要是由视频的不同持续时间和分辨率引起的。为应对这一挑战,空间划分的方法同样适用且有效。
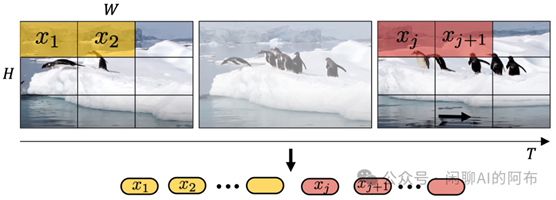
图 9: 视频压缩中不同划分方法的比较。
来源: ViViT [38]。(左图)空间划分仅对 nt 帧进行采样,并按照ViT的方式独立嵌入每一帧2D画面。(右图)空间-时间划分则提取并线性嵌入跨越时空输入体的非重叠或重叠的小块(tubelets)。
总的来说,我们基于变分自编码器(VAE)或其变体如向量量化-变分自编码器(VQ-VQE)逆向工程了这两种片段级压缩方法,因为这样的操作对于处理不同类型的视频更加灵活。鉴于 Sora 旨在生成高保真度的视频,因此采用了较大的片段尺寸或核心尺寸来实现高效压缩。这里,我们偏好使用固定尺寸的片段,以保证简单性、可扩展性和训练的稳定性。但是,也可以使用不同尺寸的片段 [39],以使得整体帧或视频在潜码空间中的维度保持一致。然而,这可能会导致位置编码无效,并为解码器在生成不同尺寸潜码片段的视频时带来挑战。
3.2.4 时空潜码片段(Spacetime Latent Patches)
在视频压缩网络的设计中,我们面临一个关键挑战:如何在输入层处理来自不同视频类型的潜码特征块或片段数量的差异。本节将探讨几种可能的策略。
根据 Sora 的技术报告及相关文献,一种被称为打包与封装 (PNP) 的方法显得尤为合适。PNP 技术能够将不同图片来源的多个片段整合到一个序列中,正如图10所展示的那样。这种方法借鉴了自然语言处理中对变长输入进行高效训练的示例打包技术,通过舍弃部分词元来适应输入长度的变化。在压缩网络中,首先要完成的是片段化和词元嵌入步骤,而 Sora 也可能进一步将这些潜码特征片段化,以适配扩散变换器的词元,如同扩散变换器本身的操作。无论是否进行第二次片段化,我们都需要解决如何高效打包这些词元,并控制哪些词元应当被舍弃的问题。对于高效打包的问题,采用了一种简单的贪心算法,该算法将示例尽可能地填充到第一个有空间的序列中,直到没有更多示例可以加入。随后,序列会被填充词元补齐,以满足批处理操作所需的固定序列长度。这种打包方式可能会因为输入长度的分布而产生大量的填充。为了解决这一点,我们可以通过调整序列长度和控制采样的分辨率与帧数来优化打包效率,减少填充的需要。对于舍弃词元的策略,一种直观的做法是去除相似的词元,或者采用像 PNP 那样的丢弃率调度策略。但值得一提的是,保持 3D 一致性是 Sora 的一个优势,过度舍弃词元可能会使我们在训练过程中忽视到一些细微的特征。
因此,我们认为 OpenAI 可能采用了一个极长的处理窗口来整合视频中所有的信息片段(Token),虽然这样的处理方式计算成本高昂。这主要是因为多头注意力机制在处理时,其计算成本会随着处理序列的长度增加而呈二次方增长【45,46】。具体而言,长视频中提取的时空潜码片段(Spacetime
Latent Patches)可以被组织在一个序列中,而多个短视频的信息则被串联组合在另一序列中。
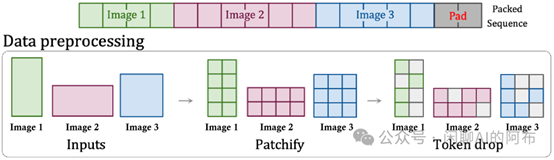
图 10:通过片段打包技术,可以使不同分辨率的图像或视频维持其原始的宽高比。此外,有时候删减信息片段(Token)也可以作为一种数据增强手段。
3.2.5 讨论
我们探讨了 Sora 可能采用的两种数据预处理的技术解决方案。这些解决方案都是在片段层面上进行,因为它们在建模时展现出了极好的灵活性和扩展性。不同于以往将视频统一调整大小、裁剪或修剪的方法,Sora 保留视频的原始尺寸进行训练。虽然这样做有其优势(详见第3.2.1节的分析),但也面临一些技术挑战,其中最主要的是神经网络难以直接处理不同长度、分辨率和宽高比的视觉数据。通过技术分析,我们认为 Sora 首先将视觉片段压缩成低维度的隐藏表示,然后将这些表示或进一步处理的片段以序列形式组织起来,并在输入到扩散变换器之前,对这些隐藏片段添加噪声。Sora 采用的时空片段化方法简单实用,它有效减少了需要处理的信息量,并降低了处理时间序列信息的复杂度。
对研究界而言,我们建议寻找成本效益高的视频压缩和表现形式的替代方案。这包括使用预训练模型(如压缩网络)[47],缩短处理的时间窗口,采用轻量级的建模方法,如分组多查询注意力[48, 49]或高效的结构(如 Mamba
[50]),必要时降低数据采样率和减少处理的数据量。在视频建模中寻找效果和效率的平衡是一个值得深入探讨的课题。
3.2.6 扩散变换器
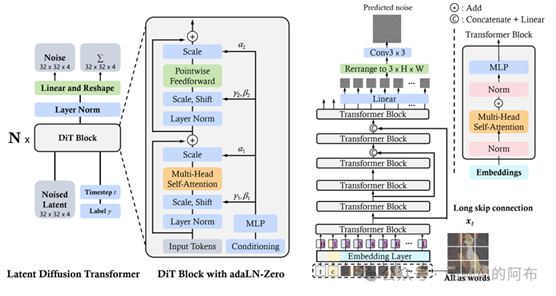
图 11:DiT(左)和 U-ViT(右)的总体框架
3.3 模型构建
