语音克隆又又又又又升级了
发布时间:2024年06月06日
之前在前面的文章中有介绍,克隆你的声音,只需要你三秒的录音,声音克隆又进化了!,时隔几个月Meta又推出了最新的语音生成技术,不仅能可能声音,还能通过对声音的描述来生成独特的音色,同时还能通过描述来生成各种各样的音效,甚至能通过文字描述来编辑声音,整体来说,这项技术几乎囊括了现在人们对语音生成技术的所有的需求。
早在今年6月,Meta曾经推出过VoiceBox,能直接从文本生成高质量语音,不需要任何音频样本作为训练数据,可能是基于对音频Deepfake的担忧,一向秉承开源的Meta并未向工作开放VoiceBox,不过本周一,Meta发布了一个交互式的网站,可以免费体验类似VoiceBox的音频生成器——AudioBox.
音频生成的功能比较多,我们简单体验一下,有兴趣的可以自行前往尝试
Audiobox (metademolab.com)
首先是自己通过文本描述生成一个音频样式。
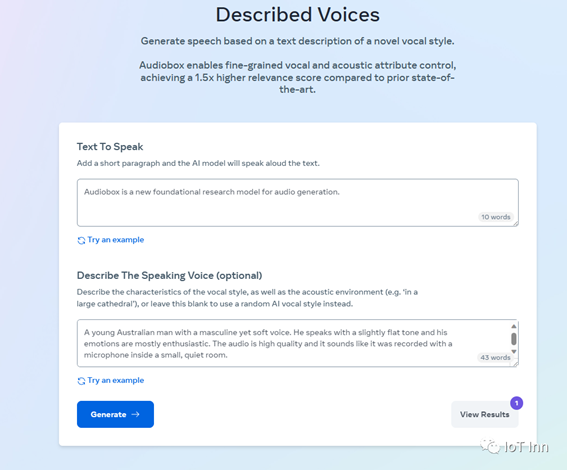
让他生成一个声音的描述如下:
澳大利亚青年,声音阳刚而柔和。他说话的语调略显平淡,情绪大多热情洋溢。音频质量很高,听起来像是在一个安静的小房间里用麦克风录制的。
目前还不支持中文,所以只能解决翻译软件
朗读的结果如下:
 然后是替换声音风格:
然后是替换声音风格:
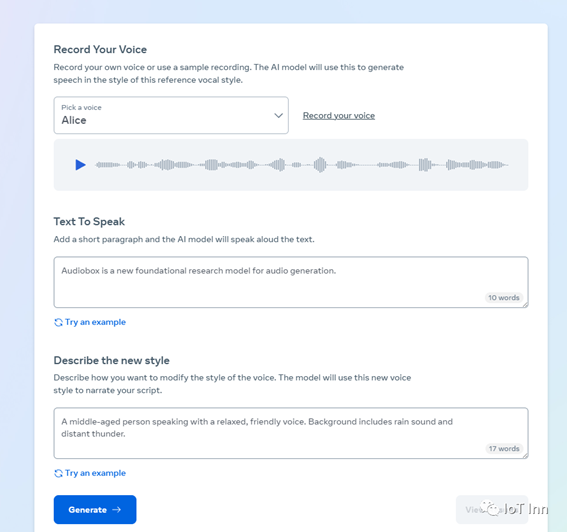
原始音频是系统提供的Alice,然后我们替换成
一位中年男子在说话,声音轻松而亲切。背景包括雨声和远处的雷声。
一位中年人轻松地说,IoT Inn,6秒
人生很逼真,甚至是远处的雷声也是逼真清晰,令人震撼。
最后我们体验一下音效生成,给的音效的描述是:
鸟儿在鸣叫,河水在流淌。
最终的结果:
 除了上述的一些功能,还有魔法擦除功能,可以去除原始音频中的一些杂音或者特殊音频,反过来也可以添加一些音效。
除了上述的一些功能,还有魔法擦除功能,可以去除原始音频中的一些杂音或者特殊音频,反过来也可以添加一些音效。
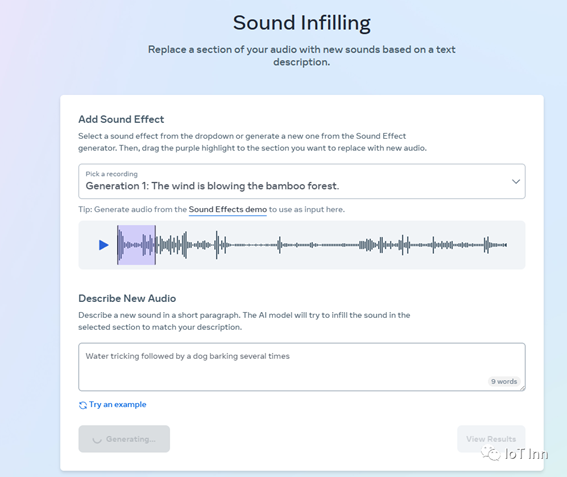
比如我们先生成一段风吹竹林的音频,然后在音频上添加狗叫的音效,可以明显的看到音频发生了变化
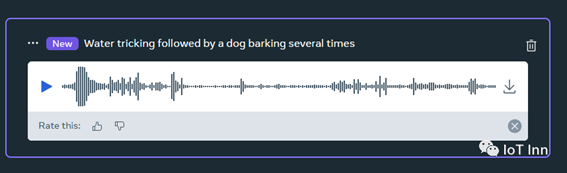
实际效果如下:

与 Voicebox 相比,Audiobox 的生成质量更优。通过「结合使用语音输入和自然语言文本提示」生成语音和声音效果,最大限度提高结果的可控性。另外,和 Voicebox 不同,所有这些音频生成、编辑等功能,都「建立在共享的自监督模型 Audiobox SSL 之上。」
换句话说,通过统一语音和音景的生成和编辑功能,Audiobox
进一步推进了音频的生成 AI 的进步。在安全性上,使用 Audiobox 创建的任何音频都带有自动水印,可以准确地追溯到其来源
希望在不久后,Meta能开源这项技术,让平民也能体会到AI音频的未来。
出自:https://mp.weixin.qq.com/s/HUU6BycWUQ_NSPHJEFwhMg
易撰提供文章检测、爆文分析、数据监测、视频库、热点追踪等功能,如果需要,我们还将为您提供数据定制服务及其它相关联的API接口服务。