图像扩散变换器介绍。传统的扩散模型【51-53】主要依赖于包括降低和提高图像分辨率的处理块的卷积U-Net架构,作为其去噪网络的核心。然而,最新的研究表明,U-Net架构并非扩散模型优异性能的唯一关键。通过引入更加灵活的Transformer架构,基于Transformer的扩散模型能够处理更多的训练数据并支持更大的模型参数。在这方面,DiT【4】和U-ViT【54】是首批采用视觉Transformer技术构建潜码扩散模型的先行者。与ViT类似,DiT采用了多头自注意力机制和逐点前馈网络,并在其中加入了层归一化和缩放层。更进一步,如图11所示,DiT还通过自适应层归一化技术(AdaLN)和一个额外的MLP层来引入条件变量,这种设计使得每个残差块从身份函数开始,大大增强了训练的稳定性。DiT的灵活性和扩展性已经得到了验证,成为扩散模型的新标杆。而在U-ViT中,如图11所展示,研究人员将时间、条件和噪声图像片段都作为输入元素,并在Transformer的浅层和深层之间建立了长距离的跳跃连接。这一发现表明,在基于CNN的U-Net中,降低和提高分辨率的步骤并非总是必需的,U-ViT在图像及文本到图像转换任务中创下了新的FID分数记录。
如掩码自编码器 (MAE) [33]所展示,掩码扩散变换器 (MDT) [55]通过在扩散过程中加入掩码潜码模型,有效地增强了图像合成中各对象语义部分间的上下文关联学习。特别地,正如图12显示的,MDT 在训练阶段采用了一种辅助的掩码令牌重建任务,通过侧向插值技术,不仅提升了训练效率,还学习到了强大的上下文感知位置嵌入,以便于推理时使用。与 DiT [4]相比,MDT 展现了更优的性能和更快的学习速度。不同于采用 AdaLN 进行时间条件建模的方法,Hatamizadeh 等人[56]引入的扩散视觉变换器 (DiffiT) 利用了一个随时间变化的自注意力 (TMSA) 模块,以模拟各个采样时间点上的动态去噪过程。此外,DiffiT 还采用了两种混合层次的架构,分别针对像素空间和潜码空间实现了高效的去噪,从而在多项生成任务中取得了前所未有的成绩。总的来说,这些研究成功地利用视觉变换器处理图像潜码扩散问题,为未来探索其他模态的研究提供了新的思路。
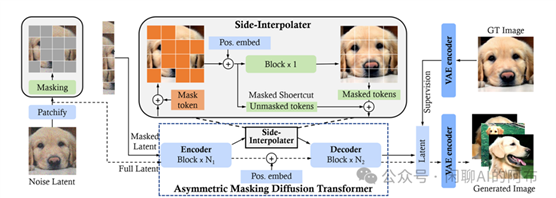
图 12: 掩码扩散变换器 (MDT) 的整体架构图。图中实线和虚线分别代表了训练和推理阶段的每一步操作。训练时使用的掩码和边缘插值技术在推理时会被去除。
视频扩散转换技术。基于文本到图像转换(T2I)扩散模型的基础性研究,近期研究主要致力于探索扩散转换器在文本到视频生成(T2V)任务中的应用潜力。视频的时空特性给 DiTs 在视频领域的应用带来了三大挑战:一是如何在空间和时间上有效压缩视频到潜码空间进行高效去噪;二是如何将这些压缩后的潜码信息转换成小块(patches)并输入到变换器中;三是如何处理视频长期的时空依赖性并保证内容连贯性。关于第一个挑战的详细讨论,请参见第3.2.3 节。本节我们将重点讨论那些设计用于在时空压缩的潜码空间内工作的基于变换器的去噪网络架构,并详细评述了 OpenAI Sora 技术报告参考文献中提到的两个重要成果——Imagen Video [29] 和 Video
LDM [36]。
Imagen Video 29,谷歌研究推出的这款创新文本到视频转换系统,通过一个复杂的模型级联流程,包括7个子模型,来实现从文本到高清视频的转换。这个流程首先通过一个固定的 T5 文本编码器,将文本提示转化为深层次的上下文信息,这一步对于确保视频内容与文本指令紧密对应非常关键。然后,这些深层信息被整合到后续所有处理步骤中,包括基础的视频生成过程。接下来,这个基础模型先产生一个低分辨率的视频,之后再通过一系列精细的模型处理,逐步提升视频的清晰度。
在这个转换过程中,Imagen Video 采用了一种特别的3D U-Net架构,这种设计巧妙地结合了时间和空间处理,以高效捕捉视频帧之间的动态关系。它还运用了一些高级技术,比如稳定数值的 v-预测方法,以及促进不同模型间协同训练的条件增强技术。通过在图像和视频上同时进行训练,每个图像都被视为视频的一帧,这样做能够充分利用大量数据资源。此外,Imagen Video 还采用了无分类器引导和渐进式蒸馏技术,这些技术不仅提高了生成内容的质量,还大大减轻了计算负担,保持了视频的高感知质量。

图 13 展示了 Imagen Video 的整体框架,它的设计和实现体现了高度的创新性和复杂性,能够生成各种风格、高度可控的高质量视频内容,包括多样的视频、文本动画和艺术风格的内容。
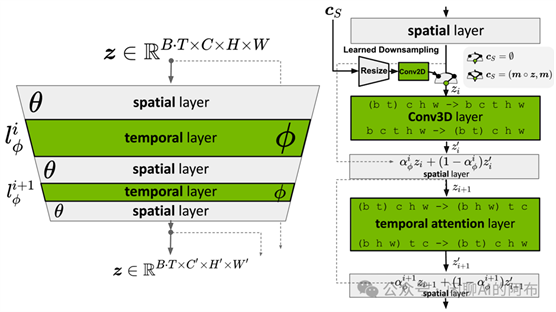
(a) 在视频生成过程中,一个额外的时间层被添加到预训练的模型中,这一层专门负责学习如何将单独的帧整合成一个时间上连贯的序列。在这个过程中,模型的主体结构保持不变,只有这个时间层的参数进行调整和优化,以实现更精准的帧对齐。
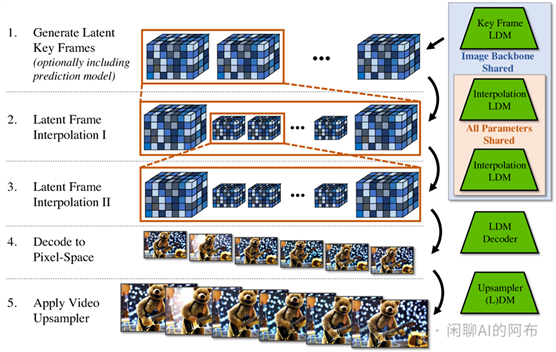
(b)视频潜码扩散模型(LDM)技术。视频 LDM 技术首先创建几个重要但数量不多的关键帧,接着使用同一种潜码扩散模型进行两次时间上的细致插值处理,从而实现视频的高帧率展现。在此过程的最后一步,将这些潜码的视频内容转换回清晰的像素画面,并可以选择性地使用一个专门的视频画质提升模型进行进一步的优化。
图 14: 视频 LDM 的整体架构示意图。来源:视频 LDM [36]。
Blattmann 和团队 [36] 提出了一个创新思路:将传统的二维潜码扩散模型改进为能处理视频内容的视频潜码扩散模型。他们通过在 U-Net 结构的基础上和 VAE 解码器中增加特定的时间处理层来实现这一目标,这些层专门用来整合和对齐视频帧。这种时间层针对编码后的视频数据进行训练,而空间处理层则保持不变,这样做能够有效利用大规模的图像数据集进行预训练。通过对 LDM 解码器进行微调,增强其在时间上的连贯性和空间分辨率,从而能够产生空间细节更丰富、时间上更为一致的视频效果。此外,为了生成长度更长的视频,研究团队设计了一种基于上下文帧预测未来帧的训练方式,使得视频在生成过程中不需要分类器的引导也能保持高质量。视频的高时间分辨率是通过首先生成关键帧然后在关键帧之间进行插值来实现的。采用这种分步骤的方法,最终通过扩散模型将视频内容的空间分辨率提高了四倍,既保证了画面的高清晰度也保持了时间上的流畅性。这种方法不仅提高了视频生成的全局连贯性,而且大幅提升了计算效率。此外,该团队还成功地将已经训练好的图像 LDM(例如 Stable Diffusion)转换为能够生成文本到视频内容的模型,仅通过对时间对齐层的训练,就实现了最高达到 1280 × 2048 分辨率的视频合成能力。
3.3.2 讨论
空间与时间细化的级联扩散模型。Sora 能够制作高清视频。通过研究现有的文献和对 Sora 进行逆向工程分析,我们推测它采用了一种特殊的模型架构,称为级联扩散模型[59]。这种架构包括一个基本模型和多个用于细化空间和时间的模型。在这个体系中,基础模型和低分辨率模型可能不会大量使用注意力机制,因为在处理高分辨率视频时,注意力机制的计算成本高且性能提升有限。为了保证视频和场景在空间和时间上的连贯性,Sora 更注重时间连贯性而非空间连贯性,因为研究显示时间连贯性对视频或场景的生成更为关键。因此,Sora 可能采用了一种高效的训练策略,使用时间较长但分辨率较低的视频来实现时间上的连贯性。此外,考虑到其优越的性能,Sora 可能使用了一种特殊的
v-参数化扩散模型[58],这种模型在预测原始潜码变量x或噪声ϵ方面比其他模型更为出色。
关于潜编码器的思考。为了提高训练效率,许多现有的研究选择使用预训练的稳定扩散 VAE 编码器[60, 61]作为模型训练的起点。但这些编码器缺少处理视频时间信息的能力。尽管有研究建议仅微调解码器来处理时间信息,但解码器在处理压缩潜码空间中的视频时间数据时,性能仍然不尽人意。根据技术报告,我们的分析表明,与其使用预训练的 VAE 编码器,Sora 更可能采用从头开始训练的空间-时间 VAE 编码器,这种编码器针对视频数据进行优化,其性能超越了现有技术,特别是在处理视频压缩潜码空间方面。
3.4 跟随语言指令
用户通常通过输入自然语言的指令来与生成式 AI 模型互动,这些指令也就是我们所说的文本提示 [62,63]。为了让 AI 模型更准确地理解并执行这些文本指令,研究人员开展了模型指令优化的工作。这种优化让模型在处理文本查询时能够生成更贴近人类自然反应的回答。我们的讨论从大语言模型(LLMs)及 DALL·E 3 这样的文本到图像模型开始,探讨它们是如何通过技术进步来更好地理解和执行指令的。Sora 在提升文本到视频模型理解文本指令的能力方面,采取了与 DALL·E
3 相似的策略,通过训练一个专门的描述性字幕制作器,并利用其生成的数据来进行模型的微调。这样的优化让 Sora 能够精准地响应各种用户需求,无论是对指令细节的精确捕捉,还是生成完全符合用户预期的视频。
3.4.1 大语言模型
大语言模型在理解并执行指令方面的能力得到了深入研究 [64,65,66]。这项能力使得大语言模型能够阅读、理解并恰当地回应那些描述着尚未遇到的任务的指令,而且这一切都无需给出示例。通过在一系列以指令形式呈现的任务上进行微调,大语言模型不仅学会了如何跟随指令,还在处理未曾遇见的任务上表现出了卓越的能力。Wei 等人的研究 [65] 表明,经过这种指令优化的大语言模型在处理新任务时,其性能远超那些未经优化的模型。这种跟随指令的能力标志着 AI 发展进入了一个全新的阶段,大语言模型现在已经成为了可以处理各种任务的通用解决方案。
3.4.2 文字转图片
DALL·E 3 所采用的策略基于一个核心假设:模型训练所用的文本-图片对质量直接影响到最终生成的文字到图片模型的表现 [67]。数据质量低下,尤其是充斥着的噪声数据和缺少大量视觉信息的简短标题,会引起诸如忽略关键词、混淆词序以及误解用户意图等一系列问题 [21]。为了解决这些问题,提出了一种通过为现有图片重新编写更详尽描述性的标题的方法。该过程首先是训练一个能生成精确描述性图像标题的视觉-语言模型。随后,这些生成的描述性图像标题被用于微调文字到图片模型。具体而言,DALL·E 3 采用了一种称为对比字幕器(CoCa)的方法 [68],该方法将一个图像字幕器和语言模型目标进行联合训练,该字幕器基于 CLIP 架构 [26]。这个系统包括了图像编码器、用于提取语言信息的单模态文本编码器和多模态文本解码器。它首先使用图像与文本单模态嵌入间的对比损失,然后是多模态解码器输出的字幕生成损失。在经过微调后,图像字幕器能够根据包括主要物体、环境、背景、文字、风格和颜色等细节描述生成详细的图像标题。文字到图片模型的训练数据集是由这种重新标注的数据集与真实的人类编写数据混合构成的,确保了模型能准确捕捉用户意图。这种图像标题改进方法可能会引入实际用户指令与训练数据中描述性图像描述不匹配的问题。DALL·E 3 通过一种称为“上采样”的技术解决这一问题,即利用大语言模型 (LLMs)
将简短的用户指令扩展成更为详细和长篇的指导,保证了模型在推理时接收到的文本输入与训练期间的输入一致。
3.4.3 从文字到视频
为了提升模型按照指令执行的能力,Sora 采取了一种提升视频描述能力的方法。这个过程首先是训练一个视频描述生成器,该生成器能够为视频创建详尽的描述。接着,把这个生成器用于训练集中的所有视频,生成高质量的视频及其描述性字幕对,用这些数据对 Sora 进行微调(fine-tune),以增强它的指令理解和执行能力。
Sora 的技术报告 [3] 没有详细说明视频描述生成器的训练细节。考虑到该生成器是一个将视频转换为文字的模型,构建这种模型的方法有很多种。一个简单的方法是使用 CoCa 架构来进行视频描述,即抓取视频的多帧,并将每帧独立输入图像编码器 [68],这一过程称为
VideoCoCa [69]。VideoCoCa 在 CoCa 的基础上,重用了图像编码器的预训练权重,并将其独立应用于选取的视频帧上。这些帧的嵌入表示被平整化后串联成一个长视频表示序列。然后,这些序列通过生成式池化器和对比池化器进行处理,这两种池化器通过对比损失和描述生成损失共同训练。构建视频描述生成器的其他方法还包括 mPLUG-2 [70]、GIT [71]、FrozenBiLM [72] 等。最后,为了确保用户的输入与训练数据中的描述性字幕格式一致,Sora 还进行了一步额外的输入扩展操作,通过 GPT-4V 把用户的简短输入扩充为更详细的描述性提示。
3.4.4 讨论
Sora 能够根据用户的指令创造出长达一分钟、场景复杂且符合用户意图的视频,这种指令执行能力至关重要。Sora 的技术报告 [3] 透露,这一能力是通过开发一个能生成详尽字幕的系统获得的,这些详尽的字幕随后被用来训练模型。但是,如何收集用于训练此系统的数据仍是一个谜,这个过程可能非常耗时,因为它需要对视频内容进行详细的描述。此外,视频描述系统有时可能会错误地添加视频中并不存在的细节。我们认为,改进视频描述系统,以更好地遵循指令,是一个值得进一步探究的关键问题。
3.5 提示工程
所谓提示工程,是指为了达到特定目标或优化结果而对 AI 系统输入内容的设计与优化过程,尤其适用于生成模型领域 [73, 74, 75]。提示工程既是一门艺术也是一门科学,它通过巧妙设计输入,引导模型生成更准确、相关且逻辑连贯的回应。
3.5.1 文本提示技巧
在将文本转换为视频的过程中,文本提示的设计至关重要,它能够指导模型(如 Sora [3])创造出既符合用户需求又视觉上引人注目的视频。这一过程包括精心编写详细的描述,以便模型能够有效地将人类的创意思维和AI的执行力结合起来[76]。Sora 的文本提示覆盖了多种情境。近期的研究,如 VoP [77]、Make-A-Video [28]以及 Tune-A-Video [78],展示了文本提示如何利用模型对自然语言的理解能力,将复杂的指令转化为连贯、生动且高质量的视频故事。正如图15中展示的,“一位穿着时尚,在东京灯火辉煌的街道上漫步的女性……”这样一个精心设计的文本提示,确保了 Sora 能够制作出与期望视觉完美契合的视频。优秀的文本提示设计在于精确选择每一个词汇、详细说明每一个细节,以及深刻理解这些因素如何影响模型的最终输出。

图 15: 一个关于如何通过文本提示在文本到视频转换中进行创意设计的案例研究,使用颜色代码明确区分创作过程。蓝色高亮部分描述了 Sora 生成的元素,如展现一位时尚女性的形象;而黄色部分则强调了模型如何解释动作、场景和角色造型,展示了一个精心构思的文本提示是如何被转化为一段生动、充满动感的视频故事的。
3.5.2 图像提示
图像提示为视频创作提供了一种视觉基准,让即将制作的视频内容、角色、场景和氛围等元素得以具象化[79]。通过结合文本提示,模型能够为这些静态元素注入生命,比如添加运动效果、互动和故事发展等,使图像变得生动[27,80,81]。利用图像提示,Sora 能够将静态图片转化为充满故事性的动态视频,这一过程中既利用了视觉信息也利用了文本信息。在图16中,我们展现了几个示例,包括“一个戴贝雷帽和高领衫的柴犬”、“一个别致的怪物家族”、“形成‘SORA’字样的云朵”和“冲浪者在古老大厅中驾驭巨浪”。这些示例充分展示了,通过向 Sora 提供 DALL·E 生成的图像作为启发,可以创造出何种水平的视频内容。
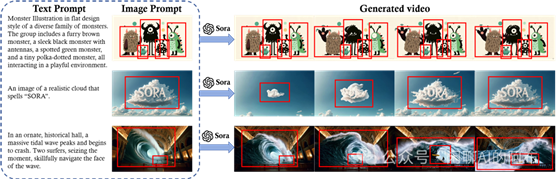
图 16: 这个示例展示了图像提示是如何指引 Sora 的文本到视频模型创造出视频的。红色框体突出显示了每个场景的核心元素——多样化设计的怪物、拼成“SORA”的云朵,以及在装饰华丽的大厅中面对巨大潮浪的冲浪者。
3.5.3 视频提示技巧
视频提示技术已被证明可以用于创造视频内容,如文献82和83所展示。近期的研究,如 Moonshot 84和 Fast-Vid2Vid 85,表明有效的视频提示既要具体又要灵活。这样不仅可以确保模型明确了解到具体的创作目标,比如要展示的特定物体和视觉风格,还能在最终的视频作品中加入创新的变化。例如,在视频扩展任务中,可以通过提示来指明视频展开的方向(时间向前还是向后)以及内容的主题或背景。如图17(a) 所示,通过视频提示,可以让 Sora 将视频向后延伸,探索起始点之前发生的事件。在使用视频提示进行视频编辑时,正如图17(b) 所展示的那样,模型需要清晰地识别出需要的改变,无论是视频的风格、场景设置还是氛围的变化,或是像灯光或情绪这样的细节调整。在图17(c) 中,提示引导 Sora 将不同的视频片段连接起来,并确保视频中不同场景的物体之间能够平滑过渡。
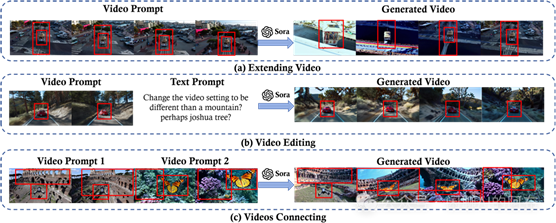
图 17: 这些示例展示了对 Sora 模型使用视频提示技巧的几种方式:(a) 视频扩展,模型将视频序列向原始片段的相反方向推进,(b) 视频编辑,根据文本提示对视频中的特定元素,比如场景进行改变,以及 (c) 视频连接,通过两个不同的视频提示将视频片段无缝结合,创造出一个连贯的故事。每个步骤都受到一个视觉焦点的引导,用红色框标出,保证视频内容的连贯性和准确性。
3.5.4 讨论
通过巧妙设计提示,我们可以引导 AI 模型创造出符合用户意愿的内容。以 Sora 为例,它通过结合文本、图片和视频的提示,不仅能创作出吸引眼球的内容,还能精准捕捉用户的期望和意图。尽管之前的研究主要关注文本和图片的提示技术,特别是在大语言模型和大视觉模型的应用上,我们预计未来视频提示在视频内容生成领域将会受到越来越多的关注。
3.6 可信性
随着 ChatGPT、GPT4-V 和 Sora 等高级模型的快速进步,它们的功能已经得到了极大的增强,为提高工作效率和促进技术革新作出了显著贡献。但是,这些进步同时也带来了一系列问题,如假新闻的产生、隐私泄漏以及伦理道德的挑战。因此,如何确保这些强大的模型可靠且不被滥用,已经成为了学术界和产业界共同关注的重点议题。
3.6.1 安全问题
模型的安全性是一个重点关注领域,特别是其在面对误用和“越狱”攻击的抵抗能力方面。越狱攻击指用户尝试通过漏洞生成违禁或有害内容的行为 [96, 97, 98, 99, 100, 101, 102, 103, 104, 105]。例如,引入了AutoDAN [103],这是一种基于梯度技巧的创新且易于理解的对抗性攻击方式,用于实现对系统的绕过。近期研究发现,大语言模型 (LLM) 在抵御越狱攻击时面临的两大挑战包括目标不一致和泛化能力不匹配 [106]。除了文本攻击,对于多模态模型(如 GPT-4V
[90] 和
Sora [3])来说,视觉越狱同样构成安全威胁。最近的一项研究 [107] 发现,由于额外的视觉输入的连续和高维特性,大型多模态模型对对抗性攻击更加敏感,这增加了潜码的攻击范围。
3.6.2 其他利用问题
鉴于大型基础模型(如 ChatGPT [89] 和 Sora [3])在训练数据集的规模和方法上的先进性,提升这些模型的真实性变得尤为重要,尤其是面对广泛讨论的诸如“虚假输出”等相关问题 [108]。“虚假输出”在此背景下,指的是模型生成的回答可能听起来令人信服,但实际上是没有依据或是错误的 [96]。这一现象对模型输出的可靠性和信赖度提出了挑战,迫切需要采取全面措施来评价并解决此问题。已有大量研究致力于从多角度探讨“虚假输出”问题,包括评估不同模型和场景下“虚假输出”的范围和本质 [109, 96, 110, 111]。这些评估为理解“虚假输出”发生的原因和方式提供了重要见解,为制定减少其发生策略奠定了基础。与此同时,目前大量研究正集中于发展和实施减少大模型中“虚假输出”发生的方法 [112, 113, 114]。
公平性与偏差问题是建立信任的另一核心要素。开发既不传递也不加剧社会偏见的模型至关重要,因为这些模型中的偏差会加深社会不平等,导致不公平的结果。正如 Gallegos 等人 [115],Zhang 等人 [116],Liang 等人 [117],和 Friedrich 等人 [118] 的研究所展示,致力于精确识别和消除这些偏差。目标是开发出公正的模型,平等对待每一个人,不论种族、性别或其他敏感因素。这不仅需要识别和减少数据集中的偏差,还需要设计能够积极阻止偏差扩散的算法 [119, 120]。
随着这些模型的部署,数据隐私保护成为一个基础性的支柱。在对数据隐私日益关注的今天,保护用户信息的重要性前所未有。随着公众对个人数据处理方式越来越关心,大模型的评估变得更加严格,这些评估着重于确保个人信息的安全,避免不小心泄露信息。Mireshghallah 等人 [121],Plant 等人 [122],和 Li 等人 [123] 的工作,推动了保护隐私技术和方法的发展。
3.6.3 模型对齐
在应对这些挑战的过程中,确保大型模型值得信赖已成为研究者们格外关注的一个核心问题 [124, 96, 99, 125]。模型对齐技术是其中极为关键的一环 [125, 126],它旨在确保模型的行为和产出能够符合人类设计者的初衷和伦理规范。这不仅涉及技术开发本身,还包括其所承担的道德责任和反映的社会价值。在大语言模型的研究领域里,结合了强化学习和直接人类反馈的“以人类反馈为导向的强化学习”(RLHF)方法 [127, 128] 已被广泛采用来实现模型对齐。通过这种方法,模型能够更精准地根据人类的预期和标准来理解和完成任务。
3.6.4 讨论
通过分析 Sora 的技术报告,我们发现了几个深具启示性的观点,这些观点对于指导未来的研究方向具有重要价值:
(1) 模型与外部防护的全面保障:随着生成型模型的能力日益增强,如何避免它们被滥用生成有害内容,比如仇恨言论[129]和虚假信息[92,91],成为了一大挑战。除了加强模型自身的道德约束,外部的安全防护措施同样不容忽视,包括内容过滤、审查机制、使用许可与访问控制、数据隐私保护以及提升透明度和可解释性等。例如,OpenAI 利用检测分类器来判断视频是否由 Sora 生成[130],并部署文本分类器来识别可能的有害文本输入[130]。
(2) 多模态模型面临的安全难题:Sora 这样的文本到视频模型引入了新的安全挑战,由于它们能够处理和生成多种类型的内容(如文本、图片、视频等),这不仅增加了滥用的途径,也带来了版权问题。由于这些模型生成的内容更加复杂多元,传
统的内容验证方法可能不再适用,这就需要我们开发新的技术和方法来鉴别和过滤有害内容,提高监管和管理的难度。
(3) 需要跨领域的合作:确保模型安全并非仅是技术层面的问题,它还需要法律[131]、心理学[132]等多个学科领域的专家共同努力,以形成共识(比如,什么是安全的,什么是不安全的)、制定政策和开发技术解决方案。这种跨学科的合作极大地增加了解决这些安全问题的复杂度。
4 应用领域
随着 Sora 这类视频扩散模型成为尖端技术,它们在各个研究领域和行业的应用正迅速扩展。这项技术的潜力远不止于视频制作,它还能在自动化内容生成、复杂决策过程等任务中发挥变革性作用。本节我们将深入探索视频扩散模型当前的应用情况,并重点介绍 Sora 如何不仅展现了其强大能力,而且彻底改变了我们解决复杂问题的方式。我们旨在展现这些技术在实际应用场景中的广泛前景(参见图18)。
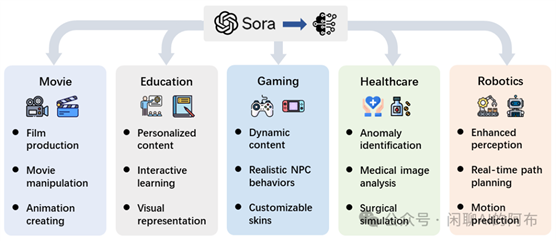
图 18: Sora 的应用案例。
4.1 电影产业
传统电影制作是一个费时费力且成本高昂的过程,往往需要几十年的时间、先进设备和巨额投资。但现在,随着高级视频生成技术的出现,电影制作迎来了新纪元:通过简单的文本输入就能自动生成电影,这一梦想正在成为现实。研究人员利用视频生成模型拓展到电影制作领域,开创了电影生成的新篇章。例如,MovieFactory [133] 利用扩散模型根据 ChatGPT [89] 生成的精细剧本生成电影风格的视频,标志着技术上的一大进步。随后,MobileVidFactory [134] 能够仅凭用户提供的简文本自动创作竖屏移动视频。Vlogger [135] 让用户能以此技术创作出一分钟长的视频日志。Sora 轻松生成吸引人电影内容的能力,预示着电影制作民主化的新时代。这展现了一个未来景象,任何人都有机会成为电影制作人,极大降低了进入电影界的门槛,并引入了一种新的电影制作维度,将传统叙述与 AI 驱动的创意完美融合。这些技术不仅简化了电影制作过程,还有望彻底改变电影制作领域的面貌,使其更加开放、多样化,更好地适应观众不断变化的偏好和分发渠道的发展。
4.2 教育革新
长期以来,教育领域的内容主要由静态资源构成,虽然这些资源具有一定的价值,但它们往往无法满足当前学生的多元化需求和学习方式。视频扩散模型作为教育革命的先锋,开创了定制化和活化教育材料的新篇章,极大地提高了学习者的参与度和理解能力。这些尖端技术让教育工作者能够把文字描述或课程大纲转换成充满活力、吸引人的视频内容,这些内容根据每个学生的独特风格和兴趣量身定制 [参考资料: 136,137,138,139]。此外,图像至视频的编辑技巧 [参考资料: 140,141,142] 为将静态教育资源变为互动视频提供了创新方法,满足了各种学习偏好,有望进一步提升学生的参与感。将这些模型融入教育内容的创作中,教师们可以就各种主题制作视频,让复杂的概念变得更加通俗易懂,为学生们带来吸引力。使用 Sora 来颠覆传统教育领域,展现了这些技术改变游戏规则的潜力。这种向个性化、动态教育内容的转变,标志着教育领域新纪元的到来。
4.3 游戏行业
游戏产业始终在寻找方法,以突破真实感和沉浸体验的边界。然而,传统的游戏开发往往受限于预设的环境和剧本事件。现在,利用扩散模型实时生成的动态高清视频内容和逼真音效,有望突破这些限制。这为游戏开发者们开辟了新天地,使他们能够创造出随玩家行为和游戏事件自然变化的游戏环境 [143, 144]。这包括能够即时生成变化的天气、变幻的景观,乃至于创造全新的游戏场景,让游戏世界变得更加生动和反应灵敏。有些技术 [145, 146] 还能根据视频输入生成真实的碰撞声音,提升游戏的音效体验。整合了 Sora 技术的游戏领域,能够创造出前所未有的沉浸式体验,极大地吸引玩家。这不仅将改变游戏的开发和玩法方式,还将开启讲故事、互动和沉浸体验的新篇章。
4.4 医疗保健
在医疗保健领域,尽管主要强调创造能力,视频扩散模型在理解和生成复杂视频序列方面的能力,使其特别适合于识别身体内部的动态变化,如细胞早期的自我消亡、皮肤病变的发展以及不规则的人体运动 [147, 148, 149]。这对早期发现疾病并采取干预措施至关重要。此外,像 MedSegDiff-V2 这样的模型 [150, 151] 利用变换器技术,以空前的精确度进行医学图像分割,使医生可以更准确地识别出各种成像技术中的关键区域。通过将 Sora 技术融入临床实践,不仅可以优化诊断流程,还可以根据精确的医学成像分析,为患者提供定制化的治疗方案。然而,技术的融合也带来了挑战,包括必须建立强有力的数据隐私保护措施,并在医疗实践中考虑伦理问题。
4.5 机器人
在机器人领域,视频扩散模型正开启一个新篇章,它们不仅能创造和理解复杂的视频内容,从而极大地提升机器人的感知能力[152, 153],还能够在决策制定上发挥关键作用[154-156]。这项技术让机器人拥有了前所未有的互动及执行复杂任务的能力。通过引入大规模的扩散模型,我们看到了机器人视觉和理解能力的巨大提升潜力[152]。例如,现在的机器人可以通过“潜码扩散模型”接收语言指令来预测视频中的动作结果,这意味着它们能够更好地理解和完成任务[157]。此外,利用视频扩散模型创造出的高度逼真的视频序列,解决了机器人研究依赖模拟环境的局限性,为机器人提供了丰富多样的训练场景,克服了真实世界数据不足的问题[158, 159]。我们认为,将像 Sora 这样的尖端技术融入机器人学,将会带来革命性的进展。利用 Sora 的强大功能,机器人学的未来将实现空前的飞跃,使得机器人能够更自然地与周围环境互动和导航。
5 讨论
Sora 展现了其对人类复杂指令的精确理解和执行能力,特别擅长创作设置在精心布置的场景中、涵盖多种角色的细节丰富的视频。其最引人注目的特点之一是能够生成长达一分钟的视频,并保持始终如一且吸引人的叙事。这在先前主要关注制作更短视频的尝试中是一个重大进步,因为 Sora 的视频不仅叙事流畅,还能从头到尾维持视觉连贯性。此外,Sora 能创造出描绘复杂动作和互动的长视频,突破了早期模型仅能处理短视频和基础图像的局限。这一进展是 AI 驱动创意工具的一大飞跃,让用户有能力将文本故事转换为具有前所未有的细节和复杂度的生动视频。
5.1 局限性
面对物理真实性的挑战,Sora 作为一个仿真平台,在准确再现复杂情境方面存在一些局限。其中最显著的问题是它在处理复杂场景时对物理规则的应用不一致,有时候无法准确模拟出因果关系的特定例子。比如,吃掉一块饼干可能不会留下明显的咬痕,这种情况反映了系统偶尔会偏离物理的合理性。这一问题也影响到了运动的模拟,Sora 在模拟运动时,有时会产生与现实物理不符的动作,比如物体的不自然变形或是椅子这类刚体结构的不正确模拟,导致了不现实的物理互动。在模拟物体和角色之间复杂的相互作用时,问题更加明显,偶尔还会产生一些更倾向于幽默的结果。
空间和时间方面的复杂性也是一个挑战。Sora 有时会误解有关物体和角色在场景中的放置或排列的指令,造成方向上的混淆(比如将左和右弄反)。同时,它在维持事件发生的时间顺序上也面临挑战,尤其是在遵循特定的摄影机移动或场景顺序时,可能会偏离原计划的时间线。在涉及许多角色或元素的复杂场景中,Sora 偶尔会加入一些与场景无关的动物或人物,这种情况可能会大幅改变场景原本的设想和氛围,偏离预定的叙事或视觉布局。这不仅影响了模型再现特定场景或叙事的准确性,也影响了其产出内容与用户期望及内容连贯性紧密对齐的可靠性。
在人机交互(HCI)方面,尽管Sora 在视频生成领域展现了潜力,但它在 HCI 方面存在显著的限制。这些限制主要体现在用户与系统交互的连贯性和效率上,尤其是在对生成的内容进行详细的修改或优化时。例如,用户可能难以精确地指定或调整视频中特定元素的展示,如动作的细节和场景的过渡。此外,Sora 在理解复杂的语言指令或把握细微的语义差异方面也显示出限制,可能导致视频内容无法完全满足用户的期望或需求。这些问题限制了 Sora 在视频编辑和增强方面的应用潜力,也影响了用户体验的总体满意度。
使用限制方面,OpenAI 对公众开放 Sora 的具体上线时间持谨慎态度,强调在进行广泛推广前,需要确保安全性和准备工作充分。这意味着,在安全、隐私保护及内容审查等方面,Sora 还需经过进一步的完善和测试。目前,Sora 生成的视频最长只能达到一分钟,根据已发布案例,多数视频仅有数十秒的长度。这一局限性使其难以应用于需要展示较长内容的场合,如详尽的教程视频或深入的故事讲述,从而影响了 Sora 在内容创作上的灵活度。
5.2 机遇
在学术界,OpenAI 推出 Sora 是向着鼓励AI社区更深层次探索文本到视频模型、并利用扩散及变换器技术的战略转型的一大步。此举意在引导关注点转向利用文本描述直接创造出复杂细腻视频内容的潜能,这一领域的探索预示着内容创作、叙事及信息共享方式的革命性变革。此外,Sora 在其原生尺寸数据上的训练方法,与传统的缩放或裁剪相比,为学术界提供了新的启示,突出了使用未修改数据集的优势,为生成更先进模型铺平了道路。
在行业方面,Sora 目前的能力展现了视频仿真技术发展的广阔前景,特别是在提高物理及数字领域真实度方面的潜力。通过文本描述能够创造出高度真实环境的能力,为内容创作领域带来了光明的未来,尤其是在游戏开发上,展示了用前所未有的简易度和精准度创造沉浸式世界的可能。此外,企业可以利用 Sora 快速适应市场变化,制作定制化的营销视频,这样不仅可以降低生产成本,还能提升广告的吸引力和效果。Sora 依靠文本描述独自生成高度真实视频的能力,有望彻底变革品牌与观众的互动方式,创造出既吸引人又引人入胜的视频,以新颖的方式展现其产品或服务的核心价值。
社会影响。(1)尽管利用文本转视频技术替代传统电影制作的想法还很遥远,但 Sora 和类似的平台对社交媒体内容创作具有革命性的影响力。现有的视频长度限制并未影响这些工具使高质量视频制作变得普及的潜力,让每个人都能够轻松制作引人入胜的内容,无需依赖昂贵的设备。这标志着内容创作者在 TikTok 和 Reels 等平台上被赋予了更大的权力,开启了创意和参与度的新纪元。(2)编剧和创意人员可以借助 Sora 把书面剧本变为视频,这不仅帮助他们更生动地展示和分享创意想法,还能制作短片和动画。将剧本转化为详细生动的视频,这一能力将彻底改变电影和动画前期制作的过程,预示着未来故事讲述者可能如何推介、发展和精炼他们的故事。这项技术为剧本开发引入了一种更动态、互动的方式,使创意想法可以即时可视化和评估,成为创新和合作的有力工具。(3)记者和新闻机构也可以通过 Sora 快速制作新闻报道或解说视频,让新闻内容更加鲜活和引人关注。这大大提高了新闻报道的传播范围和观众的参与程度。Sora 提供了一种强大的视觉叙事工具,通过模拟真实环境和场景,帮助记者以先前难以实现或成本高昂的视频形式讲述复杂的故事。综上所述,Sora 在推动营销、新闻和娱乐内容创作革命方面拥有巨大的潜力。
结论
我们综合回顾了 Sora,旨在帮助开发者和研究者深入了解其功能和相关研究。这项工作基于我们对已发布技术报告的调研和现有文献的逆向工程。随着 Sora 的 API 开放和更多细节的披露,我们将持续更新这篇论文。我们期待这篇综述能为开源研究社区提供价值,为未来社区共同开发 Sora 的开源版本铺平道路,实现在生成式人工智能(AIGC)时代的视频自动创作民主化。
百度为创作者打造的集创作、发布、变现于一体的内容创作平台